







Transformer运用在计算机视觉领域的不足:
Transformer中的attention是用每一个输入的query去和key做比对然后加权和,复杂度是
O
(
n
2
)
O(n^2)
O(n2)。一般硬件计算可以支持的query长度是几千,但一般视觉分类任务的图片大小是224*224=50176,将2d图片直接按像素点转化成1d序列是不可能的。
其他的改进方式:
稀疏注意力近似全局注意力,轴注意力将图片拆成宽*高来分别求注意力再乘起来
ViT的基本思路
ViT将图片按16*16的网格大小划分,对224*224的图片划分的结果是14*14=196个小图(224/16=14)。将这196个小图作为输入序列(类比Transformer中的单词)进行监督学习。
结构


命名方式举例
ViT-B/16:base,patchsize=16
过程
首先将图片分割成网格,经过线性投射层得到特征(patch embedding)。将特征加上位置信息(position embedding),并添加一个0位置为class token(class embedding)。这个cls也和各个特征进行交互,因此可以学到一些分类信息,以此将cls作为输出来分类。
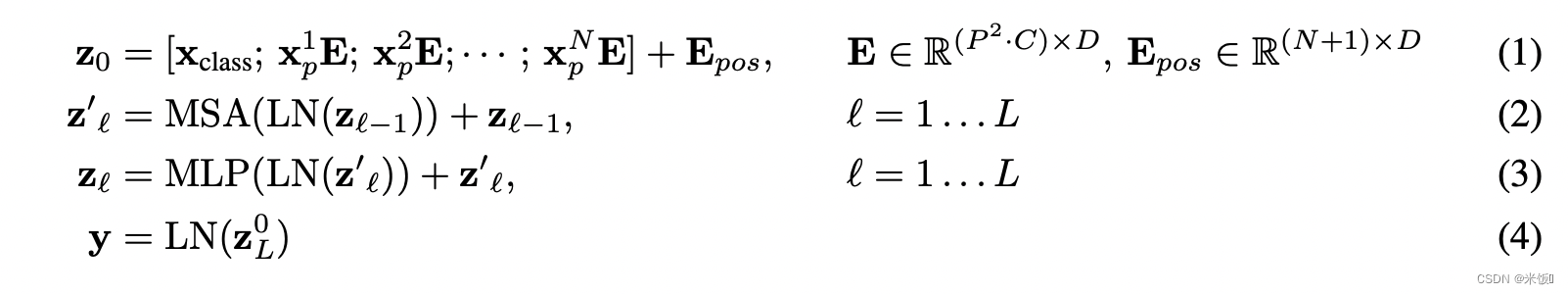
维度计算
以每个网格大小16*16、图片大小224*224,vit-base为例。token的个数为224*224/(1616)=196,每个图像块的维度是1616*3=768。此时相当于将原图片224*224*3转化为196*768。线性投射层的维度是768*768(D),(其中D是可自己决定的,这里是768),因此经过线性投射层后是196*768,这里完成将图片转化成token。将token和cls token加上位置信息(单独位置信息也是768,是加不是拼接)传入transformer,此时维度是(196+1)*768,对应图中右下角embedded patches。经过layernorm后生成KQV,其中vit-base的多头是12个头,因此多头注意力投影后的KQV维度是197*64,其中768/12=64。最终将12个头的KQV都拼接起来输出,维度依旧是197*768。经过残差和LayerNorm后维度不变,MLP将维度放大4倍再投射回去,最终输出为197*768。Transformer block的输入与输出维度都一样。
位置编码
1d,2d(i,j)和相对位置编码(两个token的间隔距离)的结果大致相同。
ViT与ResNet对比
1 归纳偏置
Transformer缺少归纳偏置(inductive biases,即先验信息),归纳偏置包括:
- locality:相邻的区域有相似的特征,靠得越近的东西相关性越强。卷积是按窗口计算的,默认相邻的一起计算。Transformer的自注意力部分直接看整个序列,位置编码在初始时也是没有2d信息的(自行学习)。下图证明ViT在最初几层就可以注意到距离很远的patch的相关性。
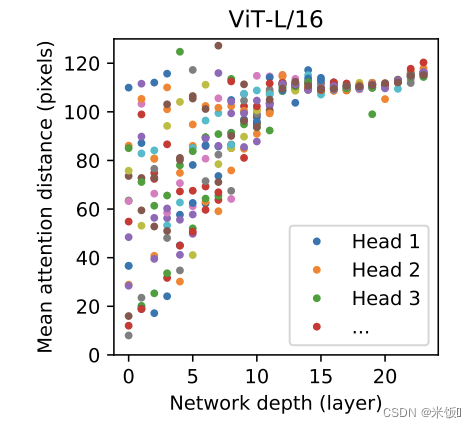 3. translation equivariance:f(g(x))=g(f(x)),无论先做卷积还是先做平移,结果都一样。卷积只要是相同位置乘相同卷积核结果就是一样的。
3. translation equivariance:f(g(x))=g(f(x)),无论先做卷积还是先做平移,结果都一样。卷积只要是相同位置乘相同卷积核结果就是一样的。
因此ViT需要更多数据来预训练。
2 后续处理
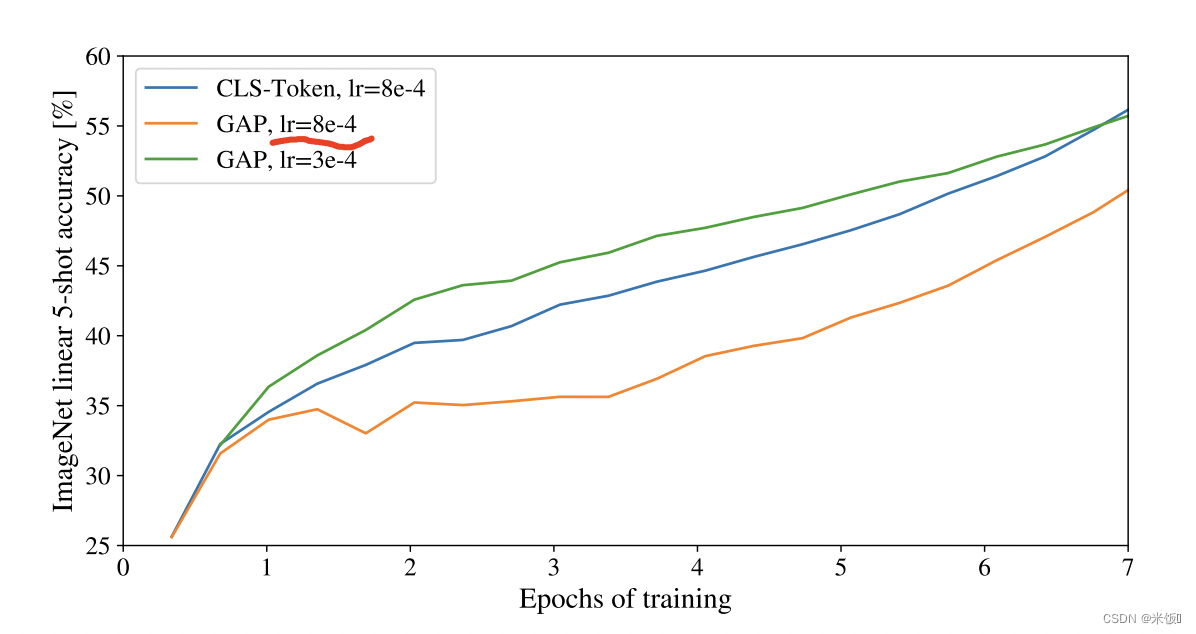
ResNet对最终的feature map使用了globally average polling(GAP)加上线性层来得到最终分类,而ViT则是用cls的结果做输出。经过试验证明(原文中),直接在所有196个输出token做GAP得到分类结果,和cls效果相近,但两个方法的学习率未必相同,需要好好调参。
混合模型
先将图片输入CNN,得到14*14的特征图,然后后续相同。在小数据集上效果更好。
微调
图片输入尺寸变化时,如果patch size不变:
- 对应生成的token序列长度也会变化,在无硬件限制的情况下ViT可以处理任意长度。
- token个数改变意味着位置编码也需要改变,变化较小的情况可以通过interpolation插值操作改变,但变化较大时需要重新学习否则表现下降。(局限性)

















 2111
2111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









