






链接:https://www.zhihu.com/question/525167811
编辑:深度学习与计算机视觉
声明:仅做学术分享,侵删
作者:陈小康
https://www.zhihu.com/question/525167811/answer/2419797948
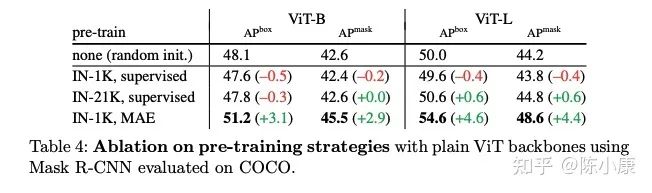
从文中的 Tab.4, Tab.5 的结果来看,同样是 IN-21K 预训练,ViT-base 和 Swin-base 差距还挺大的。这波结果做上去主要还是靠 Masked Image Modeling 预训练。
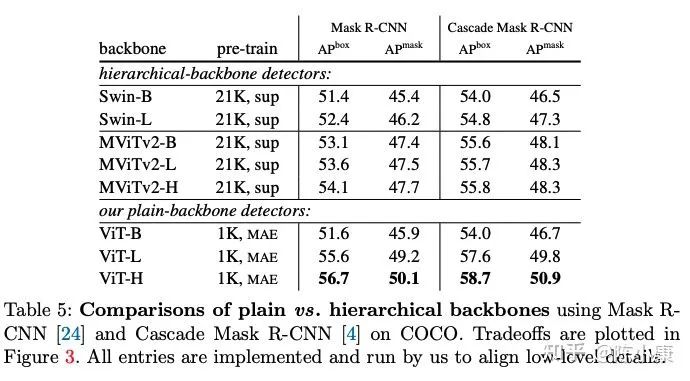
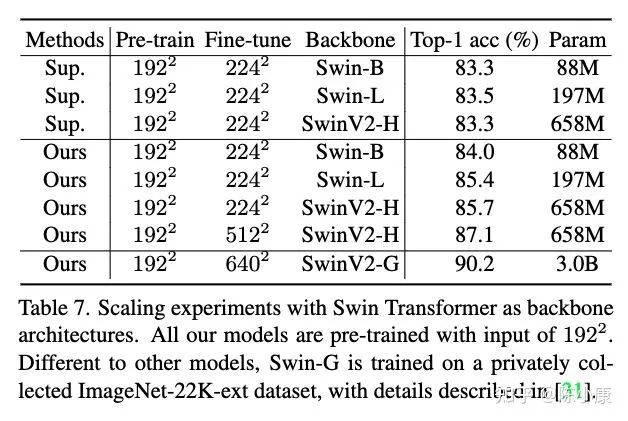
2. 对于 hierarchical-backbone 的预训练,SimMIM 简单地做了尝试。虽然没有对"学习表征"和"解决 pre-text task" 做好解耦 (我们之前的工作 CAE 证明了,预训练阶段对”学习表征“和”解决 pre-text task“这两个功能的彻底分离能学到更好的表征),但相比于有监督学习还是提升很明显的 (见 SimMIM 的 Tab.7,文中只做了分类任务),证明了 MIM 也能比较好地扩展到 hierarchical-backbone。另一方面,hierarchical-backbone 在计算量方面也是比较有优势的,比较好奇 ViT 和 hierarchical-backbone 做公平对比结果会怎样,例如,都用 MIM 算法进行自监督预训练
作者:九亿少年酒后的梦
https://www.zhihu.com/question/525167811/answer/2417273999
总结起来,拿Swin来做backbone的话,window size的self-attention就够了,没有必要用shift,用一个普通的带shortcut的卷积来代替shift操作就行了。就是attention+convolution效果极好。跟我们的CVPR 2022 paper CMT: Convolutional Neural Networks Meet Vision Transformers (https://arxiv.org/pdf/2107.06263.pdf) 的核心思想一致,就是往transformer里面加点带残差的卷积=YYDS。
作者:吴紫屹
https://www.zhihu.com/question/525167811/answer/2419178401
只想提一个小点:
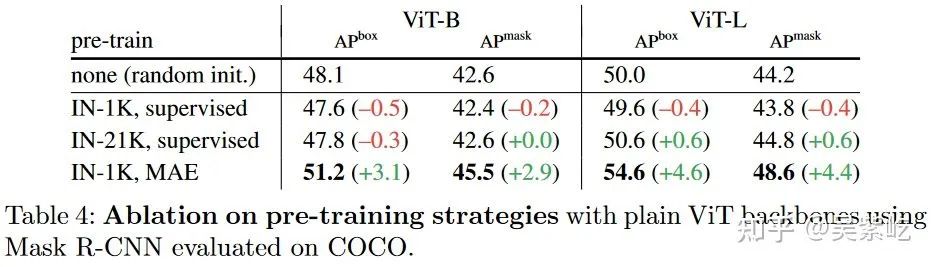
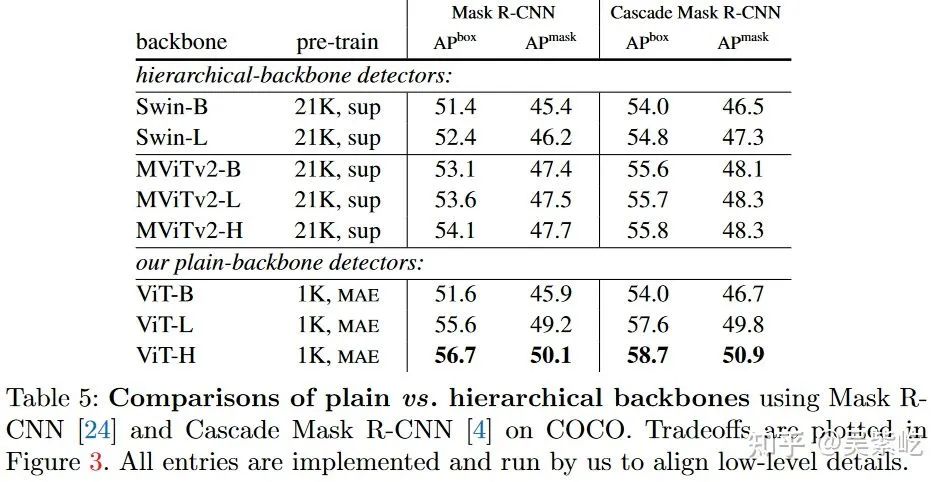
对于 Table 4/5 的结果还挺意外的,MAE pretrained ViT 会比 supervised pretrained ViT/Swin 都要好。虽然早有文章 (e.g. MoCo) 达到了 SSL pretraining beats supervised pretraining in downstream tasks,但 IN1K MAE 能超过 IN21K supervised 还是挺神奇的,尤其看 Table 4,同样在 ViT 上超过了3-4个点。
不过转念一想似乎似乎也不是不合理,supervised pretraining 所使用的分类任务,更多是要求模型学习到 invariant feature,而 MAE 学习到的 content-aware feature 或许对于检测更重要?这么说 MAE 这类 reconstruction-based SSL 方法做 work 之后,或许大家选用检测/分割的 backbone 就会从分类预训练变成生成式预训练了。
We are also curious about the influence of MAE on hierarchical backbones. This is largely beyond the scope of this paper, as it involves finding good training recipes for hierarchical backbones with MAE
MAE enjoys the efficiency benefit from plain ViT by skipping the encoder mask token [23]. Extending this strategy to hierarchical backbones is beyond the scope of this paper
最后就是,非常好奇 Swin-Transformer + MAE 的性能,文中也说了因为 hierarchical Transformer 不能丢弃 masked tokens,所以想结合还需要精心设计。不过即使是 Swin + naive MAE 在 IN1K 也取得了超过 IN21K 的性能,或许说明 MAE 确实是更适合检测这一下游任务的预训练方法。期待之后有工作 (或许已经有了但我没看到?) 可以专门研究 hierarchical Transformer + reconstruction-based pretraining。
作者:Choas
https://www.zhihu.com/question/525167811/answer/2418730248
个人觉得这篇文章非常棒,又提供了一个SOTA的基线。大佬们总是把我们犹豫的问题做的很彻底,而且做的很好。以前我也在想VIT到底适不适合做Detection,但却迟迟没有做实验。
顺带一提的是,作者比较的[17]是我所在团队的工作。
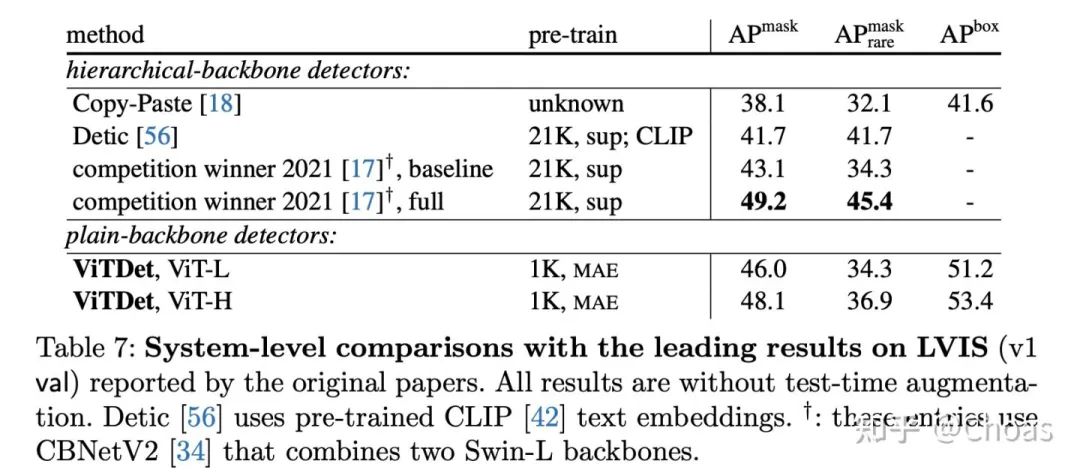
我们这个工作预计今年也会进一步完善发出来,并会在ViTDet上做结合试试,希望可以进一步突破LVIS。所以也期待ViTDet快点开源出来233。
作者:kinredon
https://www.zhihu.com/question/525167811/answer/2422611315
有很多答主已经把 ViTDet 解析得很好了,这篇文章主要说明了层次化结构(FPN)对 ViT 来说其实是非必要的。作者提出 ViTDet 仅利用 ViT 最后的单层特征进行简单的下采样和上采样达到类似 FPN 的效果。
结构对比可以看下图:

实验结果:
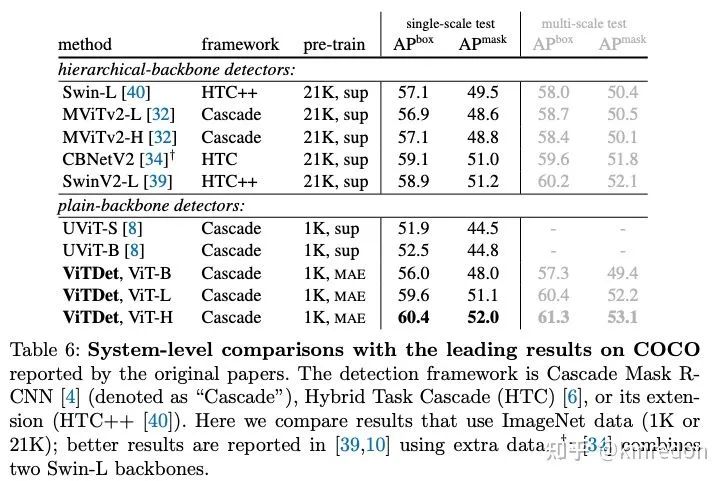
但个人认为,这篇文章的意义不仅仅在于不使用 FPN,而核心是有效地解耦 backbone 和 detection head,再深层次一点是解耦预训练和下游任务,backbone 的设计不再依赖下游任务。
想想最开始无监督预训练的的兴起,大家都想通过给模型喂海量未标记的数据,学习通用的视觉语言模型,视觉研究者都想复制 Bert 在 nlp 里面的成功。从最开始的 ImageNet 有监督 pretrain,到后来无监督的生成式学习和对比学习。MoCo 和 SimCLR 超过有监督 pretrain 彻底带火无监督对比学习。
虽然后面出来了许多对比学习工作,但心中难免有个疑问,为啥在 nlp 里面 mask auto encoder 这么有用,在 cv 里面不太行?这个随着 Vision Transformer 的兴起,MAE 做到了这件事,给出了非常惊艳的效果(具体可以见原文的case)。当初 MAE 出来的时候和同学讨论过 MAE 为什么是基于 ViT 而不是 Swin,大家也都想见见 MAE 在 Swin 上的效果。我个人认为是因为 ViT 足够简单,是的足够简单!ViT 是最简单的 Vision Transformer,引入最少的归纳偏置(inductive bias),简单到拥有通用的建模能力,足够的 capacity,对 big model 和 data 扩展性以及更好地链接 Vision and Language。
但之前工作都在改进 ViT,向里面加入一些 prior,其中 Swin 引入 CNN 设计的一些特性,获得了足够惊人的结果。现在 ViTDet 告诉你其实这样层次化设计其实是非必要的,解偶预训练和下游任务的模型设计。那下一步要往哪发展呢?个人认为有几个方面:
继续研究更强大的,更data-efficient 的基于 VIT 的无监督预训练模型;
多任务学习:以 ViT 为基础特征提取器,设计下游任务 Head,实现多任务学习,甚至可以把现有的主流视觉任务都集成在一起;
跨模态学习等等
相信接下来会有一些很不错的工作。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓
















 664
664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









