







1.关于BERT做NER要不要加CRF层?
关于BERT做NER,最简单的方式就是序列标注方法,以BERT得到token的embedding,后接softmax直接输出预测token的标签。
其实这种方案做NER也不错,为什么有些人会采用CRF替代softmax,softmax比较简单就是基于token embedding进行标签概率计算。而CRF的原理上理解是,CRF是全局无向转移概率图,能有效考虑词前后的关系。
因为对于序列标注问题,假设已经知道前面一个token标签为B-Location, 则下一个token标签大概率是I-Location,而不是O, 这样的问题下,CRF对于前后有依赖(也就是题主说的surrounding predictions),全局的概率转移建模估计更加的合理。
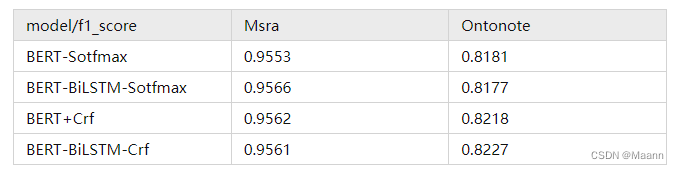
在两个中文NER上做了些BERT-Softmax与BERT-CRF的实验, 理论诚不欺我,实践是与其理论对应上的,加CRF层的效果是优于Softmax的。但这里要提醒一下,模型训练时,要保持CRF的learning-rate大于BERT层的learning-rate,大概100倍左右,不然可能会出现比BERT-Softmax差的结果。

2. BERT-CRF与BERT+BiLSTM+CRF相比,谁效果好?
关于加上BiLSTM有没有用?
先从理论上,我先给大家瞎比划两下。首先,加与不加这个BiLSTM结构是没有增加任何新信息的,加上它唯一的作用,就是借用BILSTM这种结构,进一步加强建模文本序列前后语序的关系。但由于BERT本身就是all-attention,就是全局的Attention,不存在说哪个token谁离我远,我就注意不到了(BERT原来较LSTM吹的,也是这一点,attention全局建模)。那这样说还真不好说,BiLSTM这种结构加进来是否能补强了,讲不明白,那就show实验把。
实验上来看,加BiLSTM理论上起码不会比原来坏。另外那个什么奥卡姆剃刀定律说过,如无必要,无增实体,这里就不多提了,各自有各自的喜好,各自体会吧。

3. BERT-BiLSTM-Softmax与BERT+BiLSTM+CRF相比,谁效果好?
都做到这里了,感觉还差一组实验才能完美,那就是BERT-BiLSTM-Softmax这种结构的如何呢,既然做到这里了,就把它补全把。可以看到BiLSTM这种结构去建模序列前后位置上的语序信息是有些效果的,能弥补部分BERT-Sotfmax不带前后语序依赖建模的问题,
4. 在速度上
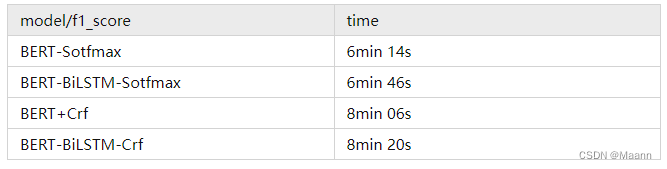
在速度上,以Msra数据集为例,train数据量41728, 以batch_size=24训练,完成训练花费时间大概是如下,总体来说CRF要慢不少。
转自:https://www.zhihu.com/question/398672104/answer/2777605204
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









