







1、SAM
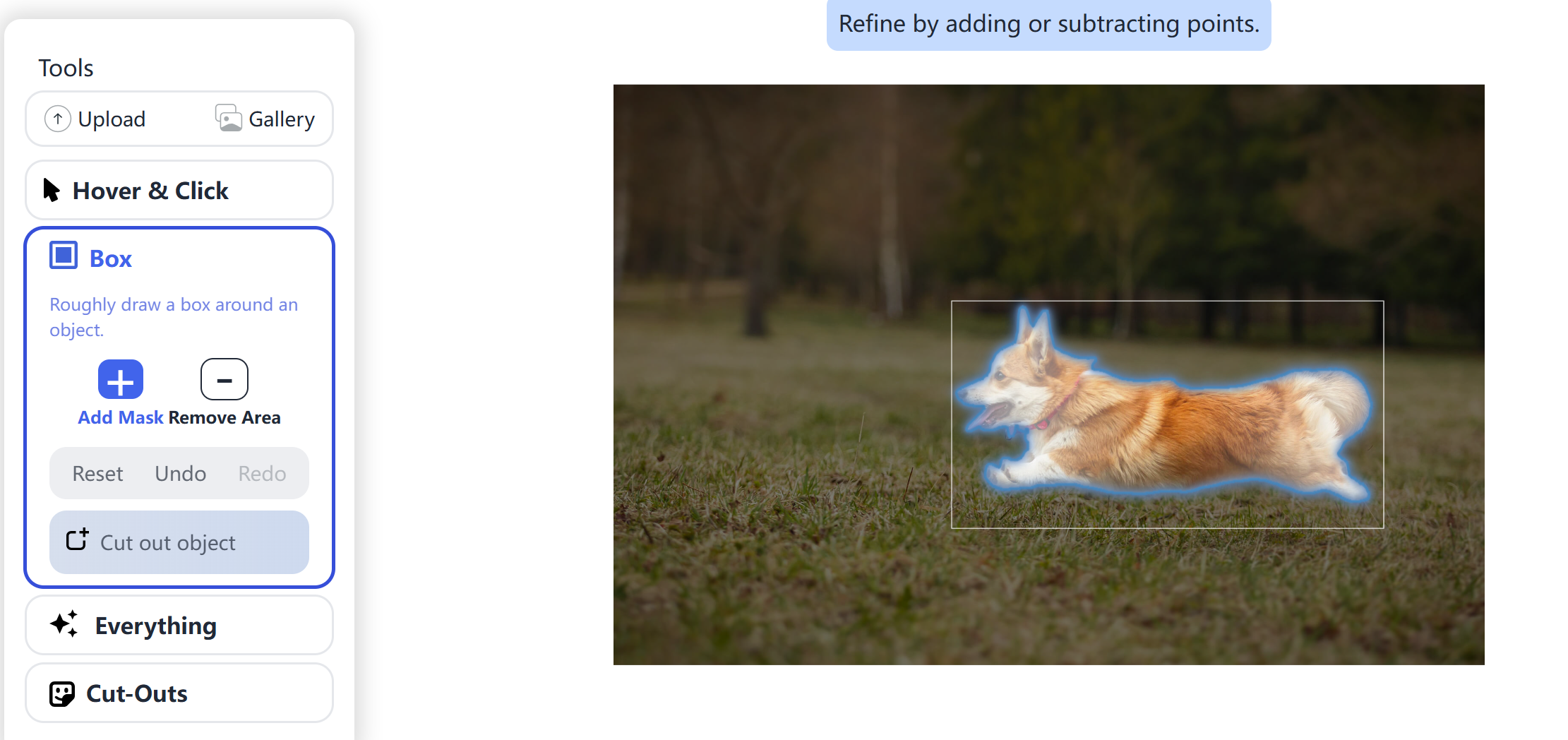

2、Grounded SAM
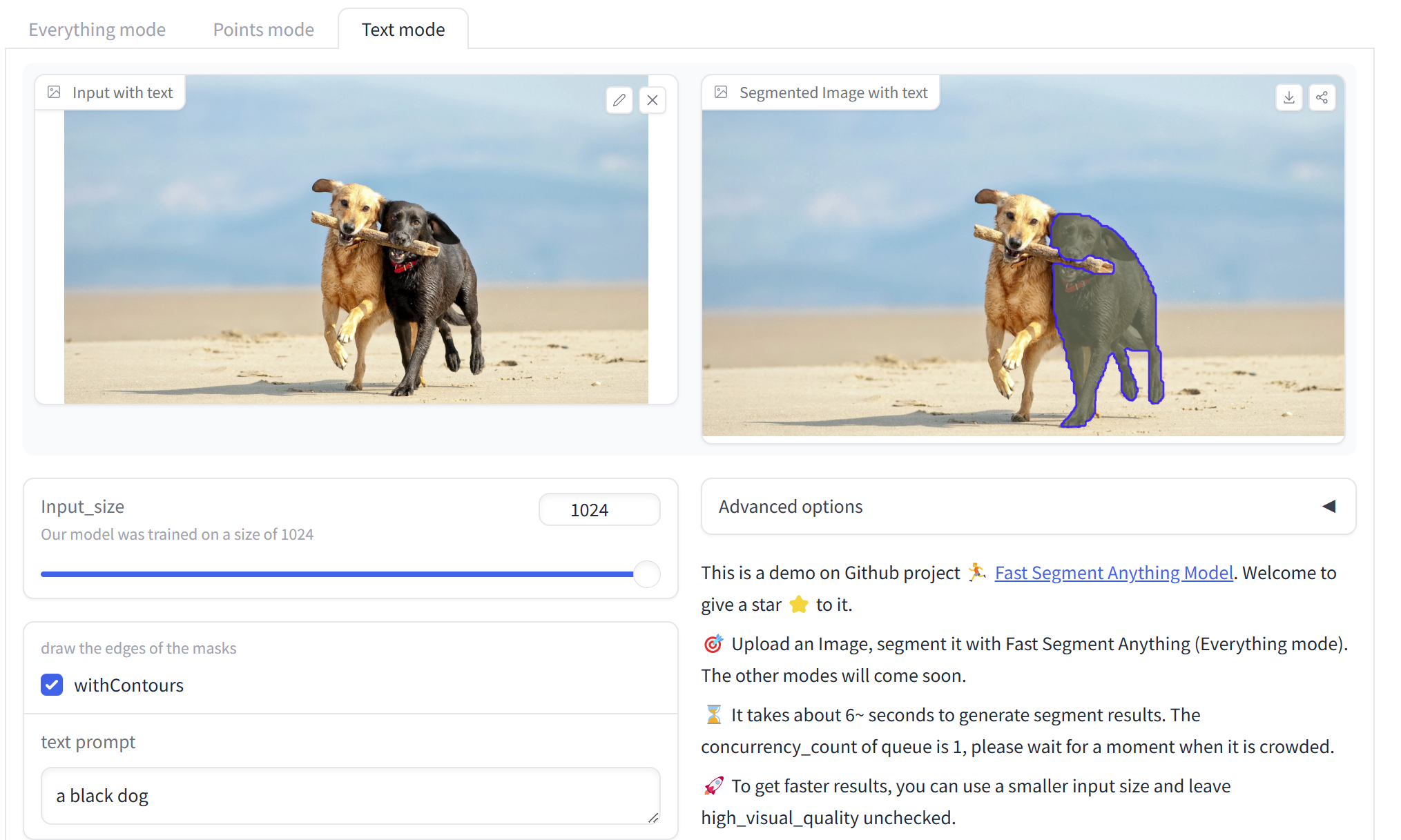
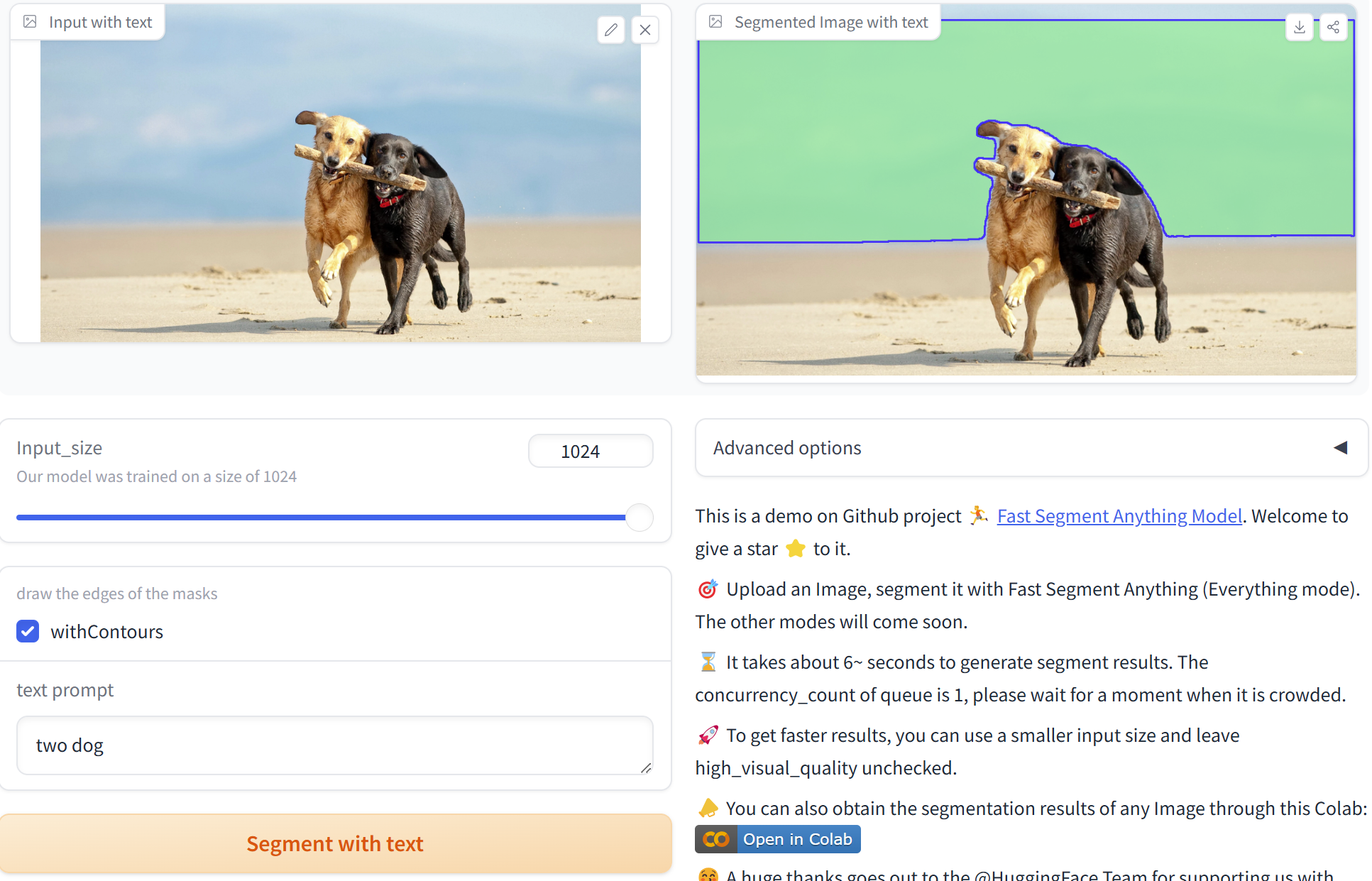
3、Grounding DINO 1.5
2023年,IDEA研究院CVR团队在GitHub上推出了广受关注的开集检测模型Grounding DINO和能检测、分割一切的Grounded SAM。这些开源模型被国内外很多团队用于各类视觉及多模态应用中。
网络结构大致如下:
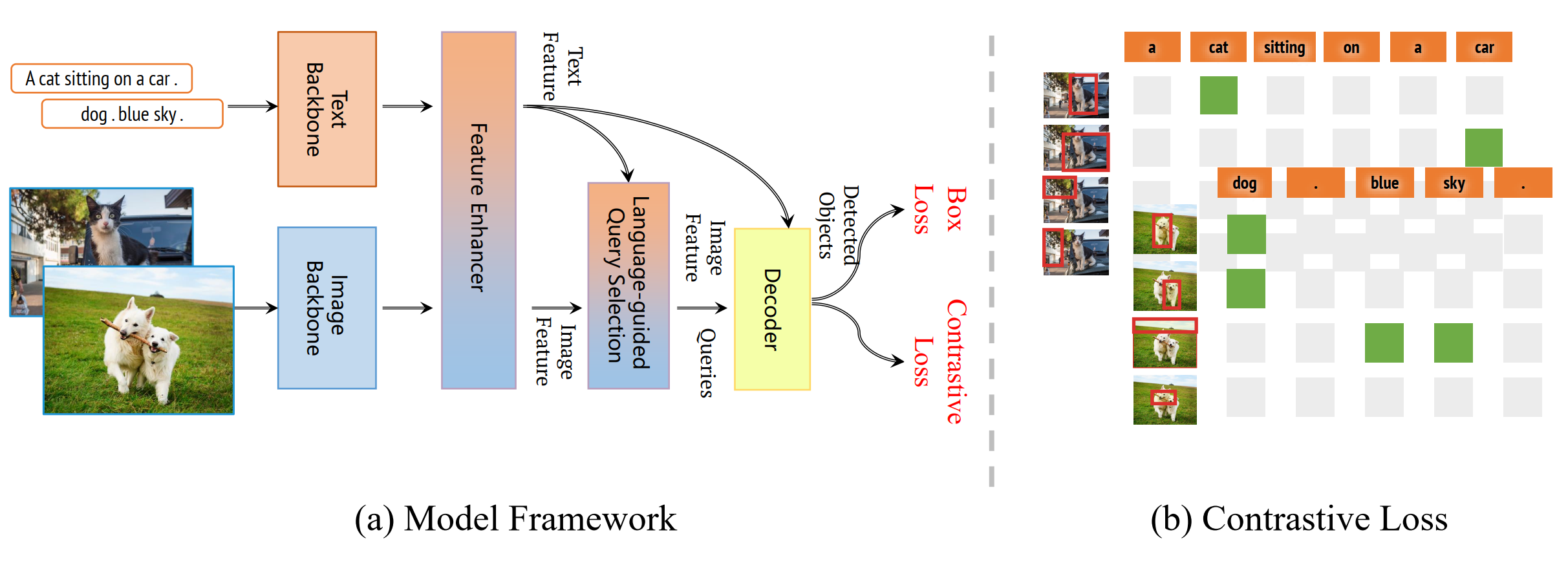
近日,该团队推出全新升级版Grounding DINO 1.5。模型分为Pro和Edge两个版本,尤其Edge版实现了端侧可部署的革命性突破,强力赋能具身智能、自动驾驶等新型应用场景。

文本输入,即时识别。Pro版更强,Edge版更快。
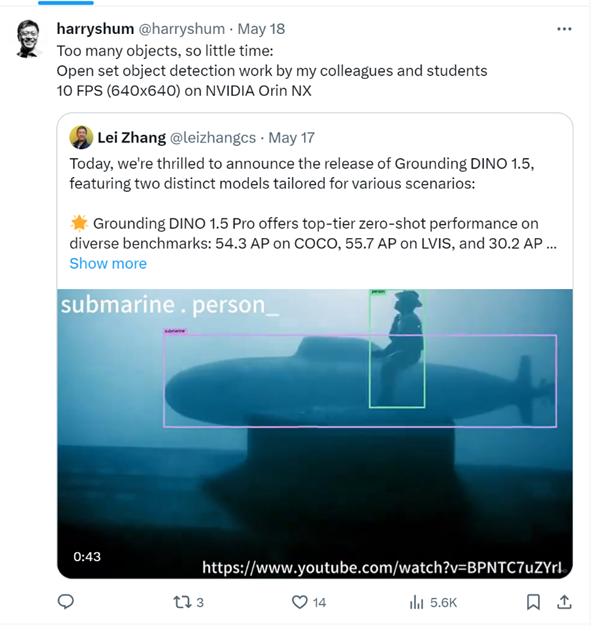
IDEA研究院创院理事长、美国工程院外籍院士、微软原全球执行副总裁沈向洋在社交媒体上推荐 Grounding DINO 1.5。
Grounding DINO 1.5 在其前身 Grounding DINO 的基础上,通过结合更大的视觉 backbone 扩大模型尺寸,并使用超过2000万的 Grounding 数据获得了丰富的语料,大幅提升了检测精度和速度,且通过Pro和Edge版本分别针对不同应用场景进行了优化。
Pro版本在大规模数据集构建和高精度需求场景中表现卓越,而Edge版本则在端侧部署中展示了其独特的优势。
PRO版
最强的开源检测模型,
刷新多个Benchmark
Grounding DINO 1.5 Pro版本实现了当前开集目标检测的最先进水平(SOTA),在图像和文本的语义理解上表现出色,能够快速、准确地根据语言提示检测和识别图像中的目标对象。
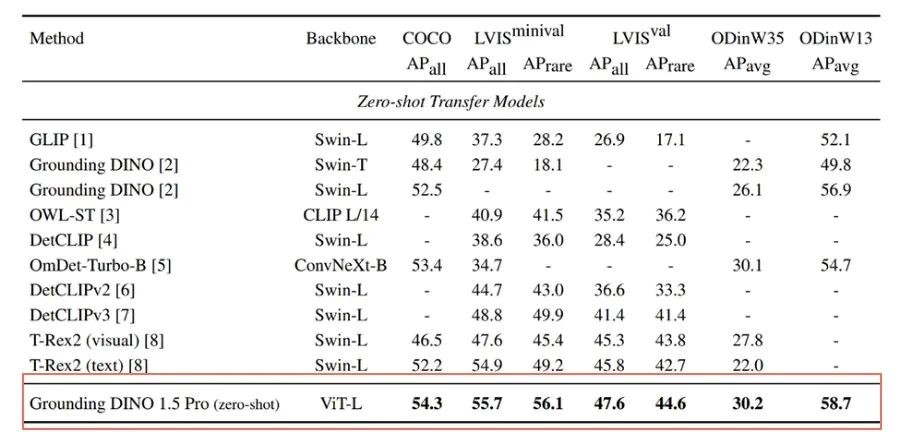
Grounding DINO 1.5 Pro在COCO、LVIS、ODinW35和ODinW13基准测试中的零样本迁移性能对比。
物体级别理解是机器和物理世界交互的感知基础,也是解决多模态大模型(VLM)幻觉问题绕不过去的基础问题。 作为当前性能最好的开集检测模型,Grounding DINO 1.5 Pro 可以帮助构建海量的具有物体级别语义信息的多模态数据,从而有效地助力多模态大模型的训练。

Grounding DINO 1.5 将长文本描述中的短语与图像中的具体对象或场景精确匹配,以增强AI对视觉内容和文本之间关系的理解。
另外,在其他需要处理大量复杂数据的领域,如电商、社交媒体和自动驾驶等,Grounding DINO 1.5 Pro 也具有强大应用价值。
例如,在电商领域,该模型可以帮助快速标注商品图像,优化搜索和推荐系统。在社交媒体中,该模型能自动标注用户上传的图片,提升内容审核和分类的效率。
利用行业数据进行微调,
打造行业视觉大模型
Grounding DINO 1.5 Pro不仅在基础性能上表现卓越,还支持通过行业数据进行微调(fine tuning),以满足各行业的特定需求,从而达到更加精准的识别效果。
为了验证微调带来的提升,CVR团队在视觉领域通用的LVIS等公开数据集上进行了对比实验。
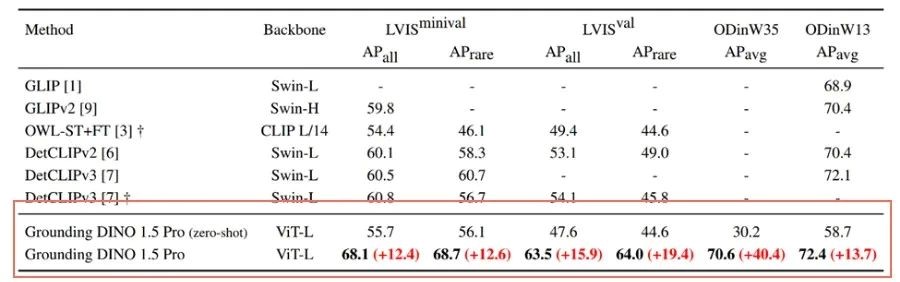
从最后两行可看出,Grounding DINO 1.5 Pro经过微调,在多个数据集上都展现出大幅的性能提升。

模型轻松适应多个实际场景的识别任务。
例如,在医疗领域,通过微调后的Grounding DINO 1.5 Pro可以更准确地识别医疗影像中的病灶,辅助医生进行诊断,提高诊疗效率。在零售行业,微调后的模型能更精准地识别和分类商品,有助于库存管理和销售分析。
这样的定制化能力,使得Grounding DINO 1.5 Pro能为各行业赋能,推动行业智能化转型,提升整体竞争力。
Edge版
最快的开集检测模型,
突破性实现端侧部署
在端侧部署方面,Grounding DINO 1.5 Edge版本展现了其独特的优势。通过模型结构优化,成功部署在NVIDIA Orin NX卡上,并实现了10FPS的推理速度。相比业界现有的其它模型,Grounding DINO 1.5 Edge的这一能力尚属首创,为大模型的端侧部署开辟了新的领域。

NVIDIA Orin NX卡部署Grounding DINO 1.5 Edge 实拍。
例如,在目前最火爆的具身智能领域,在端侧部署的开集检测模型可以使机器人真正和开放环境进行交互。在自动驾驶领域,Grounding DINO 1.5 Edge未来可以在车辆上实时运行,实现高效的目标检测和环境感知,提高驾驶安全性。在智能安防中,该模型能快速处理视频监控数据,实时检测异常行为,提升安全监控的响应速度。
Grounding DINO 1.5 Edge部署在端侧后执行目标检测任务实拍。区分真假植物轻松无压力。
4、T-Rex2模型
视觉与文本融合提示,超强跨图目标检测
继去年11月在2023 IDEA 大会上推出基于视觉提示的开集检测模型 T-Rex 后,IDEA 研究院团队又携重磅新作归来:视觉与文本提示相互融合,打造超强跨图能力,向通用目标检测更进一步!
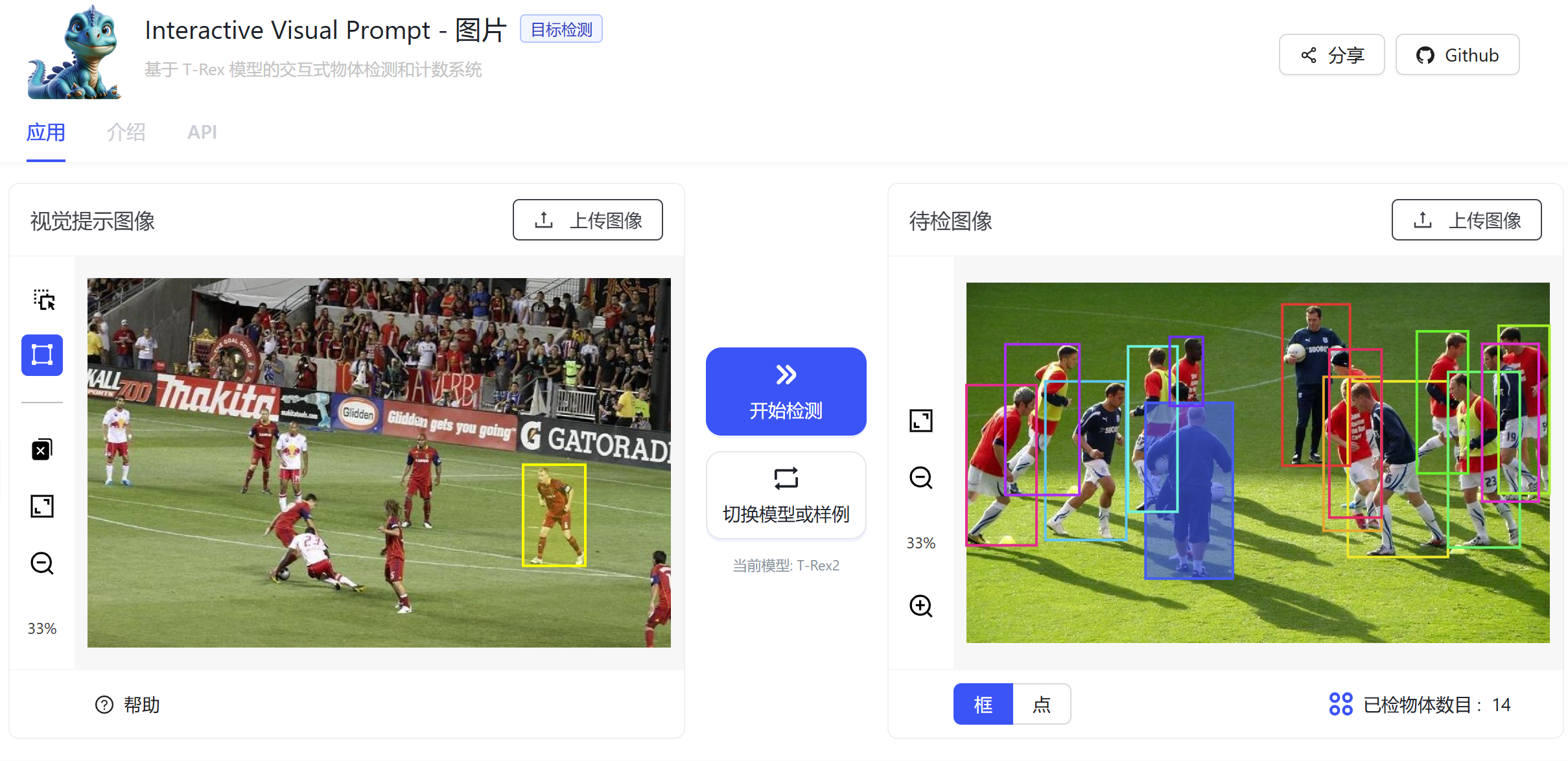
T-Rex2具有超强的跨帧与跨图检测能力,只需在一张图片或帧上进行视觉提示,就能在其他图片上进行检测。
拉框、检测、完成!在实际工业应用中,常见的需求是在⼀张或多张图像上进行视觉提示,然后在其他图像上使用这个视觉提示进行检测。这个即是跨图检测能力。
这个关键能力,让目标检测技术在生产生活中可以真正开始广泛应用。如工业生产流水线器件检测,交通航运领域的船舶、飞机检测,农业领域的农作物、果蔬检测,生物医学领域的细胞、组织检测,物流领域的货物检测,环境领域的野生动物监测等。
IDEA研究院CVR团队最新发布T-Rex2模型,通过视觉与文本提示的互相融合,弥补视觉提示的一些关键缺陷,实现流畅可用的跨图目标检测。与多目标跟踪模型结合后,T-Rex2还可以轻松应用于各种视频检测任务。
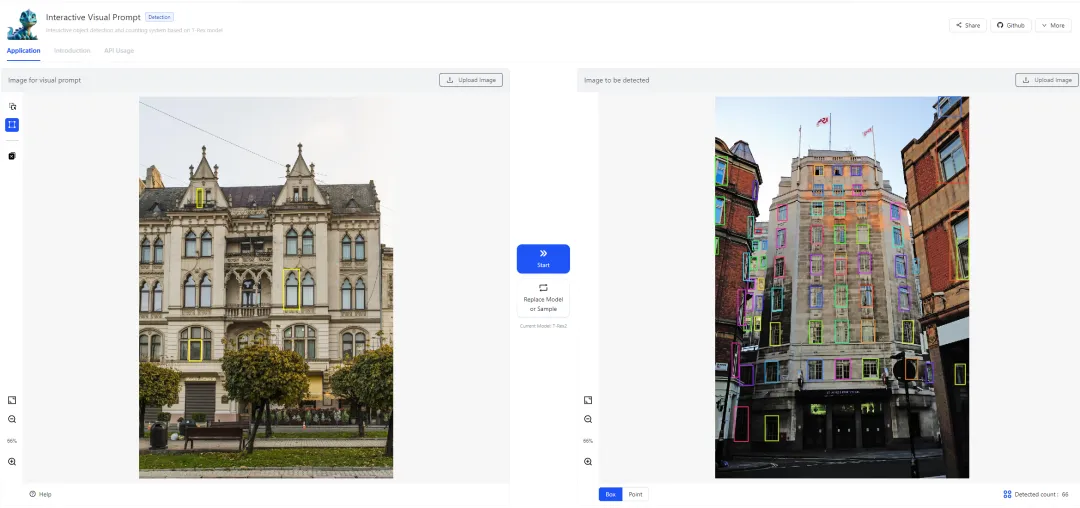
T-Rex2图像检测应用展示。

T-Rex2视频检测应用展示。
文本与视觉提示融合
在开集目标检测领域,利用文本提示进行开放词汇目标检测已是⼀种流行做法。尽管文本提示受到广泛青睐,但它仍有一些局限性:
►长尾数据短缺。文本提示的训练需要和视觉模态之间的模态对齐,但长尾对象(即稀有或者全新的物体类别)的数据稀缺可能会削弱其学习效率。
►描述上的局限性。对于一些难以用语言描绘的对象,因受限于无法精确描述,也会削弱文本提示的效果。比如对于一些细菌或者微生物,如果没有专业的领域知识,用户是无法用文本来进行准确描绘的。

文本提示示意
相反,视觉提示提供了一种更直观、更直接的对象表示方法。例如,即使用户不知道待检测目标的类别或名称,也可以使用点或框来标记待检测的对象。然而,视觉提示也有其局限性。与文本提示相比,它们在捕捉常见对象的概念时效果较差。
例如,在文本提示里,“狗”这个字已经可以广泛涵盖所有狗的品种。相比之下,对于视觉提示,需要有多样化的狗的照片,体现不同的品种、大小和颜色等等,才能完整地传达“狗”这个概念。

视觉提示示意
T-Rex2通过在一个模型中同时整合文本和视觉提示,克服了这两种提示模态各自的局限,并利用了两种模态的优势。
文本和视觉提示的协同作用赋予了T-Rex2 强大的跨图检测能力和零样本能力。
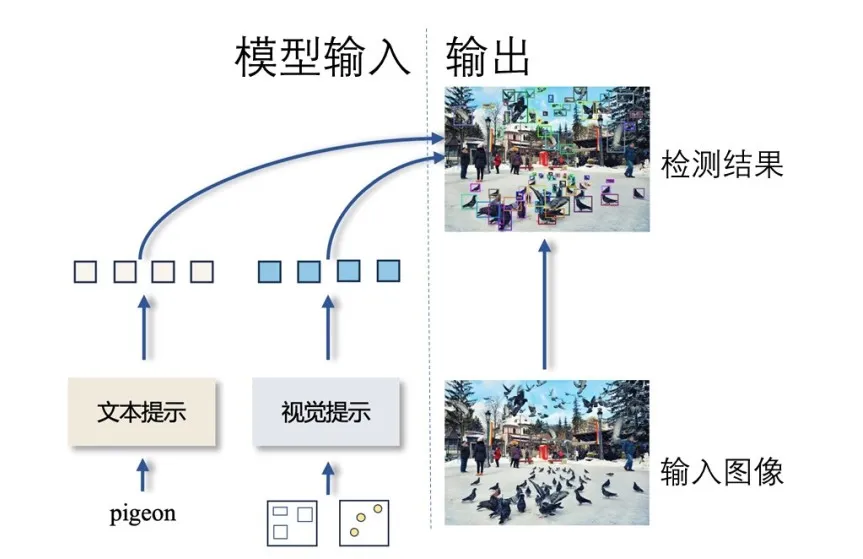
T-Rex2模型结构简化图
在跨图检测任务中,T-Rex2 可以在一张图像上进行视觉提示,然后在其他图像上使用这个视觉提示进行检测。这种能力使得 T-Rex2 在实际应用中更加灵活,能够适应更多的检测场景。
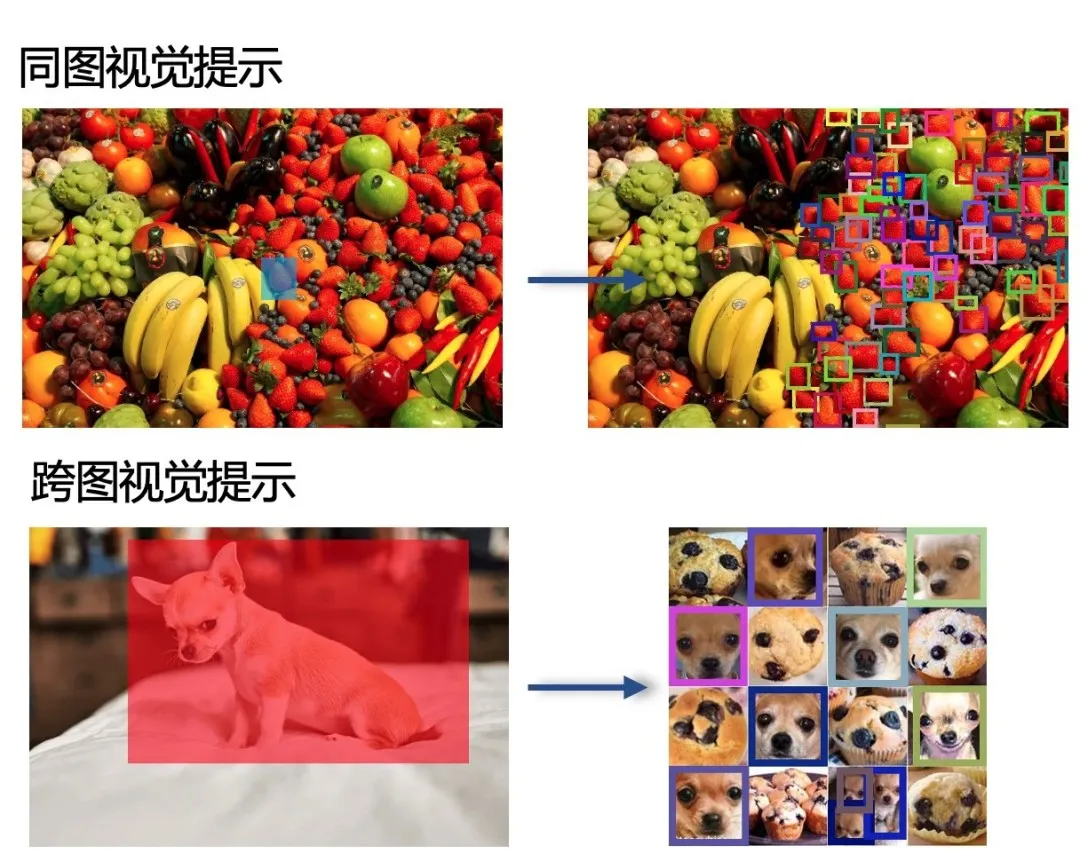
同图识别(Intra-image recognition)是指在单个图像内部识别和分类对象的任务。跨图识别(Inter-image recognition)是指在多个图像之间识别相同或不同对象的任务。
同图识别需要算法能够准确地在复杂的环境中识别和分割多个对象,而跨图识别则需要算法具备更强的泛化能力和对细节的敏感度,以便在不同的图像条件下识别和比较对象。

T-Rex2跨图检测能力示例。
支持多种工作模式
►文本提示模式:完全依靠文本提示进行物体检测,与开放词汇物体检测的方法相同。这适合于常见物体的检测。

►交互式视觉提示模式:用户与模型直接互动,即是“human in the loop”的概念。比如可以自己画点、画框来标记检测物体,然后根据模型输出的反馈来修正检测结果,如增加额外的提示。这是近年较为新颖的模式。

►通用视觉提示模式:用户可以通过向模型提供任意数量的示例图片来自定义特定对象的视觉嵌入,然后使用这个嵌入来检测任意图像中的对象,是不需要“human in the loop”。
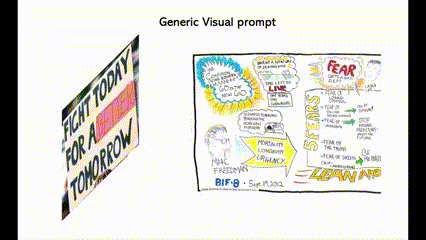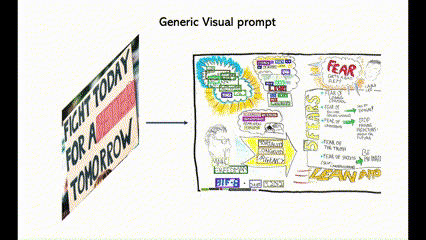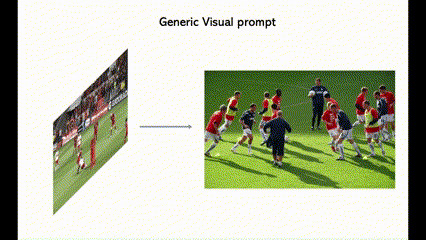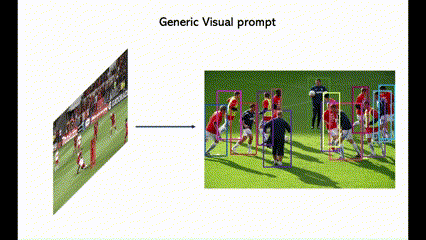
4个零样本SOTA
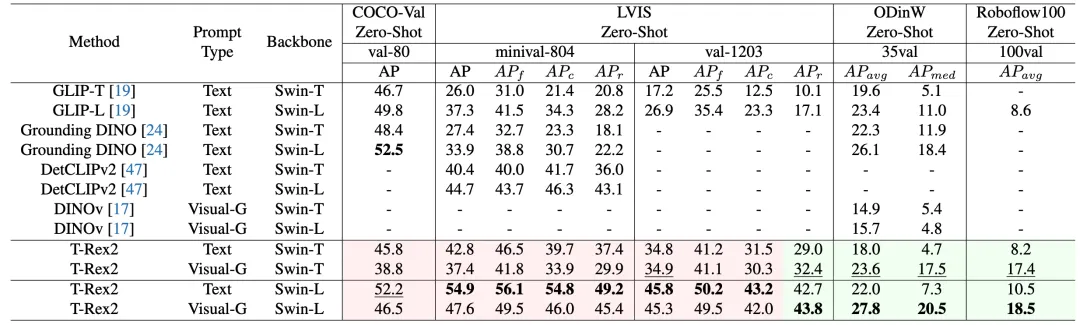
T-Rex2 性能表现
T-Rex2 在四个学术基准测试集 COCO, LVIS, ODinW, 和Roboflow100 上取得了 Zero-Shot SOTA的性能。从指标上来看,文本提示和视觉提示分别在不同的场景下表现优异。
文本提示在相对常见类别的场景中表现优异,而视觉提示在长尾分布的场景中表现更加稳健。这也说明将这两种提示模态结合起来,能让模型更好地适应不同的场景。
开箱即用
T-Rex2具备极强的开箱即用特性,无需重新训练或微调,即可检测模型在训练阶段从未见过的物体。该模型不仅可应用于包括计数在内的所有检测类任务,还为智能交互标注领域提供新的解决方案。

T-Rex2 在各种应⽤场景下的检测效果
T-Rex2还可用于视频目标跟踪。在T-Rex2 跨图逐帧的检测结果上,我们可以用现有的多目标跟踪模型( 如ByteTrack ) 追踪检测物体。这让T-Rex2可以轻松应用于各种视频检测任务。
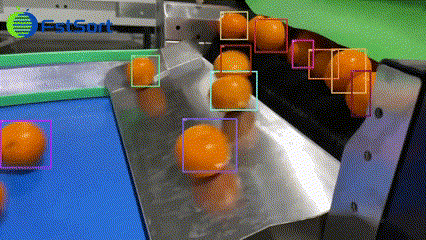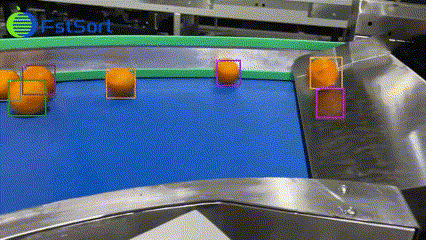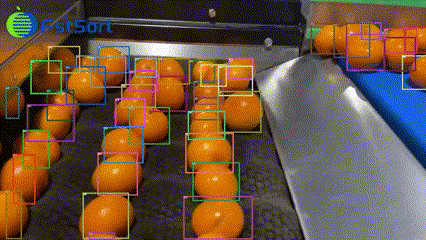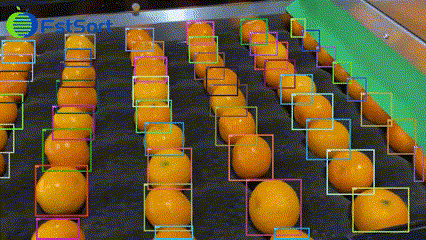
T-Rex2视频检测能力示例。
T-Rex2标志着我们向通用物体检测又迈出了新的一步。

















 1258
1258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









