






Embedding
什么是Embedding
Embedding(嵌入)是机器学习和自然语言处理(NLP)中的一种关键技术,其核心思想是将高维、离散、非结构化的数据(如文字、图像、用户行为等)转换为低维、连续、稠密的向量表示。这些向量不仅能被计算机高效处理,还能捕捉数据之间的潜在关系(如语义、相似性等)。例如:
文字:单词“猫” → 向量 [0.3, -0.8, 1.2, …, 0.5]
图像:一张猫的图片 → 向量 [0.7, 0.1, -0.3, …, 0.9]
用户行为:用户点击商品A → 向量 [0.4, -0.2, 0.6, …, 0.1]
Embedding Projector:https://projector.tensorflow.org/
为什么需要Embedding?
-
解决高维稀疏问题
例如,用传统One-hot编码表示一个包含10万单词的词典,每个单词会变成一个10万维的向量,其中仅有一个位置是1,其余全为0。这种稀疏表示效率低下,且无法表达单词之间的关系(如“猫”和“狗”都是动物,但它们的One-hot向量正交,相似度为0)。
Embedding通过降维(如压缩为300维)解决了这一问题,同时保留了关键信息。 -
捕捉语义和关联性
-
Embedding的向量空间中,语义或功能相似的对象(如“猫”和“狗”)距离较近,而差异大的对象(如“猫”和“汽车”)距离较远。这种特性使模型能更好地理解数据。
-
语义相似性:
-
词向量:向量(“国王”) - 向量(“男”) + 向量(“女”) ≈ 向量(“女王”)
-
句子向量:相似度(向量(“今天天气好”), 向量(“阳光明媚”)) 接近1。
-
-
视觉关联:猫和狗的图片向量距离较近,而猫和汽车的向量距离较远。
-
-
实现跨领域知识迁移
-
预训练Embedding:在大规模数据上训练的通用Embedding(如BERT、GPT)可迁移到不同任务,减少数据标注成本。
-
跨领域对齐:将不同领域的数据映射到同一向量空间,实现知识融合。
- 例如:将用户购物行为(电商)和观看历史(视频平台)的Embedding结合,实现跨平台推荐。
-
-
解决非结构化数据处理难题
-
非结构化数据(如文本、图像、音频)难以直接被算法处理,Embedding将其转化为结构化向量,使模型能够“理解”数据。
文本:单词、句子、文档 → 向量。
图像:图片 → 向量(通过CNN提取特征)。
行为数据:用户点击序列 → 向量(如RNN、Transformer编码)。
-
-
支撑复杂模型的底层架构
几乎所有深度学习模型都依赖Embedding作为输入层:NLP模型:BERT、Transformer的输入是词/子词Embedding。
推荐模型:DeepFM、YouTube推荐算法将用户和商品ID映射为Embedding。
图神经网络:节点Embedding(如Node2Vec)用于社交网络分析。
Embedding的技术原理
如何生成Embedding?
Embedding的生成依赖于机器学习模型,其核心思想是让模型在任务中自动学习数据的内在规律。常见的生成方式包括:
| 方法 | 原理 | 典型案例 |
|---|---|---|
| 无监督学习 | 利用数据自身的结构(如上下文、共现关系)生成向量。 | Word2Vec、GloVe、Node2Vec |
| 监督学习 | 通过标签任务(如分类、预测)间接学习向量。 | BERT、图像分类模型 |
| 预训练+微调 | 在大规模数据上预训练通用Embedding,再针对特定任务微调。 | GPT-3、CLIP(图文跨模态) |
经典模型解析
-
Word2Vec:通过“上下文预测中心词”(CBOW)或“中心词预测上下文”(Skip-Gram)学习词向量。
示例:模型发现“猫”和“狗”常出现在相似上下文中,因此它们的向量距离相近。 -
BERT:基于Transformer的双向编码器,通过掩码语言模型(MLM)和句子预测任务生成上下文相关的动态Embedding。
优势:同一词在不同语境中有不同向量(如“苹果”在“吃苹果”和“苹果手机”中含义不同)。 -
CNN图像嵌入:卷积神经网络通过逐层提取边缘、纹理、物体部件等特征,最终生成图像的紧凑表示。
-
词嵌入(Word Embedding)
-
输入:单词“apple” → 输出:[0.25, -0.1, 0.7, …, 0.4](300维向量)。
-
语义相似性:cosine_similarity(向量(“猫”), 向量(“狗”)) 接近1,而 cosine_similarity(向量(“猫”), 向量(“电脑”)) 接近0。
-
Embedding的四大应用场景
-
自然语言处理(NLP)
-
语义搜索:将用户查询与文档转化为向量,通过相似度匹配结果(如Google搜索)。
-
机器翻译:跨语言Embedding对齐(如将中英文映射到同一空间)。
-
情感分析:通过向量判断文本情感极性(正面/负面)。
-
-
推荐系统
-
协同过滤:用户和商品Embedding的点击行为矩阵分解(如Netflix推荐)。
-
跨域推荐:利用用户行为Embedding实现跨平台推荐(如从电商到视频平台)。
-
-
计算机视觉
-
图像检索:输入“夕阳照片”,返回相似向量对应的图片。
-
人脸识别:将人脸图像映射为特征向量,对比欧氏距离判断身份。
-
-
图数据分析
-
社交网络:用户Embedding可用于社群发现或影响力预测。
-
知识图谱:实体Embedding支持智能问答(如“姚明的妻子是谁?”)。
-
Embedding在RAG引擎中的工作流
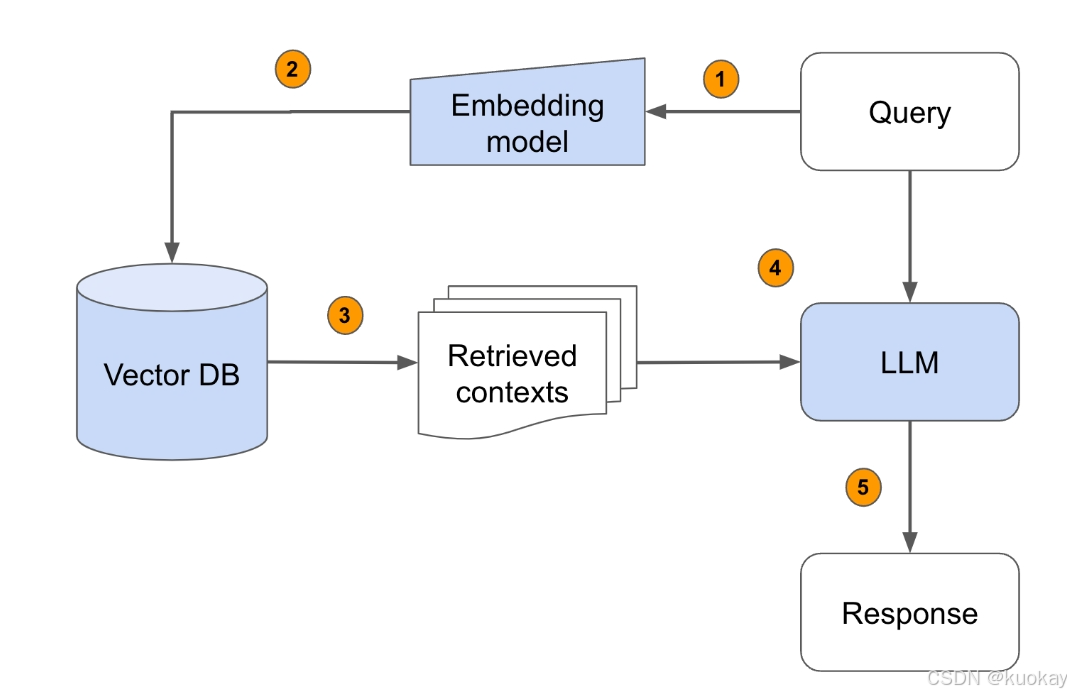
【流程说明】
-
查询嵌入化:将用户输入的查询传递给嵌入模型,并在语义上将查询内容表示为嵌入的查询向量。
-
向量数据库查询:将嵌入式查询向量传递给向量数据库。
-
检索相关上下文:检索前k个相关上下文——通过计算查询嵌入和知识库中所有嵌入块之间的距离(如余弦相似度)来衡量检索结果。
-
上下文融合:将查询文本和检索到的上下文文本传递给对话大模型(LLM)。
-
生成回答:LLM 将使用提供的内容生成回答内容。
常见的Embedding模型
Huggingface上的mteb是一个海量Embeddings排行榜,定期会更新Huggingface开源的Embedding模型各项指标,进行一个综合的排名,大家可以根据自己的实际应用场景,选择适合自己的Embedding模型。

MTEB(Massive Text Embedding Benchmark)是一个用于评估文本嵌入**(Embedding)**模型的综合性基准测试平台。通过多任务和多数据集的组合,MTEB可以全面衡量不同Embedding模型在各种自然语言处理(NLP)任务中的表现,如文本分类、语义检索、文本聚类等。
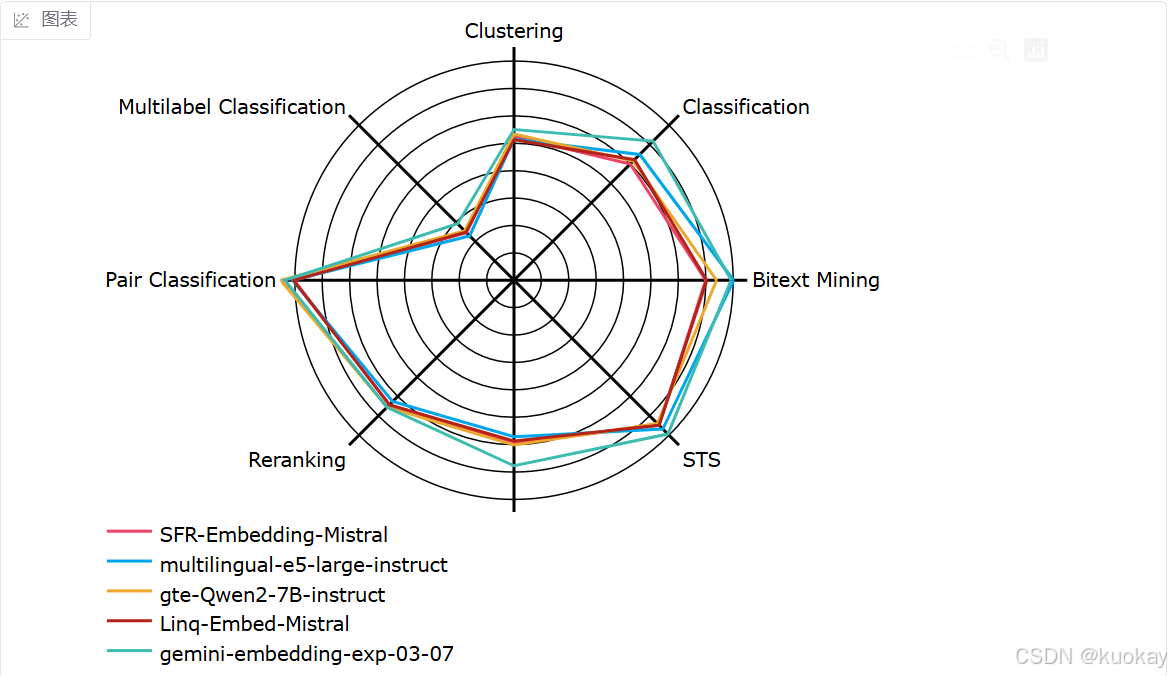
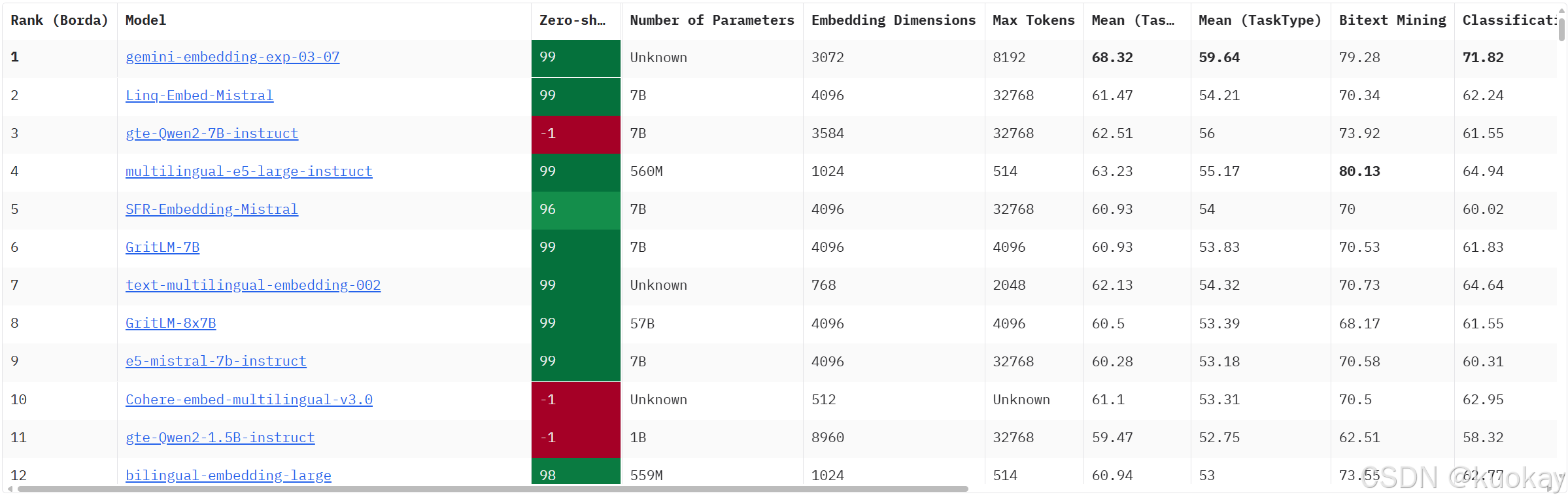
以下是基于模型名称和行业常见设计逻辑推测的 12款Embedding模型简介、特点及适用场景,仅供参考:
1. gemini-embedding-exp-03-07
-
简介:Google Gemini系列实验性Embedding模型,可能基于多模态架构设计。
-
特点:
-
多模态支持(文本、图像等);
-
高维语义捕捉能力;
-
实验性质,可能未完全开放。
-
-
适用场景:多模态搜索、跨模态内容推荐、前沿研究。
2. ling-Embed-Mistral
-
简介:基于Mistral架构优化的轻量级Embedding模型,专注语言嵌入。
-
特点:
-
轻量化(参数量较小);
-
低资源环境下高效推理;
-
支持多语言。
-
-
适用场景:移动端应用、实时语义检索、低资源设备部署。
3. gte-Qwen2-7B-instruct
-
简介:阿里通义千问(Qwen)系列的7B参数版本,支持指令微调的通用Embedding模型。
-
特点:
-
大规模参数(7B)带来强表征能力;
-
支持任务指令动态适配;
-
中文场景优化。
-
-
适用场景:中文语义理解、复杂问答系统、长文本编码。
4. multilingual-e5-large-instruct
-
简介:微软E5系列的多语言增强版本,支持指令驱动的Embedding生成。
-
特点:
-
覆盖100+语言;
-
指令微调提升任务适配性;
-
适合长文本编码。
-
-
适用场景:跨语言检索、多语言内容分类、全球化应用。
5. SFR-Embedding-Mistral
-
简介:SFR-Embedding-Mistral 是一款专门优化的嵌入模型,适合特定的高效检索任务。
-
特点:
-
领域适配(如医疗、法律);
-
结合领域知识增强语义表征;
-
模型轻量。
-
-
适用场景:垂直领域搜索、专业文档分析、知识图谱构建。
6. GritLM-7B
-
简介:一种生成式表征指令调整语言模型,专注复杂语义解析。
-
特点:
-
细粒度实体/关系抽取;
-
高精度长文本建模;
-
需较高算力。
-
-
适用场景:知识抽取、复杂问答、学术文献分析。
7. text-multilingual-embedding-002
-
简介:通用多语言Embedding模型(可能为开源社区或企业级产品)。
-
特点:
-
平衡多语言支持与性能;
-
中等模型规模;
-
易于部署。
-
-
适用场景:多语言搜索、跨语言推荐、中小型企业应用。
8. GritLM-8x7B
-
简介:GritLM系列的混合专家(MoE)版本,8x7B参数,性能更强。
-
特点:
-
混合专家架构提升效率;
-
支持超长上下文(如10万tokens);
-
资源消耗较高。
-
-
适用场景:超长文本编码、多模态融合分析、高精度语义匹配。
9. e5-mistral-7b-instruct
-
简介:结合Mistral架构优化的E5指令微调版本,7B参数。
-
特点:
-
指令驱动动态适配任务;
-
多语言支持;
-
兼顾性能与效率。
-
-
适用场景:交互式搜索、个性化推荐、动态场景适配。
10. Cohere-embed-multilingual-v3.0
-
简介:Cohere公司的多语言Embedding商业模型,支持大规模部署。
-
特点:
-
工业级稳定性;
-
高并发支持;
-
多语言优化(侧重英语、欧洲语言)。
-
-
适用场景:企业级搜索、广告推荐、全球化SaaS服务。
11. gte-Qwen2-1.5B-instruct
-
简介:阿里通义千问的轻量级版本(1.5B参数),支持指令微调。
-
特点:
-
低资源消耗;
-
快速推理;
-
中文场景优先。
-
-
适用场景:中文短文本处理、实时对话系统、边缘计算场景。
12. bilingual-embedding-large
-
简介:专注双语(如中英、英法)对齐的Embedding模型。
-
特点:
-
双语语义空间对齐;
-
跨语言检索优化;
-
模型规模适中。
-
-
适用场景:机器翻译、双语内容检索、跨语言知识库构建。
Embedding模型选型总结(仅供参考)
- 按场景需求:
-
多语言:multilingual-e5-large-instruct、Cohere-embed-multilingual-v3.0;
-
中文优先:gte-Qwen2系列、bilingual-embedding-large;
-
垂直领域:SFR-Embedding-Mistral、GritLM系列;
-
轻量级:ling-Embed-Mistral、gte-Qwen2-1.5B-instruct。
- 按资源条件:
-
高算力:GritLM-8x7B、gemini-embedding-exp-03-07;
-
低成本:text-multilingual-embedding-002、ling-Embed-Mistral。
- 按任务类型:
-
搜索/推荐:Cohere-embed-multilingual-v3.0、e5-mistral-7b-instruct;
-
知识密集型:GritLM-7B、gte-Qwen2-7B-instruct;
-
实时交互:gte-Qwen2-1.5B-instruct、ling-Embed-Mistral。
- 核心原则:
-
明确需求:优先匹配场景(多语言、垂直领域、资源限制);
-
平衡性能与成本:大模型适合高精度任务,轻量模型适合高频实时场景;
-
关注生态支持:商业模型(如Cohere)提供稳定性,开源模型(如E5)灵活性更高。



















 4310
4310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











