







推荐系统实践读书笔记-03冷启动问题
推荐系统需要根据用户的历史行为和兴趣预测用户未来的行为和兴趣,因此大量的用户行为数据就成为推荐系统的重要组成部分和先决条件。对于很多像百度、当当这样的网站来说,这或许不是个问题,因为它们目前已经积累了大量的用户数据。但是对于很多做纯粹推荐系统的网站(比如Jinni和Pandora),或者很多在开始阶段就希望有个性化推荐应用的网站来说,如何在没有大量用户数据的情况下设计个性化推荐系统并且让用户对推荐结果满意从而愿意使用推荐系统,就是冷启动的问题。
下面各节将简单介绍一下冷启动问题的分类,以及如何解决不同种类的冷启动问题。
3.1 冷启动问题简介
冷启动问题(cold start)主要分3类。
用户冷启动 用户冷启动主要解决如何给新用户做个性化推荐的问题。当新用户到来时,我们没有他的行为数据,所以也无法根据他的历史行为预测其兴趣,从而无法借此给他做个性化推荐。
物品冷启动 物品冷启动主要解决如何将新的物品推荐给可能对它感兴趣的用户这一问题。
系统冷启动 系统冷启动主要解决如何在一个新开发的网站上(还没有用户,也没有用户行为,只有一些物品的信息)设计个性化推荐系统,从而在网站刚发布时就让用户体验到个性化推荐服务这一问题。
对于这3种不同的冷启动问题,有不同的解决方案。一般来说,可以参考如下解决方案。
提供非个性化的推荐 非个性化推荐的最简单例子就是热门排行榜,我们可以给用户推荐热门排行榜,然后等到用户数据收集到一定的时候,再切换为个性化推荐。
利用用户注册时提供的年龄、性别等数据做粗粒度的个性化。
利用用户的社交网络账号登录(需要用户授权),导入用户在社交网站上的好友信息,然后给用户推荐其好友喜欢的物品。
要求用户在登录时对一些物品进行反馈,收集用户对这些物品的兴趣信息,然后给用户推荐那些和这些物品相似的物品。
对于新加入的物品,可以利用内容信息,将它们推荐给喜欢过和它们相似的物品的用户。
在系统冷启动时,可以引入专家的知识,通过一定的高效方式迅速建立起物品的相关度表。
下面几节将详细描述其中的某些方案
3.2 利用用户注册信息
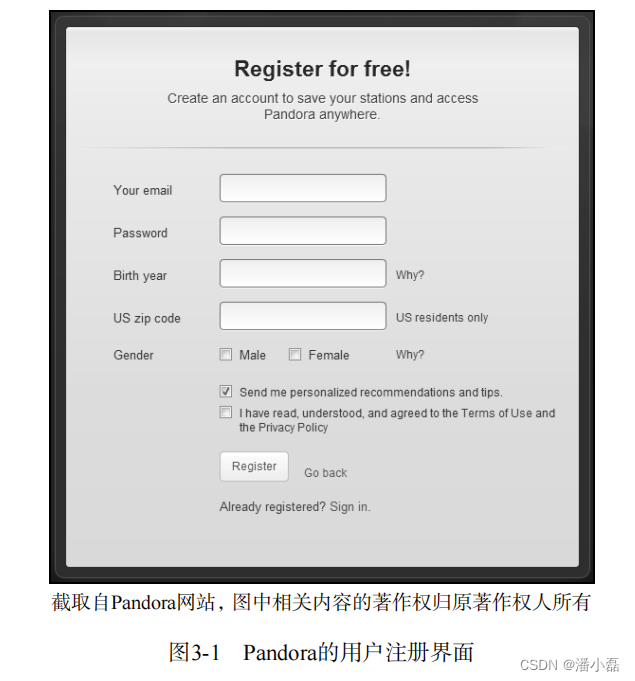
在网站中,当新用户刚注册时,我们不知道他喜欢什么物品,于是只能给他推荐一些热门的商品。但如果我们知道她是一位女性,那么可以给她推荐女性都喜欢的热门商品。这也是一种个性化的推荐。当然这个个性化的粒度很粗,因为所有刚注册的女性看到的都是同样的结果,但相对于不区分男女的方式,这种推荐的精度已经大大提高了。因此,利用用户的注册信息可以很好地解决注册用户的冷启动问题。在绝大多数网站中,年龄、性别一般都是注册用户的必备信息。如3-1所示,个性化电台Pandora的注册界面就要求用户提供生日、邮编和性别等数据。Pandora在解释为什么需要这些数据时表示是为了让用户能够看到和自己更加相关的广告。其实,这些数据也可以用于解决用户听音乐的冷启动问题。
用户的注册信息分3种。
人口统计学信息 包括用户的年龄、性别、职业、民族、学历和居住地。
用户兴趣的描述 有一些网站会让用户用文字描述他们的兴趣。
从其他网站导入的用户站外行为数据 比如用户通过豆瓣、新浪微博的账号登录,就可以在得到用户同意的情况下获取用户在豆瓣或者新浪微博的一些行为数据和社交网络数据。
这一节主要讨论如何通过用户注册时填写的人口统计学信息给用户提供粗粒度的个性化推荐。
人口统计学特征包括年龄、性别、工作、学历、居住地、国籍、民族等,这些特征对预测用户的兴趣有很重要的作用,比如男性和女性的兴趣不同, 不同年龄的人兴趣也不同。图3-2显示了IMDB(IMDB网站中给出了每一部电影和电视剧的评分人数按照年龄和性别分布的数据①)中给著名美剧评分的男女用户数的比例。这幅图中的数据只代表IMDB用户观看电视剧的性别分布,因为IMDB网站用户的性别分布本身是不均匀的(男性用户较多)。如图3-2所示,用户选择电视剧的行为和性别有很大的相关性,有些电视剧(比如《实习医生格雷》和《绝望主妇》)比较受女性的欢迎,而一些电视剧(比如《生活大爆炸》和《荒野求生》)则比较受男性的欢迎。
基于人口统计学特征的推荐系统其典型代表是Bruce Krulwich开发的Lifestyle Finder②。首先,Bruce Krulwich将美国人群根据人口统计学属性分成62类,然后对于每个新用户根据其填写的个人资料判断他属于什么分类,最后给他推荐这类用户最喜欢的15个链接,其中5个链接是推荐他购买的商品,5个链接是推荐他旅游的地点,剩下的5个链接是推荐他去逛的商店。

为了证明利用用户人口统计学特征后的推荐结果好于随机推荐的结果,Krulwich做了一个AB测试。相对于利用人口统计学特征的算法,Krulwich设计了一个对照组,该组用户看到的推荐结果是完全随机的。实验结果显示,对于利用人口统计学特征的个性化推荐算法,其用户点击率为89%,而随机算法的点击率只有27%。对于利用人口统计学特征的个性化算法,44%的用户觉得推荐结果是他们喜欢的,而对于随机算法只有31%的用户觉得推荐结果是自己喜欢的。因此,我们得到一个结论——使用人口统计学信息相对于随机推荐能够获得更好的推荐效果。当然,Krulwich的实验也有明显的缺点,即他没有对比和给用户推荐最热门的物品的推荐算法。因为热门排行榜作为一种非个性化推荐算法,一般也比随机推荐具有更高的点击率。
基于注册信息的个性化推荐流程基本如下:
(1) 获取用户的注册信息;
(2) 根据用户的注册信息对用户分类;
(3) 给用户推荐他所属分类中用户喜欢的物品。
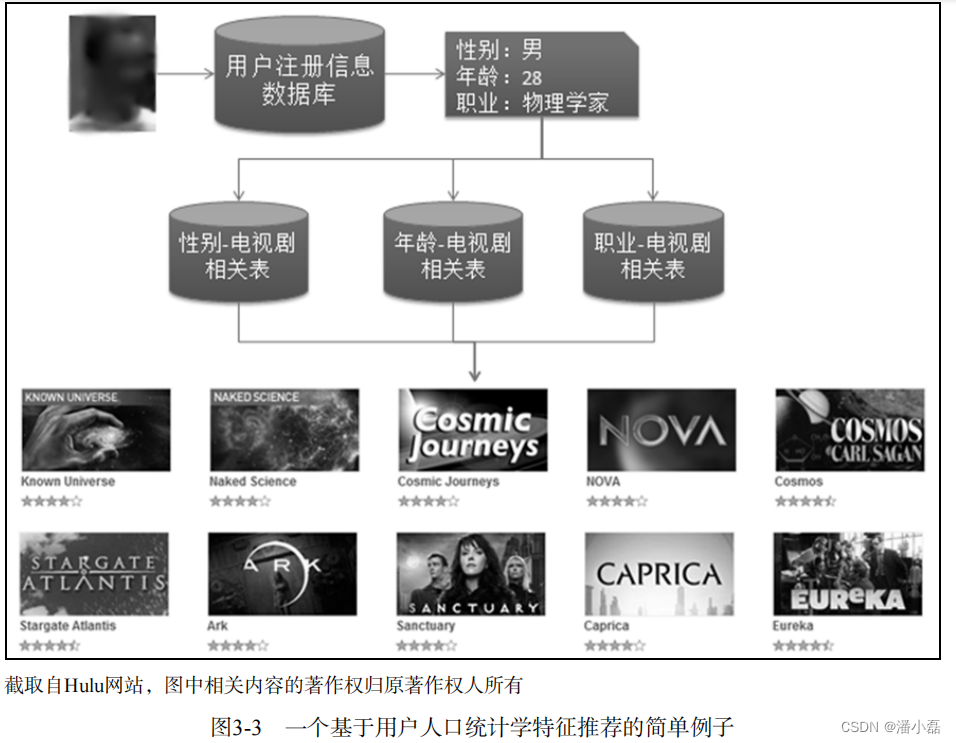
图3-3是一个基于用户人口统计学特征推荐的简单例子。如图所示,当一个新的注册用户访问推荐系统时,我们首先从用户注册信息数据库中查询他的注册信息。比如图3-3中的用户,我们查到他是一位28岁的男性,是一位物理学家。然后,查询3张离线计算好的相关表:一张是性别-电视剧相关表,从中可以查询男性最喜欢的电视剧;一张是年龄-电视剧相关表,从中可以查询到28岁用户最喜欢的电视剧;一张是职业-电视剧相关表,可以查询到物理学家最喜欢的电视剧。然后,我们可以将用这3张相关表查询出的电视剧列表按照一定权重相加,得到给用户的最终推荐列表。
当然,实际应用中也可以考虑组合特征,比如将年龄性别作为一个特征,或者将性别职业作为一个特征。不过在使用组合时需要注意用户不一定具有所有的特征(比如有些用户没有职业信息),因为一般的注册系统并不要求用户填写所有注册项。
由图3-3中的例子可知,基于用户注册信息的推荐算法其核心问题是计算每种特征的用户喜欢的物品。也就是说,对于每种特征f,计算具有这种特征的用户对各个物品的喜好程度p(f, i)。
p(f,i) 可以简单地定义为物品i在具有f的特征的用户中的热门程度:
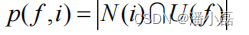
其中 N(i) 是喜欢物品i的用户集合,U (f ) 是具有特征f的用户集合。
上面这种定义可以比较准确地预测具有某种特征的用户是否喜欢某个物品。但是,在这种定义下,往往热门的物品会在各种特征的用户中都具有比较高的权重。也就是说具有比较高的 N(i)的物品会在每一类用户中都有比较高的 p(f,i) 。给用户推荐热门物品并不是推荐系统的主要任务,推荐系统应该帮助用户发现他们不容易发现的物品。因此,我们可以将 p(f,i) 定义为喜欢物品i的用户中具有特征f的比例:
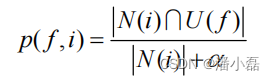
这里分母中使用参数α 的目的是解决数据稀疏问题。比如有一个物品只被1个用户喜欢过,而这个用户刚好就有特征f,那么就有 p(f,i)=1。但是,这种情况并没有统计意义,因此我们为分母加上一个比较大的数,可以避免这样的物品产生比较大的权重。
有两个推荐系统数据集包含了人口统计学信息,一个是BookCrossing数据集,另一个是Lastfm数据集。
BookCrossing数据集包含用户对图书的行为信息,包含3个文件。
BX-Users.csv,包含用户的ID、位置和年龄。
BX-Books.csv,包含图书的ISBN、标题、作者、发表年代、出版社和缩略。
BX-Book-Ratings.csv,包含用户对图书的评分信息。
下面我们根据这个数据集研究一下年龄对用户喜欢图书的影响。我们研究两类用户,一类是小于25岁的,一类是大于50岁的。
首先,我们利用p(f,i)统计了这两部分用户最经常看的书,并将每一类用户最经常看的5本书显示在表3-1中。同时我们也利用p(f,i)计算了年轻用户比例最高的5本书和老年用户比例最高的5本书(如表3-2所示)。我们可以看到,表3-1中年轻用户和老年用户最热门的5本书有3本是相同的,重合度很高。这3本书其实是老少咸宜的。在年轻人最喜欢的书中,只有《哈利波特和魔法石》(Harry Potter and the Sorcerer’s Stone)和《麦田里的守望者》(The Catcher in the Rye)是比较符合年轻人兴趣的。而在老年用户喜欢的书中,似乎没有特别能反映老年用户特点的书。由此可见p(f,i) 很难用来给用户推荐符合他们特征的个性化物品.
不过观看表3-2就可以发现,列表中推荐给年轻用户的书都是符合年轻人兴趣的,而推荐给老年人的书也是符合老年人兴趣的。
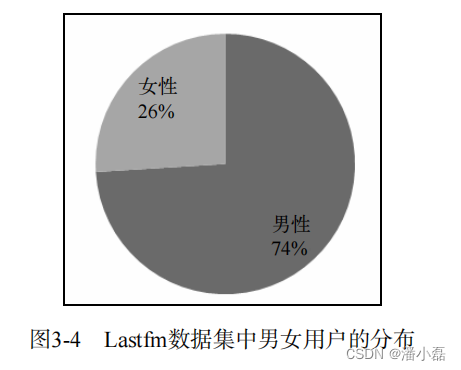
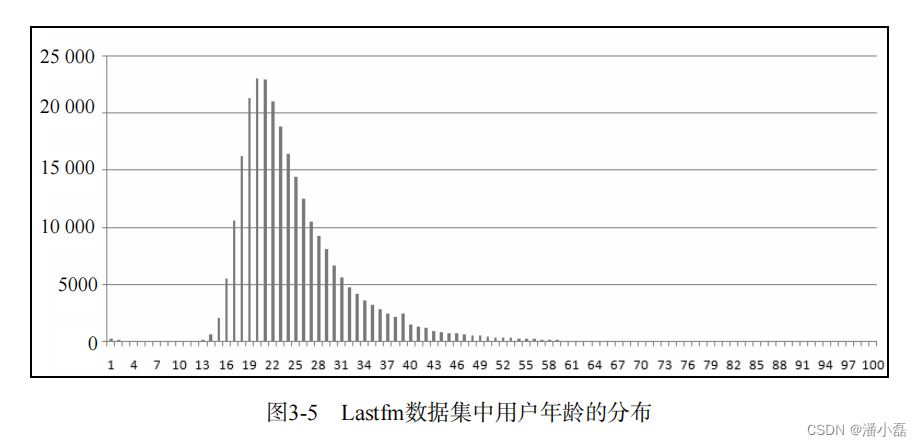
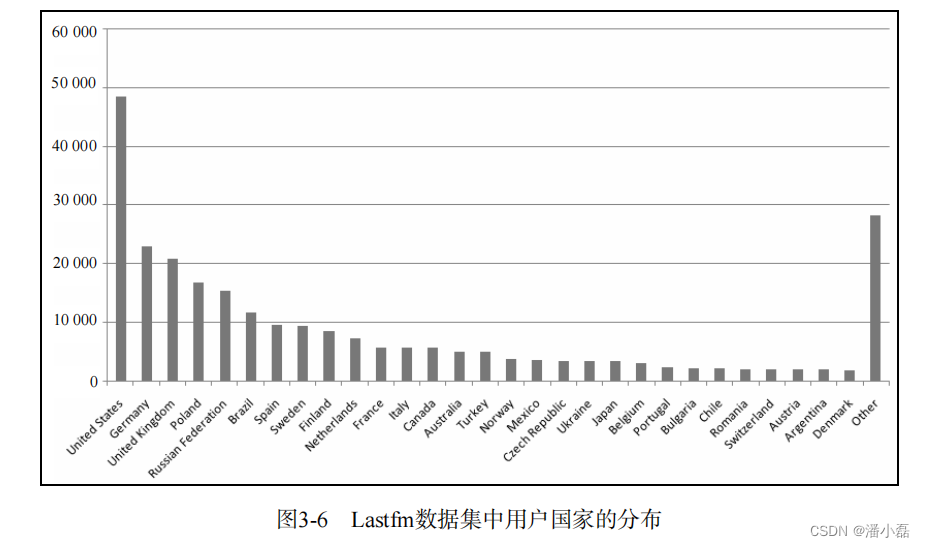
Lastfm数据集包含了更多的用户人口统计学信息,包括用户的性别、年龄和国籍。图3-4给出了该数据集中用户性别的分布。如图所示,该数据集中男性用户占了绝大多数(大约占3/4)。图3-5给出了该数据集中用户年龄的分布。如图所示,该数据集中20~25岁的用户占了绝大多数比例。图3-6给出了该数据集中用户国家的分布。如图所示,该数据集中美国、德国和英国的用户占了绝大多数比例。
我们准备用该数据集对比一下使用不同的人口统计学特征预测用户行为的精度。这里,我们将数据集划分成10份 ,9份作为训练集,1份作为测试集。然后,我们在训练集上利用p(f,i)=|N(i)∩U(f)| 计算每一类用户对物品的兴趣程度 p(f,i) 。然后在测试集中给每一类用户推荐 p(f,i) 最高的10个物品,并通过准确率和召回率计算预测准确度。同时,我们也会计算推荐的覆盖率来评测推荐结果。
我们按照不同的粒度给用户分类,对比了4种不同的算法。
MostPopular 给用户推荐最热门的歌手。
GenderMostPopular 给用户推荐对于和他同性别的用户最热门的歌手,这里我们将用户分成男女两类。
AgeMostPopular 给用户推荐对于和他同一个年龄段的用户最热门的歌手,这里我们将10岁作为一个年龄段,将用户按照不同的年龄段分类。
CountryMostPopular 给用户推荐对于和他同一个国家的用户最热门的歌手。
DemographicMostPopular 给用户推荐对于和他同性别、年龄段、国家的用户最热门的歌手。
从算法的描述可见,这4 种算法具有不同的粒度,其中 MostPopular粒度最粗,而DemographicMostPopular算法的粒度最细。一般说来,粒度越细,精度和覆盖率也会越高。
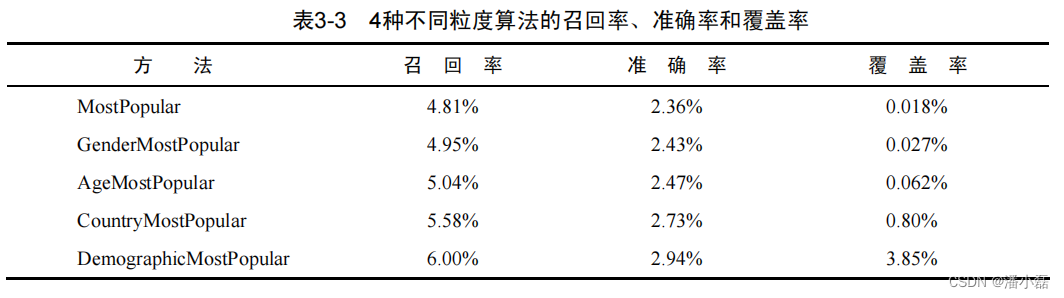
表3-3给出了实验结果。如结果所示,确实是DemographicMostPopular算法的准确率、召回率和覆盖率更高。这说明,利用的用户人口统计学特征越多,越能准确地预测用户兴趣。同时,结果显示:
DemographicMostPopular > CountryMostPopular > AgeMostPopular > GenderMostPopular > MostPopular
这说明在预测用户对音乐的兴趣时,国家比年龄、性别特征影响更大。这一点是显然的,比如中国的年轻人和美国的年轻人喜欢的音乐差异是很大的。
3.3 选择合适的物品启动用户的兴趣
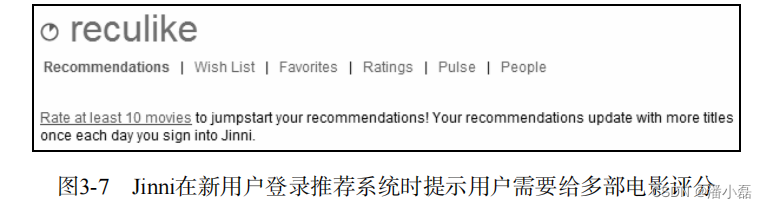
解决用户冷启动问题的另一个方法是在新用户第一次访问推荐系统时,不立即给用户展示推荐结果,而是给用户提供一些物品,让用户反馈他们对这些物品的兴趣,然后根据用户反馈给提供个性化推荐。很多推荐系统采取了这种方式来解决用户冷启动问题。以Jinni为例,当新用户访问推荐系统时,它会给出一条提示语,表示用户需要给多部电影评分才能获取推荐结果(如图3-7所示)。当用户选择给多部电影评分后,Jinni会首先展示一个页面让用户选择他喜欢的电影类别(如图3-8所示),当用户选择了某一个类别后,Jinni会展示第三个界面让用户对电影进行反馈(如图3-9所示)。

对于这些通过让用户对物品进行评分来收集用户兴趣,从而对用户进行冷启动的系统,它们需要解决的首要问题就是如何选择物品让用户进行反馈。一般来说,能够用来启动用户兴趣的物品需要具有以下特点。
比较热门 如果要让用户对一个物品进行反馈,前提是用户知道这个物品是什么东西。以电影为例,如果一开始让用户进行反馈的电影都很冷门,而用户不知道这些电影的情节和内容,也就无法对它们做出准确的反馈。

具有代表性和区分性 启动用户兴趣的物品不能是大众化或老少咸宜的,因为这样的物品对用户的兴趣没有区分性。还以电影为例,用一部票房很高且广受欢迎的电影做启动物品,可以想象的到的是几乎所有用户都会喜欢这部电影,因而无法区分用户个性化的兴趣。
启动物品集合需要有多样性 在冷启动时,我们不知道用户的兴趣,而用户兴趣的可能性非常多,为了匹配多样的兴趣,我们需要提供具有很高覆盖率的启动物品集合,这些物品能覆盖几乎所有主流的用户兴趣。以图3-8为例,Jinni在让用户反馈时没有直接拿电影让用户反馈,而是给出了12个电影类型(截图中只显示了其中的6个电影类型),让用户先选择喜欢哪种类型,这样就很好地保证了启动物品集合的多样性。
上面这些因素都是选择启动物品时需要考虑的,但如何设计一个选择启动物品集合的系统呢?Nadav Golbandi在论文①中探讨了这个问题,提出可以用一个决策树解决这个问题。
首先,给定一群用户,Nadav Golbandi用这群用户对物品评分的方差度量这群用户兴趣的一致程度。如果方差很大,说明这一群用户的兴趣不太一致,反之则说明这群用户的兴趣比较一致。令σu∈U’ 为用户集合U’中所有评分的方差,Nadav Golbandi的基本思想是通过如下方式度量一个物品的区分度D(i):
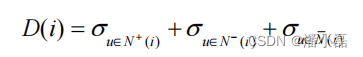
其中,N+(i) 是喜欢物品i的用户集合,N-(i) 是不喜欢物品i的用户集合, N–(i) 是没有对物品i评分的用户集合。σN+(i) 是喜欢物品i的用户对其他物品评分的方差,σN-(i)是不喜欢物品i的用户对其他物品评分的方差,σN–(i)是没有对物品i评分的用户对其他物品评分的方差。也就是说,对于物品i,Nadav Golbandi将用户分成3类——喜欢物品i的用户、不喜欢物品i的用户和不知道物品i的用户(即没有给i评分的用户)。如果这3类用户集合内的用户对其他的物品兴趣很不一致,说明物品i具有较高的区分度。
Nadav Golbandi的算法首先会从所有用户中找到具有最高区分度的物品i,然后将用户分成3类。然后在每类用户中再找到最具区分度的物品,然后将每一类用户又各自分为3类,也就是将总用户分成9类,然后这样继续下去,最终可以通过对一系列物品的看法将用户进行分类。而在冷启动时,我们从根节点开始询问用户对该节点物品的看法,然后根据用户的选择将用户放到不同的分枝,直到进入最后的叶子节点,此时我们就已经对用户的兴趣有了比较清楚的了解,从而可以开始对用户进行比较准确地个性化推荐。
图3-10通过一个简单的例子解释Nadav Golbandi的算法。如图所示,假设通过分析用户数据,我们发现《变形金刚》最有区分度。而在喜欢《变形金刚》的用户中《钢铁侠》最有区分度,不知道《变形金刚》的用户中《阿甘正传》最有区分度,不喜欢《变形金刚》的用户中《泰坦尼克号》最有区分度。进一步分析,我们发现不喜欢《变形金刚》但喜欢《泰坦尼克号》的用户中,《人鬼情未了》最有区分度。那么,假设来了一个新用户,系统会首先询问他对《变形金刚》的看法,如果他说不喜欢,我们就会问他对《泰坦尼克》号的看法,如果他说喜欢,我们就会问他对《人鬼情未了》的看法,如果这个时候用户停止了反馈,我们也大概能知道该用户可能对爱情片比较感兴趣,对科幻片兴趣不大。

3.4 利用物品的内容信息
物品冷启动需要解决的问题是如何将新加入的物品推荐给对它感兴趣的用户。物品冷启动在新闻网站等时效性很强的网站中非常重要,因为那些网站中时时刻刻都有新加入的物品,而且每个物品必须能够在第一时间展现给用户,否则经过一段时间后,物品的价值就大大降低了。
第2章介绍了两种主要的推荐算法——UserCF和ItemCF算法。首先需要指出的是,UserCF算法对物品冷启动问题并不非常敏感。因为,UserCF在给用户进行推荐时,会首先找到和用户兴趣相似的一群用户,然后给用户推荐这一群用户喜欢的物品。在很多网站中,推荐列表并不是给用户展示内容的唯一列表,那么当一个新物品加入时,总会有用户从某些途径看到这些物品,对这些物品产生反馈。那么,当一个用户对某个物品产生反馈后,和他历史兴趣相似的其他用户的推荐列表中就有可能出现这一物品,从而更多的人就会对这个物品产生反馈,导致更多的人的推荐列表中会出现这一物品,因此该物品就能不断地扩散开来,从而逐步展示到对它感兴趣用户的推荐列表中。
但是,有些网站中推荐列表可能是用户获取信息的主要途径,比如豆瓣网络电台。那么对于UserCF算法就需要解决第一推动力的问题,即第一个用户从哪儿发现新的物品。只要有一小部分人能够发现并喜欢新的物品,UserCF算法就能将这些物品扩散到更多的用户中。解决第一推动力最简单的方法是将新的物品随机展示给用户,但这样显然不太个性化,因此可以考虑利用物品的内容信息,将新物品先投放给曾经喜欢过和它内容相似的其他物品的用户。关于如何利用内容信息,本节将在后面介绍。
对于ItemCF算法来说,物品冷启动就是一个严重的问题了。因为ItemCF算法的原理是给用户推荐和他之前喜欢的物品相似的物品。ItemCF算法会每隔一段时间利用用户行为计算物品相似度表(一般一天计算一次),在线服务时ItemCF算法会将之前计算好的物品相关度矩阵放在内存中。因此,当新物品加入时,内存中的物品相关表中不会存在这个物品,从而ItemCF算法无法推荐新的物品。解决这一问题的办法是频繁更新物品相似度表,但基于用户行为计算物品相似度是非常耗时的事情,主要原因是用户行为日志非常庞大。而且,新物品如果不展示给用户,用户就无法对它产生行为,通过行为日志计算是计算不出包含新物品的相关矩阵的。为此,我们只能利用物品的内容信息计算物品相关表,并且频繁地更新相关表(比如半小时计算一次)。
物品的内容信息多种多样,不同类型的物品有不同的内容信息。如果是电影,那么内容信息一般包括标题、导演、演员、编剧、剧情、风格、国家、年代等。如果是图书,内容信息一般包含标题、作者、出版社、正文、分类等。表3-4展示了常见物品的常用内容信息。

一般来说,物品的内容可以通过向量空间模型①表示,该模型会将物品表示成一个关键词向量。如果物品的内容是一些诸如导演、演员等实体的话,可以直接将这些实体作为关键词。但如果内容是文本的形式,则需要引入一些理解自然语言的技术抽取关键词。图3-11展示了从文本生成关键词向量的主要步骤。对于中文,首先要对文本进行分词,将字流变成词流,然后从词流中检测出命名实体(如人名、地名、组织名等),这些实体和一些其他重要的词将组成关键词集合,最后对关键词进行排名,计算每个关键词的权重,从而生成关键词向量。

对物品d,它的内容表示成一个关键词向量如下:
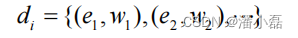
其中, ei 就是关键词, wi 是关键词对应的权重。如果物品是文本,我们可以用信息检索领域著名的TF-IDF公式计算词的权重:
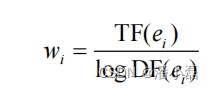
如果物品是电影,可以根据演员在剧中的重要程度赋予他们权重。向量空间模型的优点是简单,缺点是丢失了一些信息,比如关键词之间的关系信息。不过在绝大多数应用中,向量空间模型对于文本的分类、聚类、相似度计算已经可以给出令人满意的结果。
在给定物品内容的关键词向量后,物品的内容相似度可以通过向量之间的余弦相似度计算:
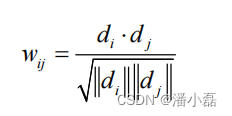
在具体计算物品之间的内容相似度时,最简单的方法当然是对两两物品都利用上面的余弦相似度公式计算相似度,如下代码简单实现了这种方法:
function CalculateSimilarity(D)
for di in D:
for dj in D:
w[i][j] = CosineSimilarity(di, dj)
return w
这里,D是文档集合。
但这种算法的时间复杂度很高。假设有N个物品,每个物品平均由m个实体表示,那么这个算法的复杂度是O(N²m) 。
在实际应用中,可以首先通过建立关键词—物品的倒排表加速这一计算过程,关于这一方法
已经在前面介绍UserCF和ItemCF算法时详细介绍过了,所以这里直接给出计算的代码:
function CalculateSimilarity(entity-items)
w = dict()
ni = dict()
for e,items in entity_items.items():
for i,wie in items.items():
addToVec(ni, i, wie * wie)
for j,wje in items.items():
addToMat(w, i, j, wie, wje)
for i, relate_items in w.items():
relate_items = {x:y/math.sqrt(ni[i] * ni[x]) for x,y in relate_items.items()}
得到物品的相似度之后,可以利用上一章提到的ItemCF算法的思想,给用户推荐和他历史上喜欢的物品内容相似的物品。
也许有读者认为,既然内容相似度计算简单,能频繁更新,而且能够解决物品冷启动问题,那么为什么还需要协同过滤的算法。为了说明内容过滤算法和协同过滤算法的优劣,本节在MovieLens和GitHub两个数据集上进行了实验。MovieLens数据集上一章已经详细介绍了,它也提供了有限的内容信息,主要包括电影的类别信息(动作片、爱情片等类别),GitHub数据集包含代码开发者对开源项目的兴趣数据,它的用户是程序员,物品是开源工程,如果一名程序员关注某个开源工程,就会有一条行为记录。该数据集中主要的内容数据是开源项目的所有者名。
表3-5比较了内容过滤算法ContentItemKNN和协调过滤算法ItemCF在MovieLens和GitHub数据集上的离线实验性能。为了对比,我们同时加入了Random和MostPopular两个非个性化的推荐算法作为基准。
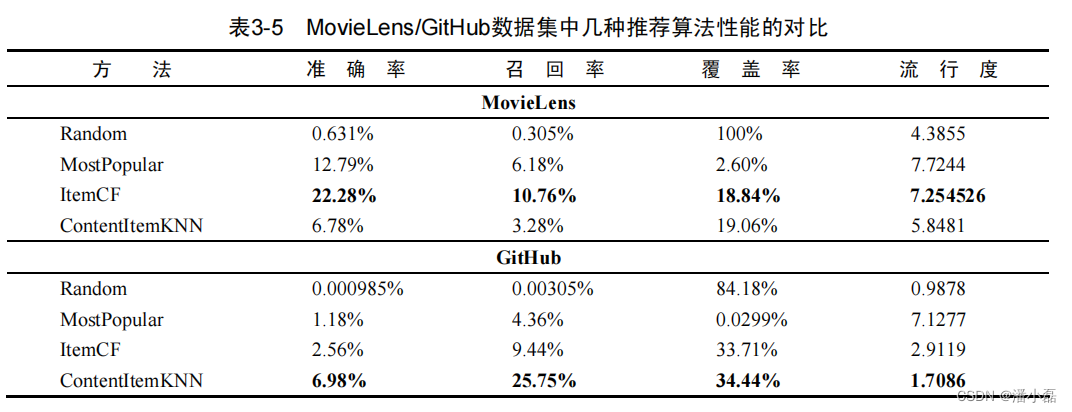
从MovieLens数据集上的结果可以发现,ContentItemKNN的准确率和召回率仅仅优于Random算法,明显差于ItemCF算法,甚至比MostPopular算法还要差。不过在覆盖率和流行度指标上ContentItemKNN却优于ItemCF。这主要是因为内容过滤算法忽视了用户行为,从而也忽视了物品的流行度以及用户行为中所包含的规律,所以它的精度比较低,但结果的新颖度却比较高。
不过,事情不是绝对的。如果看GitHub数据集的结果,我们会发现完全相反的现象——Content-ItemKNN在所有指标上都优于ItemCF。这主要是因为GitHub提供了一个非常强的内容特征,就是开源项目的作者。在GitHub中,程序员会经常会关注同一个作者的不同项目,这一点是GitHub数据集最重要的特征。而协同过滤算法由于数据稀疏的影响,不能从用户行为中完全统计出这一特征,所以协同过滤算法反而不如利用了先验信息的内容过滤算法。这一点也说明,如果用户的行为强烈受某一内容属性的影响,那么内容过滤的算法还是可以在精度上超过协同过滤算法的。不过这种强的内容特征不是所有物品都具有的,而且需要丰富的领域知识才能获得,所以很多时候内容过滤算法的精度比协同过滤算法差。不过,这也提醒我们,如果能够将这两种算法融合,一定能够获得比单独使用这两种算法更好的效果。
ECML/PKDD在2011年举办过一次利用物品内容信息解决冷启动问题的比赛。该比赛提供了物品的内容信息,希望参赛者能够利用这些内容信息尽量逼近协同过滤计算出的相似度表。对内容推荐感兴趣的读者可以关注该比赛的相关论文。
向量空间模型在内容数据丰富时可以获得比较好的效果。以文本为例,如果是计算长文本的相似度,用向量空间模型利用关键词计算相似度已经可以获得很高的精确度。但是,如果文本很短,关键词很少,向量空间模型就很难计算出准确的相似度。举个例子,假设有两篇论文,它们的标题分别是“推荐系统的动态特性”和“基于时间的协同过滤算法研究”。如果读者对推荐系统很熟悉,可以知道这两篇文章的研究方向是类似的,但是它们标题中没有一样的关键词。其实,它们的关键词虽然不同,但却是相似的。“动态”和“基于时间”含义相似,“协同过滤”是“推荐系统”的一种算法。换句话说,这两篇文章的关键词虽然不同,但关键词所属的话题是相同的。在这种情况下,首先需要知道文章的话题分布,然后才能准确地计算文章的相似度。如何建立文章、话题和关键词的关系是话题模型(topic model)研究的重点。
代表性的话题模型有LDA。以往关于该模型的理论文章已经很多了,本书不准备讨论太多的数学问题,所以这里准备用形象的语言介绍一下LDA,并用工程师很容易懂的方法介绍这个算法。关于LDA的详细理论介绍可以参考DM Blei的论文“Latent Dirichlet Allocation”②。
任何模型都有一个假设,LDA作为一种生成模型,对一篇文档产生的过程进行了建模。话题模型的基本思想是,一个人在写一篇文档的时候,会首先想这篇文章要讨论哪些话题,然后思考这些话题应该用什么词描述,从而最终用词写成一篇文章。因此,文章和词之间是通过话题联系的。
LDA中有3种元素,即文档、话题和词语。每一篇文档都会表现为词的集合,这称为词袋模型(bag of words)。每个词在一篇文章中属于一个话题。令D为文档集合,D[i]是第i篇文档。w[i][j]是第i篇文档中的第j个词。z[i][j]是第i篇文档中第j个词属于的话题。
LDA的计算过程包括初始化和迭代两部分。首先要对z进行初始化,而初始化的方法很简单,假设一共有K个话题,那么对第i篇文章中的第j个词,可以随机给它赋予一个话题。同时,用NWZ(w,z)记录词w被赋予话题z的次数,NZD(z,d)记录文档d中被赋予话题z的词的个数。
foreach document i in range(0,|D|):
foreach word j in range(0, |D(i)|):
z[i][j] = rand() % K
NZD[z[i][j], D[i]]++
NWZ[w[i][j], z[i][j]]++
NZ[z[i][j]]++
在初始化之后,要通过迭代使话题的分布收敛到一个合理的分布上去。伪代码如下所示:
while not converged:
foreach document i in range(0, |D|):
foreach word j in range(0, |D(i)|):
NWZ[w[i][j], z[i][j]]--
NZ[z[i][j]]--
NZD[z[i][j], D[i]]--
z[i][j] = SampleTopic()
NWZ[w[i][j], z[i][j]]++
NZ[z[i][j]]++
NZD[z[i][j], D[i]]++
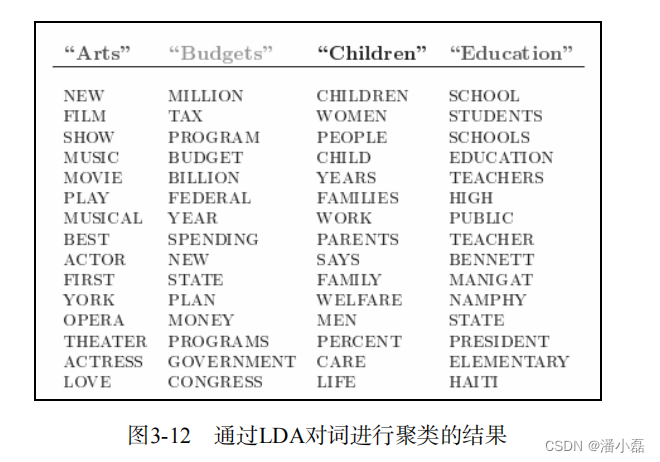
LDA可以很好地将词组合成不同的话题。这里我们引用David M. Blei在论文中给出的一个实验结果。他利用了一个科学论文摘要的数据集,该数据集包含16333篇新闻,共23075个不同的单词。通过LDA,他计算出100个话题并且在论文中给出了其中4个话题排名最高(也就是p(w|z)最大)的15个词。从图3-12所示的聚类结果可以看到,LDA可以较好地对词进行聚类,找到每个词的相关词。
在使用LDA计算物品的内容相似度时,我们可以先计算出物品在话题上的分布,然后利用两个物品的话题分布计算物品的相似度。比如,如果两个物品的话题分布相似,则认为两个物品具有较高的相似度,反之则认为两个物品的相似度较低。计算分布的相似度可以利用KL散度:

其中p和q是两个分布,KL散度越大说明分布的相似度越低。
3.5 发挥专家的作用
很多推荐系统在建立时,既没有用户的行为数据,也没有充足的物品内容信息来计算准确的物品相似度。那么,为了在推荐系统建立时就让用户得到比较好的体验,很多系统都利用专家进行标注。这方面的代表系统是个性化网络电台Pandora和电影推荐网站Jinni。
Pandora是一个给用户播放音乐的个性化电台应用。众所周知,计算音乐之间的相似度是比较困难的。首先,音乐是多媒体,如果从音频分析入手计算歌曲之间的相似度,则技术门槛很高,而且也很难计算得令人满意。其次,仅仅利用歌曲的专辑、歌手等属性信息很难获得令人满意的歌曲相似度表,因为一名歌手、一部专辑往往只有一两首好歌。为了解决这个问题,Pandora雇用了一批懂计算机的音乐人进行了一项称为音乐基因的项目。他们听了几万名歌手的歌,并对这些歌的各个维度进行标注。最终,他们使用了400多个特征(Pandora称这些特征为基因)。标注完所有的歌曲后,每首歌都可以表示为一个400维的向量,然后通过常见的向量相似度算法可以计算出歌曲的相似度。
和Pandora类似,Jinni也利用相似的想法设计了电影基因系统,让专家给电影进行标注。Jinni网站对电影基因项目进行了介绍。图3-13是Jinni中专家给《功夫熊猫》标注的基因。

可以看到,这里的基因包括如下分类。
心情(Mood) 表示用户观看电影的心情,比如对于《功夫熊猫》观众会觉得很幽默,很兴奋。
剧情(Plot) 包括电影剧情的标签。
类别(Genres) 表示电影的类别,主要包括动画片、喜剧片、动作片等分类。
时间(Time/Period) 电影故事发生的时间。
地点(Place) 电影故事发生的地点。
观众(Audience) 电影的主要观众群。
获奖(Praise) 电影的获奖和评价情况。
风格(Style) 功夫片、全明星阵容等。
态度(Attitudes) 电影描述故事的态度。
画面(Look) 电脑拍摄的画面技术,比如《功夫熊猫》是用电脑动画制作的。
标记(Flag) 主要表示电影有没有暴力和色情内容。
Jinni在电影基因工程中采用了半人工、半自动的方式。首先,它让专家对电影进行标记,每个电影都有大约50个基因,这些基因来自大约1000个基因库。然后,在专家标记一定的样本后,Jinni会使用自然语言理解和机器学习技术,通过分析用户对电影的评论和电影的一些内容属性对电影(特别是新电影)进行自己的标记。同时,Jinni也设计了让用户对基因进行反馈的界面,希望通过用户反馈不断改进电影基因系统。
总之,Jinni通过专家和机器学习相结合的方法解决了系统冷启动问题














 307
307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









