







研究背景与意义
研究背景与意义
随着城市化进程的加快,树木作为城市生态系统的重要组成部分,其健康状况和分布情况对城市环境的可持续发展具有重要影响。树木的实例分割技术,尤其是在计算机视觉领域,已成为研究和管理城市绿化的重要工具。传统的树木监测方法往往依赖人工调查,效率低下且容易受到人为因素的影响。因此,基于深度学习的自动化树木实例分割系统的开发显得尤为必要。
本研究旨在基于改进的YOLOv11模型,构建一个高效的树木实例分割系统。该系统将利用一个包含1500张图像的专用数据集,专注于树木这一单一类别的实例分割。通过对数据集的精细标注和模型的优化训练,我们期望能够实现对树木的精准识别与分割。这不仅能够提高树木监测的效率,还能为城市规划、生态评估和环境保护提供科学依据。
此外,树木实例分割技术的应用前景广泛。在城市绿化管理中,能够快速、准确地识别树木位置和健康状况,有助于制定合理的养护方案;在生态研究中,分析树木的分布和生长趋势,有助于理解生态系统的动态变化。因此,开发一个基于YOLOv11的树木实例分割系统,不仅具有重要的学术价值,也为实际应用提供了切实可行的解决方案。
综上所述,本研究的开展将推动树木监测技术的发展,为实现智能化的城市绿化管理提供有力支持,具有重要的理论意义和实际应用价值。通过不断优化模型和算法,我们期望能够为未来的城市生态环境保护贡献一份力量。
图片演示
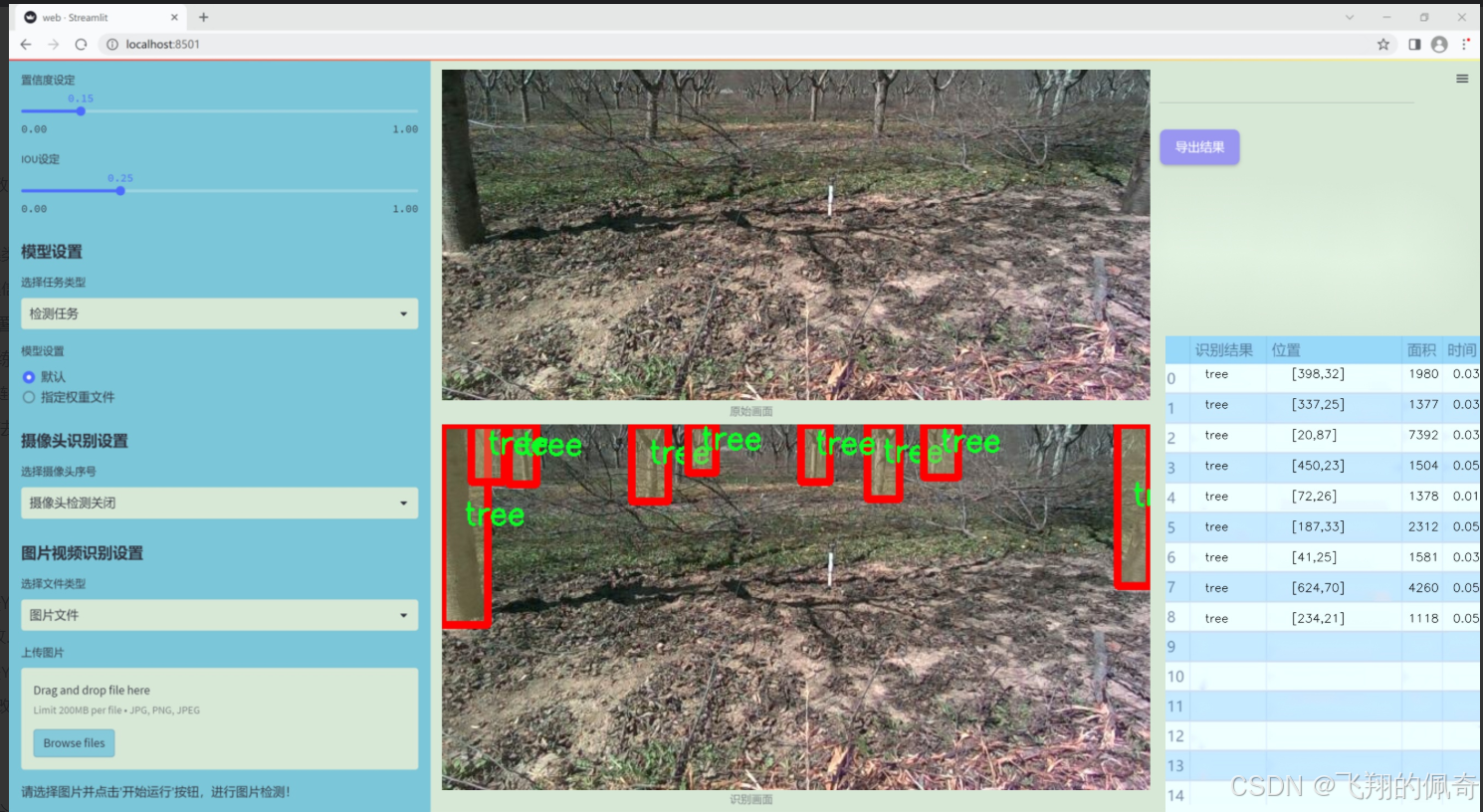
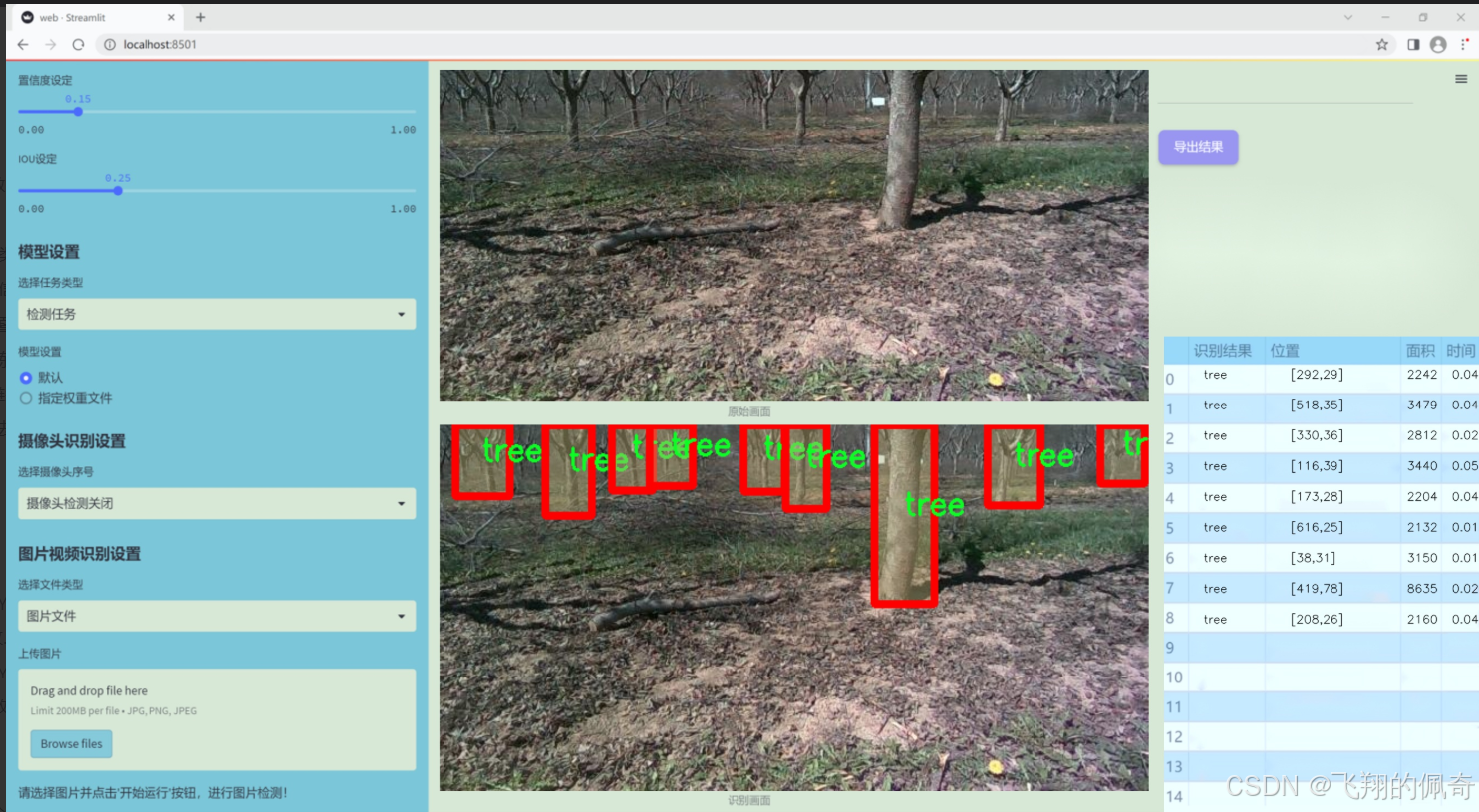
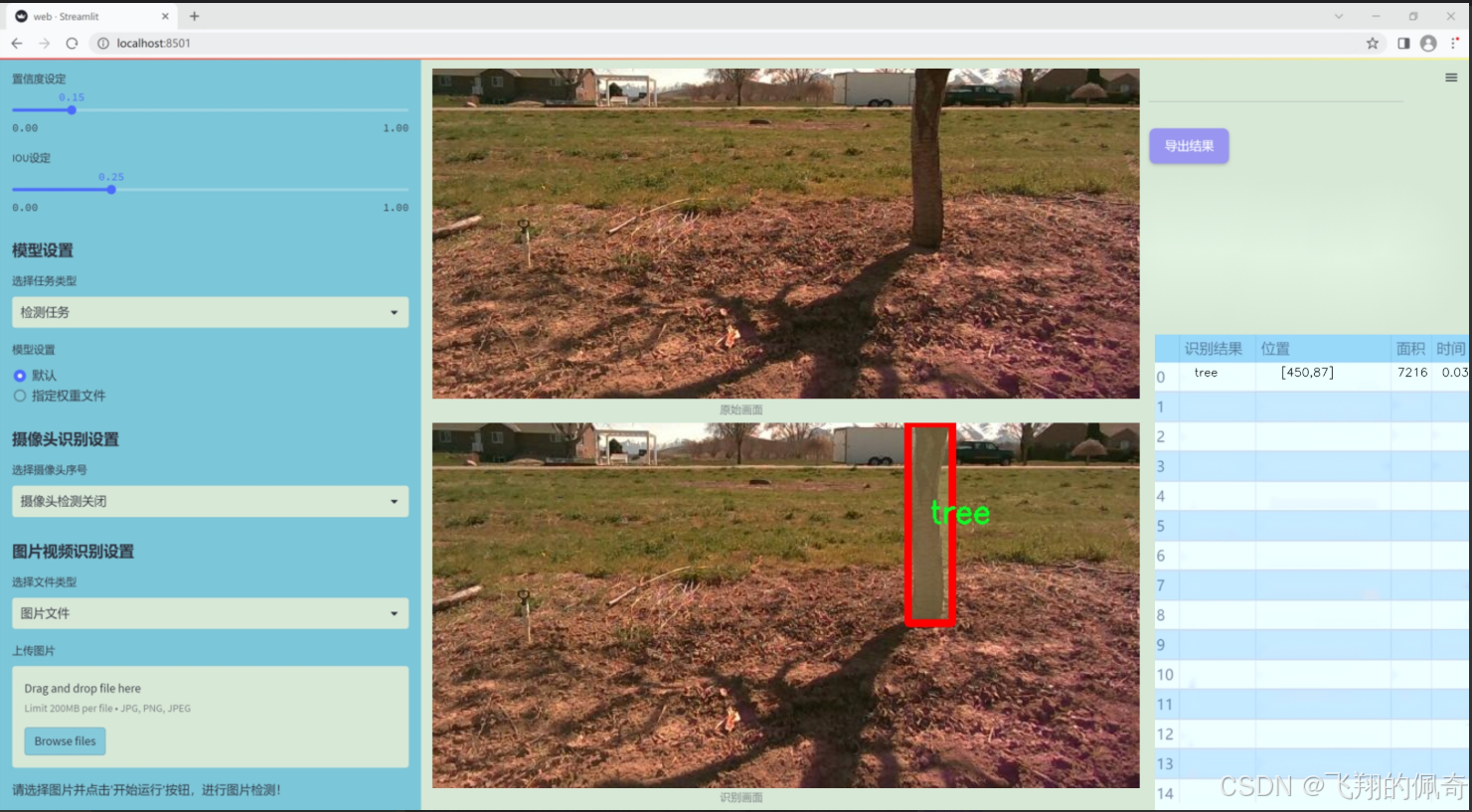
数据集信息展示
本项目数据集信息介绍
本项目旨在改进YOLOv11的树木实例分割系统,所使用的数据集专注于“树干分割”(Trunk segmentation)这一主题。该数据集包含了丰富的树木图像,专门用于训练模型以实现高效、准确的树干识别与分割。数据集中仅包含一个类别,即“树”(tree),这使得模型在训练过程中能够专注于树干的特征提取与学习,避免了多类别间的干扰。
在数据集的构建过程中,选取了多种不同环境下的树木图像,涵盖了城市公园、森林、山地等多样化的自然场景。这些图像不仅包含了不同种类的树木,还考虑了不同的光照条件、天气变化以及树木的生长状态,从而确保数据集的多样性和代表性。此外,数据集中的图像经过精心标注,确保每个树干的轮廓清晰可见,为模型的训练提供了高质量的标注数据。
为了增强模型的泛化能力,数据集还包括了一些经过数据增强处理的图像,例如旋转、缩放、裁剪和颜色调整等。这些处理手段旨在模拟现实世界中可能遇到的各种情况,使得训练出的模型能够在实际应用中表现出色。
总之,本项目的数据集为改进YOLOv11的树木实例分割系统提供了坚实的基础,专注于树干这一单一类别的训练,结合多样化的环境和条件,力求实现高效、准确的树木实例分割,推动相关领域的研究与应用发展。





项目核心源码讲解(再也不用担心看不懂代码逻辑)
VanillaNet.py
以下是经过简化和注释的核心代码部分,保留了模型的主要结构和功能:
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.layers import weight_init
定义激活函数类,继承自ReLU
class Activation(nn.ReLU):
def init(self, dim, act_num=3, deploy=False):
super(Activation, self).init()
self.deploy = deploy # 是否处于部署模式
# 权重和偏置初始化
self.weight = torch.nn.Parameter(torch.randn(dim, 1, act_num * 2 + 1, act_num * 2 + 1))
self.bias = None
self.bn = nn.BatchNorm2d(dim, eps=1e-6) # 批归一化
self.dim = dim
self.act_num = act_num
weight_init.trunc_normal_(self.weight, std=.02) # 权重初始化
def forward(self, x):
# 前向传播
if self.deploy:
return F.conv2d(
super(Activation, self).forward(x),
self.weight, self.bias, padding=(self.act_num * 2 + 1) // 2, groups=self.dim)
else:
return self.bn(F.conv2d(
super(Activation, self).forward(x),
self.weight, padding=self.act_num, groups=self.dim))
def switch_to_deploy(self):
# 切换到部署模式,融合批归一化
if not self.deploy:
kernel, bias = self._fuse_bn_tensor(self.weight, self.bn)
self.weight.data = kernel
self.bias = torch.nn.Parameter(torch.zeros(self.dim))
self.bias.data = bias
self.__delattr__('bn') # 删除bn属性
self.deploy = True
def _fuse_bn_tensor(self, weight, bn):
# 融合权重和批归一化
kernel = weight
running_mean = bn.running_mean
running_var = bn.running_var
gamma = bn.weight
beta = bn.bias
eps = bn.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta + (0 - running_mean) * gamma / std
定义基本模块Block
class Block(nn.Module):
def init(self, dim, dim_out, act_num=3, stride=2, deploy=False):
super().init()
self.deploy = deploy
# 根据是否部署选择不同的卷积层
if self.deploy:
self.conv = nn.Conv2d(dim, dim_out, kernel_size=1)
else:
self.conv1 = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=1),
nn.BatchNorm2d(dim, eps=1e-6),
)
self.conv2 = nn.Sequential(
nn.Conv2d(dim, dim_out, kernel_size=1),
nn.BatchNorm2d(dim_out, eps=1e-6)
)
# 池化层
self.pool = nn.MaxPool2d(stride) if stride != 1 else nn.Identity()
self.act = Activation(dim_out, act_num) # 激活函数
def forward(self, x):
# 前向传播
if self.deploy:
x = self.conv(x)
else:
x = self.conv1(x)
x = F.leaky_relu(x, negative_slope=1) # 使用Leaky ReLU
x = self.conv2(x)
x = self.pool(x) # 池化
x = self.act(x) # 激活
return x
def switch_to_deploy(self):
# 切换到部署模式
if not self.deploy:
kernel, bias = self._fuse_bn_tensor(self.conv1[0], self.conv1[1])
self.conv1[0].weight.data = kernel
self.conv1[0].bias.data = bias
kernel, bias = self._fuse_bn_tensor(self.conv2[0], self.conv2[1])
self.conv = self.conv2[0] # 使用第二个卷积层
self.conv.weight.data = kernel
self.conv.bias.data = bias
self.__delattr__('conv1')
self.__delattr__('conv2')
self.act.switch_to_deploy() # 激活函数切换
self.deploy = True
定义VanillaNet模型
class VanillaNet(nn.Module):
def init(self, in_chans=3, num_classes=1000, dims=[96, 192, 384, 768], strides=[2, 2, 2, 1], deploy=False):
super().init()
self.deploy = deploy
# 定义输入层
if self.deploy:
self.stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
Activation(dims[0])
)
else:
self.stem1 = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
nn.BatchNorm2d(dims[0], eps=1e-6),
)
self.stem2 = nn.Sequential(
nn.Conv2d(dims[0], dims[0], kernel_size=1, stride=1),
nn.BatchNorm2d(dims[0], eps=1e-6),
Activation(dims[0])
)
self.stages = nn.ModuleList()
for i in range(len(strides)):
stage = Block(dim=dims[i], dim_out=dims[i + 1], stride=strides[i], deploy=deploy)
self.stages.append(stage) # 添加每个Block到模型中
def forward(self, x):
# 前向传播
if self.deploy:
x = self.stem(x)
else:
x = self.stem1(x)
x = F.leaky_relu(x, negative_slope=1)
x = self.stem2(x)
for stage in self.stages:
x = stage(x) # 依次通过每个Block
return x
def switch_to_deploy(self):
# 切换到部署模式
if not self.deploy:
self.stem2[2].switch_to_deploy()
kernel, bias = self._fuse_bn_tensor(self.stem1[0], self.stem1[1])
self.stem1[0].weight.data = kernel
self.stem1[0].bias.data = bias
self.stem = nn.Sequential(self.stem1[0], self.stem2[2]) # 合并输入层
self.__delattr__('stem1')
self.__delattr__('stem2')
for stage in self.stages:
stage.switch_to_deploy() # 切换每个Block到部署模式
self.deploy = True
用于创建不同配置的VanillaNet模型
def vanillanet_10(pretrained=‘’, **kwargs):
model = VanillaNet(dims=[128 * 4, 128 * 4, 256 * 4, 512 * 4, 512 * 4, 512 * 4, 512 * 4, 1024 * 4], **kwargs)
if pretrained:
weights = torch.load(pretrained)[‘model_ema’]
model.load_state_dict(weights) # 加载预训练权重
return model
if name == ‘main’:
inputs = torch.randn((1, 3, 640, 640)) # 输入示例
model = vanillanet_10() # 创建模型
pred = model(inputs) # 前向传播
for i in pred:
print(i.size()) # 输出每层的尺寸
代码说明:
Activation类:自定义的激活函数类,使用ReLU激活,并支持批归一化的融合。
Block类:基本模块,包含卷积层、池化层和激活函数,支持部署模式。
VanillaNet类:主模型类,构建网络结构,包含多个Block,支持不同的输入和输出通道配置。
vanillanet_10函数:用于创建特定配置的VanillaNet模型,并可选择加载预训练权重。
主程序:创建模型并进行前向传播,输出每层的尺寸。
这个程序文件名为 VanillaNet.py,它实现了一个名为 VanillaNet 的深度学习模型,主要用于图像处理任务。文件中包含了模型的定义、各个模块的实现以及一些辅助函数。
首先,文件引入了必要的库,包括 PyTorch 及其相关模块,主要用于构建神经网络和处理张量。接着,定义了一个 activation 类,继承自 nn.ReLU,用于实现带有可学习参数的激活函数。这个类在初始化时会创建一个权重参数,并通过卷积操作对输入进行处理,支持在部署模式下的优化。
接下来,定义了一个 Block 类,它是 VanillaNet 的基本构建块。每个 Block 包含了卷积层、批归一化层和激活函数。在初始化时,根据是否处于部署模式选择不同的卷积结构。Block 还实现了前向传播方法,并在需要时进行池化操作。
VanillaNet 类是整个模型的核心,包含多个 Block 组成的网络结构。它在初始化时定义了输入通道、输出类别、各层的维度和步幅等参数。模型的前向传播方法会依次通过各个 Block 进行特征提取,并在特定的尺度下保存特征图。
文件中还包含了一些辅助函数,例如 update_weight 用于更新模型的权重,vanillanet_x 系列函数用于创建不同配置的 VanillaNet 模型,并支持加载预训练权重。
最后,在 main 部分,代码创建了一个随机输入,并实例化了一个 VanillaNet 模型进行前向推理,输出每一层的特征图尺寸。
整体来看,这个文件实现了一个灵活且可扩展的卷积神经网络结构,适用于多种图像处理任务,并提供了便捷的预训练模型加载功能。
源码文件

源码获取
可以直接加我下方的微信哦!


















 1078
1078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











