







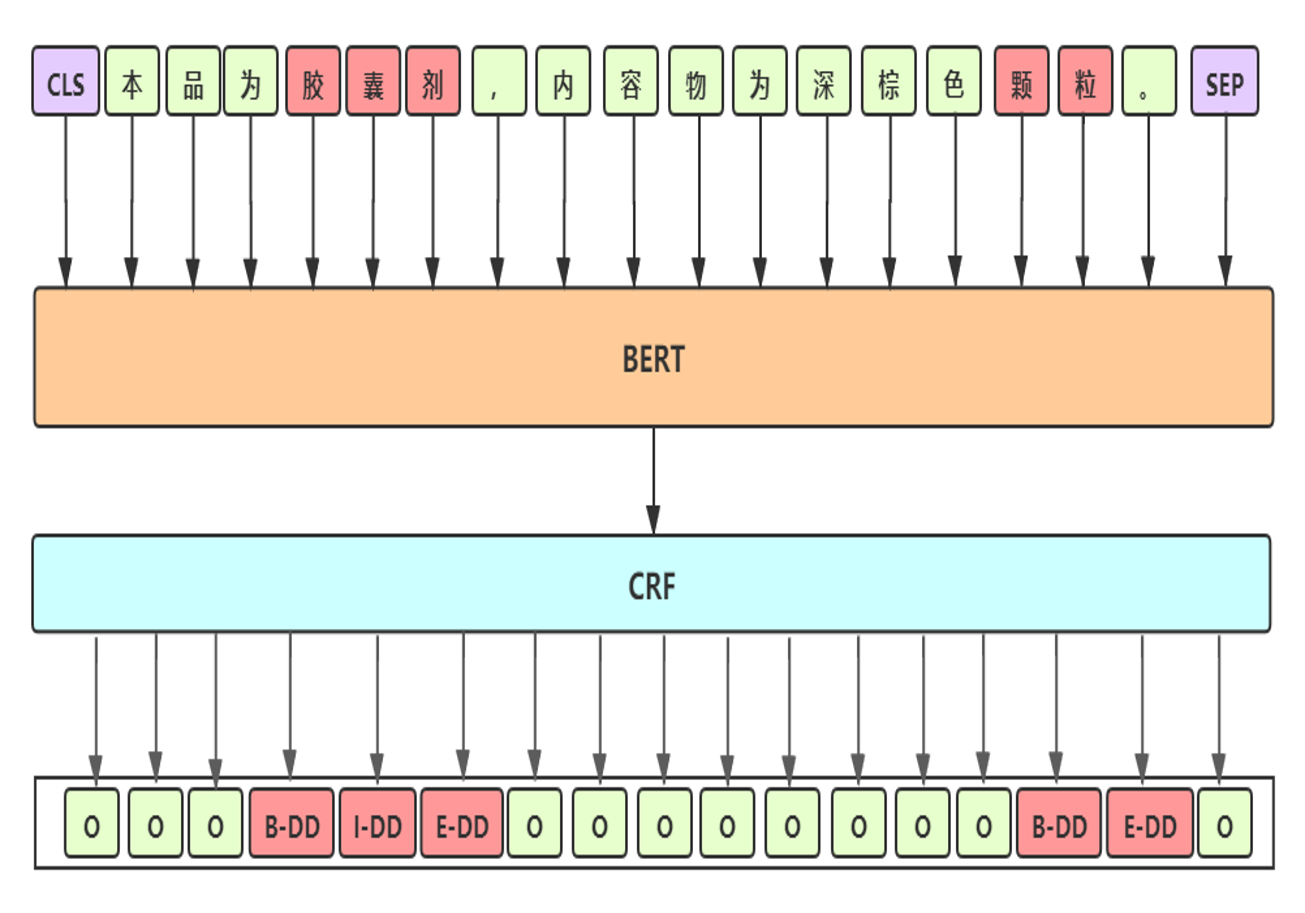
- Baseline 细节
- 预训练模型:选用 UER-large-24 layer[1],UER在RoBerta-wwm 框架下采用大规模优质中文语料继续训练,CLUE 任务中单模第一
- 差分学习率:BERT层学习率2e-5;其他层学习率2e-3
- 参数初始化:模型其他模块与BERT采用相同的初始化方式
- 滑动参数平均:加权平均最后几个epoch模型的权重,得到更加平滑和表现更优的模型
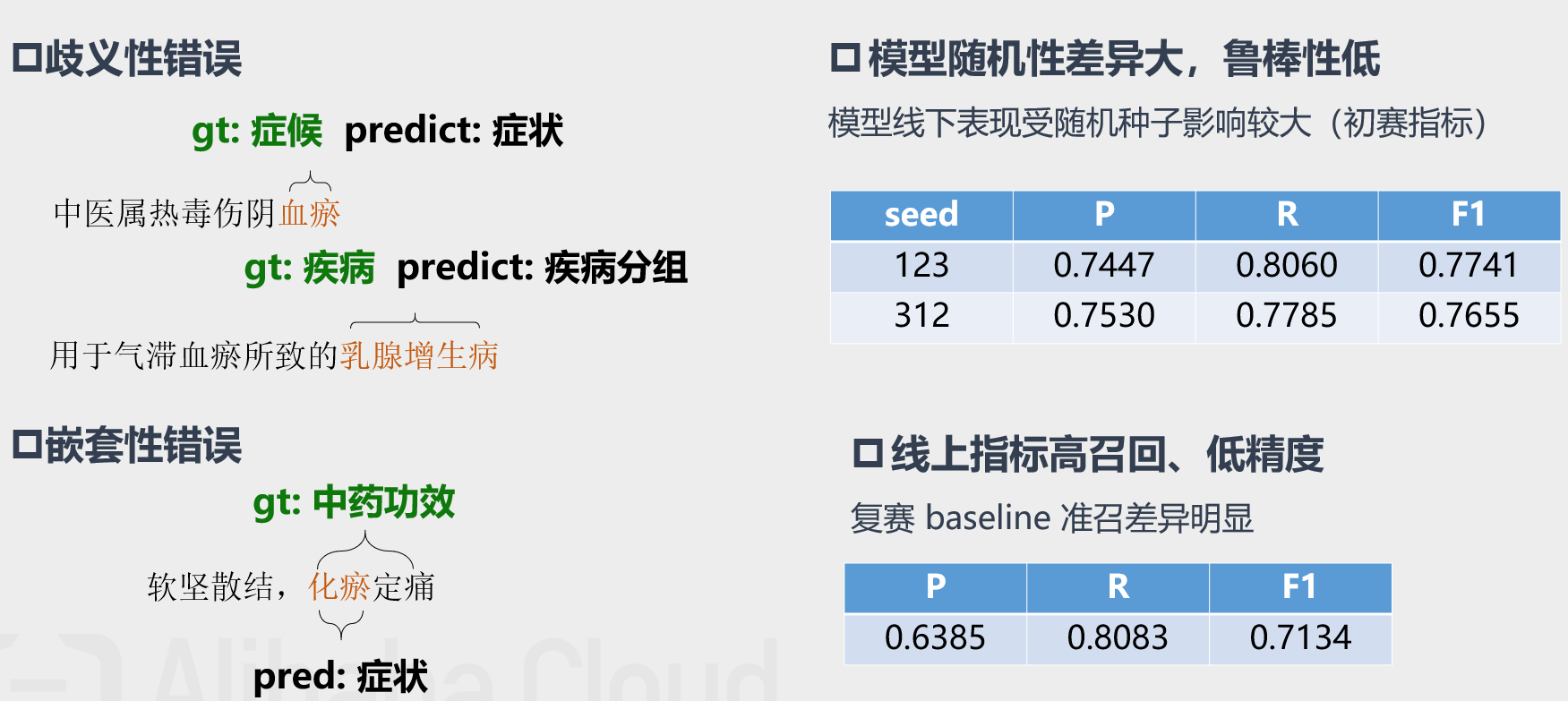
- Baseline bad-case分析
“万创杯”中医药天池大数据竞赛——中药说明书实体识别挑战_算法大赛_天池大赛-阿里云天池
中医药天池大数据竞赛--中药说明书实体识别挑战 | SiriBlog
NLP系列之实体识别/关系抽取(一):如何用BERT+CRF在比赛中获奖——天池中药说明书实体识别挑战亚军分享 - 知乎















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









