









 博客主要介绍了Transformer模型中的位置编码方法,包括Attention is All you Need、Universal transformers等不同类型的位置编码,还阐述了绝对位置编码、相对位置编码、旋转位置嵌入等多种编码方式的原理和特点,为理解Transformer模型的位置编码提供了详细信息。
博客主要介绍了Transformer模型中的位置编码方法,包括Attention is All you Need、Universal transformers等不同类型的位置编码,还阐述了绝对位置编码、相对位置编码、旋转位置嵌入等多种编码方式的原理和特点,为理解Transformer模型的位置编码提供了详细信息。
Position Encodings in Hung-yi Lee
1. Attention is All you Need
p i ( 1 ) [ j ] = { sin ( i ⋅ c j d ) if j is even cos ( i ⋅ c j − 1 d ) if j is odd \boldsymbol{p}_{i}^{(1)}[j]= \begin{cases}\sin \left(i \cdot c^{\frac{j}{d}}\right) & \text { if } j \text { is even } \\ \cos \left(i \cdot c^{\frac{j-1}{d}}\right) & \text { if } j \text { is odd }\end{cases} pi(1)[j]=⎩⎨⎧sin(i⋅cdj)cos(i⋅cdj−1) if j is even if j is odd
2. Universal transformers
P t ∈ R m × d P^{t} \in \mathbb{R}^{m \times d} Pt∈Rm×d above are fixed, constant, two-dimensional (position, time) coordinate embeddings, obtained by computing the sinusoidal position embedding vectors as defined in (Vaswani et al., 2017) for the positions 1 ≤ i ≤ m 1 \leq i \leq m 1≤i≤m and the time-step 1 ≤ t ≤ T 1 \leq t \leq T 1≤t≤T separately for each vector-dimension 1 ≤ j ≤ d 1 \leq j \leq d 1≤j≤d, and summing:
P i , 2 j t = sin ( i / 1000 0 2 j / d ) + sin ( t / 1000 0 2 j / d ) P i , 2 j + 1 t = cos ( i / 1000 0 2 j / d ) + cos ( t / 1000 0 2 j / d ) . \begin{aligned} P_{i, 2 j}^{t} &=\sin \left(i / 10000^{2 j / d}\right)+\sin \left(t / 10000^{2 j / d}\right) \\ P_{i, 2 j+1}^{t} &=\cos \left(i / 10000^{2 j / d}\right)+\cos \left(t / 10000^{2 j / d}\right) . \end{aligned} Pi,2jtPi,2j+1t=sin(i/100002j/d)+sin(t/100002j/d)=cos(i/100002j/d)+cos(t/100002j/d).
or
p
i
(
n
)
[
j
]
=
{
sin
(
i
⋅
c
j
d
)
+
sin
(
n
⋅
c
j
d
)
if
j
is even
cos
(
i
⋅
c
j
−
1
d
)
+
cos
(
n
⋅
c
j
−
1
d
)
if
j
is odd
\boldsymbol{p}_{i}^{(n)}[j]= \begin{cases}\sin \left(i \cdot c^{\frac{j}{d}}\right)+\sin \left(n \cdot c^{\frac{j}{d}}\right) & \text { if } j \text { is even } \\ \cos \left(i \cdot c^{\frac{j-1}{d}}\right)+\cos \left(n \cdot c^{\frac{j-1}{d}}\right) & \text { if } j \text { is odd }\end{cases}
pi(n)[j]=⎩⎨⎧sin(i⋅cdj)+sin(n⋅cdj)cos(i⋅cdj−1)+cos(n⋅cdj−1) if j is even if j is odd
3. Learnable Position Encodings
4. Learning to encode position for transformer with continuous dynamical model
p ( n ) ( t ) = p ( n ) ( s ) + ∫ s t h ( n ) ( τ , p ( n ) ( τ ) ; θ h ( n ) ) d τ \boldsymbol{p}^{(n)}(t)=\boldsymbol{p}^{(n)}(s)+\int_{s}^{t} \boldsymbol{h}^{(n)}\left(\tau, \boldsymbol{p}^{(n)}(\tau) ; \boldsymbol{\theta}_{h}^{(n)}\right) \mathrm{d} \tau p(n)(t)=p(n)(s)+∫sth(n)(τ,p(n)(τ);θh(n))dτ
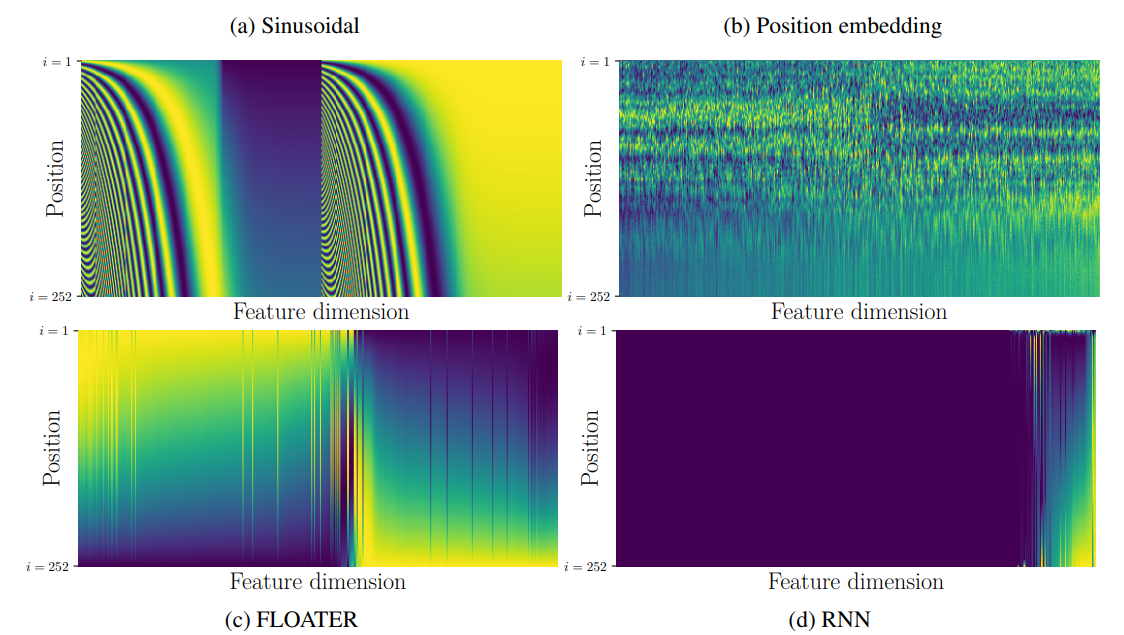
Position Encodings in Papers with Code
1. Absolute Position Encodings
Absolute Position Encodings are a type of position embeddings for [Transformer-based models] where positional encodings are added to the input embeddings at the bottoms of the encoder and decoder stacks. The positional encodings have the same dimension
d
model
d_{\text {model }}
dmodel as the embeddings, so that the two can be summed. In the original implementation, sine and cosine functions of different frequencies are used:
P
E
(
pos
,
2
i
)
=
sin
(
p
o
s
/
1000
0
2
i
/
d
m
o
d
d
)
P
E
(
p
o
s
,
2
i
+
1
)
=
cos
(
p
o
s
/
1000
0
2
i
/
d
m
o
d
d
)
\begin{gathered} \mathrm{PE}(\text { pos }, 2 i)=\sin \left(p o s / 10000^{2 i / d_{m o d d}}\right) \\ \mathrm{PE}(p o s, 2 i+1)=\cos \left(p o s / 10000^{2 i / d_{m o d d}}\right) \end{gathered}
PE( pos ,2i)=sin(pos/100002i/dmodd)PE(pos,2i+1)=cos(pos/100002i/dmodd)
where pos is the position and
i
i
i is the dimension. That is, each dimension of the positional encoding corresponds to a sinusoid. The wavelengths form a geometric progression from
2
π
2 \pi
2π to
10000
⋅
2
π
10000\cdot 2 \pi
10000⋅2π. This function was chosen because the authors hypothesized it would allow the model to easily learn to attend by relative positions, since for any fixed offset
k
,
P
E
pos
+
k
k, \mathrm{PE}_{\text {pos }+k}
k,PEpos +k can be represented as a linear function of
P
E
pos
\mathrm{PE}_{\text {pos }}
PEpos .

2. Relative Position Encodings
Relative Position Encodings are a type of position embeddings for Transformer-based models that attempts to exploit pairwise, relative positional information. Relative positional information is supplied to the model on two levels: values and keys. This becomes apparent in the two modified self-attention equations shown below. First, relative positional information is supplied to the model as an additional component to the keys
e
i
j
=
x
i
W
Q
(
x
j
W
K
+
a
i
j
K
)
T
d
z
e_{i j}=\frac{x_{i} W^{Q}\left(x_{j} W^{K}+a_{i j}^{K}\right)^{T}}{\sqrt{d_{z}}}
eij=dzxiWQ(xjWK+aijK)T
Here
a
a
a is an edge representation for the inputs
x
i
x_{i}
xi and
x
j
x_{j}
xj. The softmax operation remains unchanged from vanilla self-attention. Then relative positional information is supplied again as a sub-component of the values matrix:
z
i
=
∑
j
=
1
n
α
i
j
(
x
j
W
V
+
a
i
j
V
)
z_{i}=\sum_{j=1}^{n} \alpha_{i j}\left(x_{j} W^{V}+a_{i j}^{V}\right)
zi=j=1∑nαij(xjWV+aijV)
In other words, instead of simply combining semantic embeddings with absolute positional ones, relative positional information is added to keys and values on the fly during attention calculation.

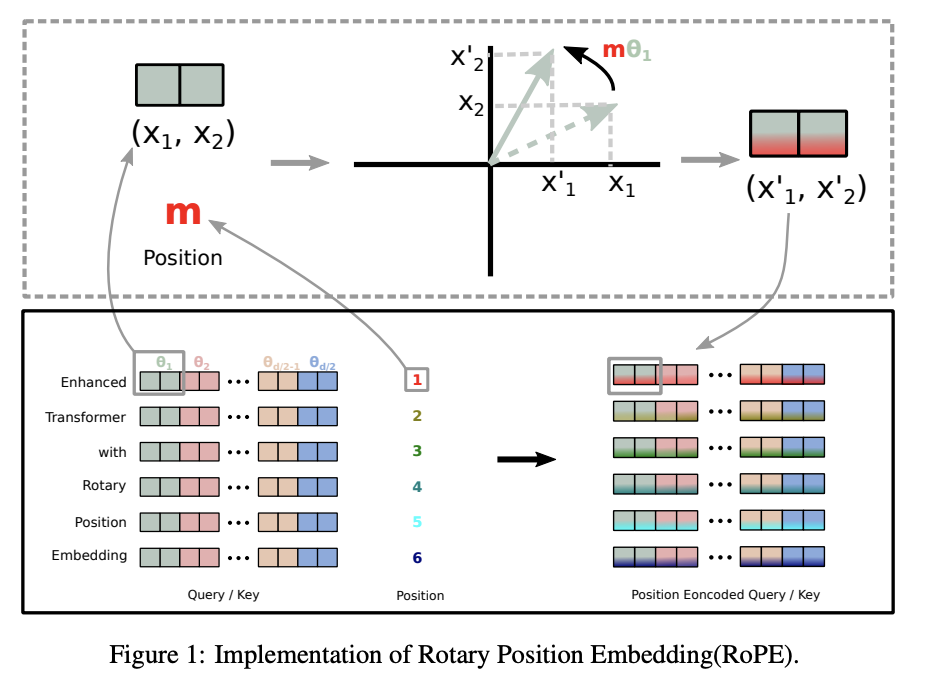
3. Rotary Position Embedding
Rotary Position Embedding, or RoPE, is a type of position embedding which encodes absolute positional information with rotation matrix and naturally incorporates explicit relative position dependency in self-attention formulation. Notably, RoPE comes with valuable properties such as flexibility of being expand to any sequence lengths, decaying inter-token dependency with increasing relative distances, and capability of equipping the linear self-attention with relative position encoding.
4. Conditional Positional Encoding
Conditional Positional Encoding, or CPE, is a type of positional encoding for vision transformers. Unlike previous fixed or learnable positional encodings, which are predefined and independent of input tokens, CPE is dynamically generated and conditioned on the local neighborhood of the input tokens. As a result, CPE aims to generalize to the input sequences that are longer than what the model has ever seen during training. CPE can also keep the desired translation-invariance in the image classification task. CPE can be implemented with a Position Encoding Generator (PEG) and incorporated into the current Transformer framework.
5. Attention with Linear Biases
ALiBi, or Attention with Linear Biases, is an alternative to position embeddings for inference extrapolation in Transformer models. When computing the attention scores for each head, the ALiBi method adds a constant bias to each attention score ( q i ⋅ k j , left ) \left(\mathbf{q}_{i} \cdot \mathbf{k}_{j}, \text{left} \right) (qi⋅kj,left) As in the unmodified attention sublayer, the softmax function is then applied to these scores, and the rest of the computation is left unmodified. m is a head-specific scalar that is set and not learned throughout training. When using ALiBi no positional embeddings are added at the bottom of the network.
参考资料:
[1] Self-Attention and Positional Encoding
[2] How Positional Embeddings work in Self-Attention (code in Pytorch) | AI Summer (theaisummer.com)

















 1886
1886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









