







1 前言
相关论文发表顺序
2017.6 Transformer
2018.6 GPT
2018.10 BERT
2019.2 GPT-2
2020.5 GPT-3
GPT系列都是自回归语言模型。预测未来。
2 GPT
Generative Pre-Training
2.1 简述
GPT在没有标号的数据上训练一个预训练模型,是一个语言模型,之后在有标号的子任务上微调(自监督学习)。之前NLP并没有合适的大数据集,所以没有使用上述方法,这也使得以前每个任务都要有一个对应的模型(学习的feature,如单词vector,和输入作为对应模型的训练)。
使用无标号文本的困难:
- 不知道用什么目标函数(损失函数)。语言模型,机器翻译,文本一致性,不同任务有不同的目标函数,并且不通用(任务不同效果不同)
- 如何把学习的文本表示传递到下游子任务。因为NLP子任务差别很大。
使用了Transformer。相比于RNN,作者认为Transformer迁移学习学到的feature更稳健。
2.2 无监督预训练
对于无标号的词序列:
U
=
{
u
1
,
.
.
.
,
u
n
}
U=\{u_1,...,u_n\}
U={u1,...,un},模型目标函数是最大化似然:
L
1
(
U
)
=
∑
i
l
o
g
P
(
u
i
∣
u
i
−
k
,
.
.
.
,
u
i
−
1
;
Θ
)
L_1(U)=\sum_ilogP(u_i|u_{i-k},...,u_{i-1}; \Theta)
L1(U)=i∑logP(ui∣ui−k,...,ui−1;Θ)
其中
Θ
\Theta
Θ是模型参数,k是上下文窗口,是超参数。log内的含义是根据给定的前k个词预测当前单词i,整句话的出现概率就是每个单词出现的联合概率(用了对数似然)。k越长,可以在更长的文本中找关系。
模型使用的是Transformer decoder。 因为预测第i个单词时不可以看到后面的单词,用decoder中的mask可以解决问题。
h
0
=
U
W
e
+
W
p
h
l
=
t
r
a
n
s
f
o
r
m
e
r
_
b
l
o
c
k
(
h
l
−
1
)
∀
i
∈
[
1
,
n
]
P
(
u
)
=
s
o
f
t
m
a
x
(
h
n
W
e
T
)
h_0 = UW_e+W_p\\ hl=transformer\_block(h_{l-1}) \forall i \in [1,n]\\ P(u) = softmax(h_nW_e^T)
h0=UWe+Wphl=transformer_block(hl−1)∀i∈[1,n]P(u)=softmax(hnWeT)
其中
U
=
(
u
−
k
,
.
.
.
,
u
−
1
)
U=(u_{-k},...,u_{-1})
U=(u−k,...,u−1)是u之前的k个单词,h是transformer解码器的输出。Wp是位置信息。
与BERT的区别:
目标函数的区别,一个预测未来一个完形填空,因此一个用解码器一个用编码器
2.3 有监督的微调
标签数据集C由输入序列
(
x
1
,
.
.
.
,
x
m
)
(x_1,...,x_m)
(x1,...,xm)和标签y组成,将x输入模型,得到最终的transformer输出为
h
l
m
h_l^m
hlm,然后传入最终的线性层得到预测和最大化目标函数:
P
(
y
∣
x
1
,
.
.
.
,
x
m
)
=
s
o
f
t
m
a
x
(
h
l
m
W
y
)
L
2
(
C
)
=
∑
(
x
,
y
)
l
o
g
P
(
y
∣
x
1
,
.
.
.
,
x
m
)
P(y|x_1,...,x_m)=softmax(h^m_lW_y)\\ L_2(C)=\sum_{(x,y)}logP(y|x_1,...,x_m)
P(y∣x1,...,xm)=softmax(hlmWy)L2(C)=(x,y)∑logP(y∣x1,...,xm)
两个目标函数一起训练时最佳的,即同时完成给定一个序列预测下一个词和给定一个序列预测标签:
L
3
(
C
)
=
L
2
(
C
)
+
λ
L
1
(
C
)
L_3(C)=L_2(C)+\lambda L_1(C)
L3(C)=L2(C)+λL1(C)
2.4 具体应用
transformer是预训练好的不会变。其他是微调的过程中调整的,输入是一个或多个序列
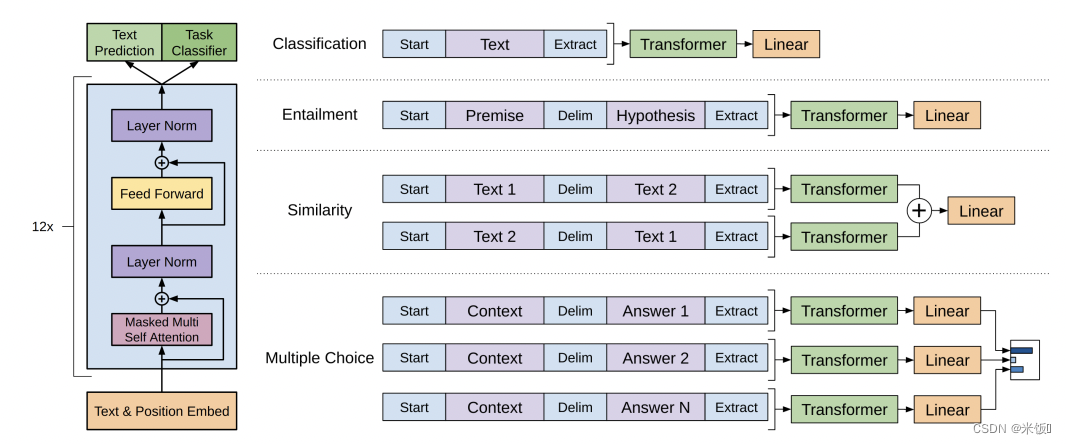
-
分类:
一段文本判断标号。例如用户对产品的评价的正负面。做法是:将要分类的文本添加初始token和抽取token,放入decoder,得到抽取token的特征,放入线性层得到分类结果。线性层是微调的时候新加的,微调的过程中学习。 -
蕴含:
给定文本和假设,看文本是否蕴含假设(三分类:支持,反对,不支持不反对)。例如文本是我给你买了一束花,假设是我喜欢你。形式是开始符分隔符抽取符。 -
相似:
如果a和b相似,那么可以给文本去重。相似具有对称性,因此将两个文本的不同排序分别放入transformer。二分类问题 -
多选:
一个问题多个答案,n个答案n个序列,概率更高的是答案。
2.5 实验
数据集BooksCorpus,12个decoder,隐藏层768
对比bert-base,数据集BooksCorpus、Wikipedia,12个encoder,隐藏层768,参数110M个
bert数据集更大,效果更好。
3 GPT-2
使用更大数据集WebText,模型参数1.5B个
预训练+微调方式存在问题:对每个下游任务还需重新训练模型,还需要有标号的数据,因此任务拓展成本大。
解决方案:zero-shot
不再训练模型,不需要下游任务的标号
3.1 与GPT的区别
GPT-2不再微调。GPT中需要构建输入序列(开始符、分隔符、抽取符),预训练时并没有这些符号,但微调环节可以让模型认识这些符号。GPT-2中做zero-shot,模型不能再被调整,不能引入特殊符号,因此输入应该更像自然语言。
输入举例:(给予提示,即以下例子序列第一个元素)
(translate to french, english text, french text)
(answer the question, document, question, answer)
作者认为如果模型足够强大,那么模型可以理解提示内容,同时这些提示也有可能出现在文本当中。
3.2 训练数据集
作者使用Reddit上爬取的网友评价更好的网页作为数据集WebText,其中有一些话包含了上节例子中的提示词或含义,这意味着模型确实有可能完成翻译的任务:

3.3 结果
一共训练了4个不同参数的模型效果如下。大部分任务上,表现呈上升趋势,预示着更大的数据集可以有更好的表现(GPT-3)。
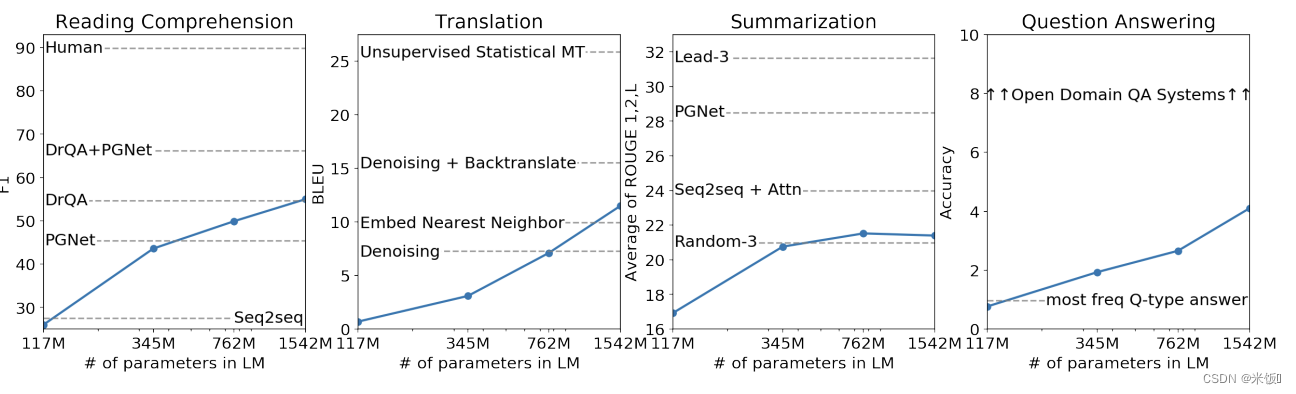
4 GPT-3
可学习参数个数175B,因此子任务不做任何梯度更新和微调。
4.1 Few-shot
作者认为存在的问题:(微调不合理)
- 需要一些标号数据进行微调,成本高
- 微调效果好未必模型好,可能是因为预训练数据与子任务有重合,不能认为模型的泛化性更好
- 人类学习子任务 只需少量例子
作者做法:
不更新参数的few-shot。
图片中:
few-shot的含义
few-shot的含义
简单来说:并不是使模型学会直接对输入的样本进行分类的能力,而是学会判断事物异同的能力。从大规模训练数据集中学习相似性函数,比较query与support set中每个样本的相似度,然后找出相似度最高的样本作为预测类别。
GPT中:
few-shot:给予任务描述(认为模型可以理解任务含义),提供一些例子,其中
⇒
\Rightarrow
⇒是提示(prompt)。**只做预测,不更新梯度。**期望attention可以从长文本中提取有用信息(上下文学习)。只做预测的模型比训练模型的内存消耗少的多。
one-shot与zero-shot只是例子个数的改变。
缺点:
- 当有很多个样本(例如翻译英语到法语的词对有很多组),构造GPT样本(将它们表现成下面形式)很麻烦,模型也未必支持过长的序列输入
- 每次小样本few-shot的样本有用信息并不能保存下来

不同参数的模型表现能力平均值为下图实线。
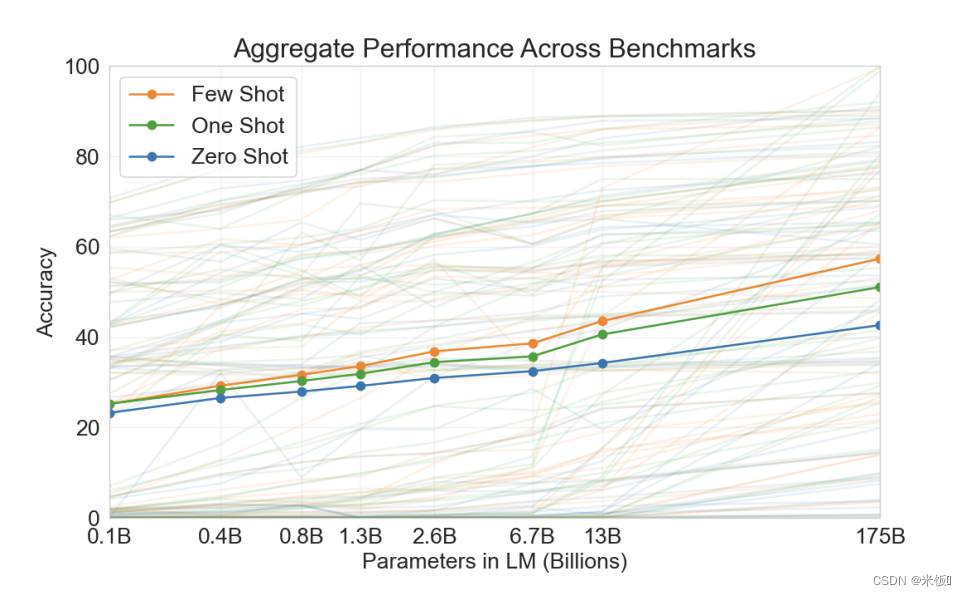
4.2 模型改动
sparse transformer中的改动
模型复杂度计算
4.3 数据集
Common Crawl,一个公开网页抓取项目,产生了很大的文本数据集。作者认为这个数据集中信噪比较低,垃圾网页多。因此作者采用以下方式清理数据:
- 过滤:把GPT-2的数据集作为正例,Common Crawl作为负例,做LR,对数据做二分类,预测的正例保留。
- 去重:将相似的内容去掉,用lsh算法。这个算法类似k近邻,根据汉明距离找到和查找内容同一空间的所有样本,然后找到该空间中与查找内容欧氏距离最近的样本。
- 添加其他高质量数据集
4.4 评估
用“answer:”或“A:”作为提示,后面是答案,作为评估对象。
二分类问题使用True和False
自由回答问题用beam search评估
4.5 局限性
- 长文本生成过程中容易重复
- 语言模型,只能往前看,不能双向
- 样本有效性低:数据量大;每个token权重相等(对于关键词和虚词等没有很好的区分);
- 不能确定是否是泛化能力好(可能子任务在预训练数据中有交集,这并不是推理,而是记忆,这样数据集越大效果越好)
- 无法解释
- 没有多模态
4.6 题外话
作者在文中写了模型可能造成的影响(负面),可见作者是有社会责任的。(钓鱼邮件、论文新闻造假、偏见或歧视(对特定性别、种族、宗教有特定倾向的输出))
5 GPT系列演变
GPT:预训练模型+微调,给予有标号的样本微调
GPT2:zero-shot,子任务上不提供任何训练样本,预训练模型直接子任务做预测
GPT3:few-shot,给予少量样本














 414
414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









