




背景意义
随着全球农业现代化进程的加快,农作物病害的监测与管理已成为确保农业生产安全和提高农产品质量的重要环节。石榴作为一种经济价值较高的水果,其种植面积逐年扩大,但与此同时,石榴病害的发生也对其产量和品质造成了严重威胁。传统的病害识别方法多依赖于人工观察和经验判断,效率低下且容易出现误判,难以满足现代农业生产对精准管理的需求。因此,开发一种高效、准确的石榴病害识别系统显得尤为重要。
近年来,深度学习技术的迅猛发展为图像处理领域带来了新的机遇,尤其是在目标检测和图像分割方面。YOLO(You Only Look Once)系列模型因其高效的实时检测能力和良好的准确性,已广泛应用于各种视觉识别任务中。YOLOv8作为该系列的最新版本,进一步提升了模型的性能和适用性,成为研究者们关注的焦点。然而,针对特定作物病害的图像分割任务,现有的YOLOv8模型仍存在一定的局限性,尤其是在处理复杂背景和细微特征方面。因此,基于改进YOLOv8的石榴病害品质识别图像分割系统的研究具有重要的理论价值和实际意义。
本研究将基于一个包含4500张图像的数据集进行深入探讨,该数据集涵盖了四个主要类别:坏果、鲜果、裂果和霉变果。这些类别不仅反映了石榴在生长过程中可能遭遇的多种病害和品质问题,也为模型的训练和测试提供了丰富的样本支持。通过对这些图像进行标注和分析,我们能够深入理解不同病害对石榴品质的影响,从而为后续的病害管理提供科学依据。
改进YOLOv8模型的核心在于提升其在石榴病害识别中的分割精度和鲁棒性。通过引入先进的图像增强技术、特征提取方法以及多尺度检测策略,期望能够有效提高模型对不同病害特征的敏感性和适应性。此外,结合迁移学习和自监督学习等技术,能够进一步提升模型在小样本情况下的表现,解决数据集标注不足的问题。这些技术的应用不仅有助于提高石榴病害识别的准确性,还能为其他农作物的病害监测提供借鉴。
综上所述,基于改进YOLOv8的石榴病害品质识别图像分割系统的研究,不仅能够推动农业智能化发展,还能为农民提供有效的病害管理工具,最终实现提高石榴产量和品质的目标。通过本研究的深入,期望能够为农业生产的可持续发展贡献一份力量,同时为相关领域的研究提供新的思路和方法。
图片效果
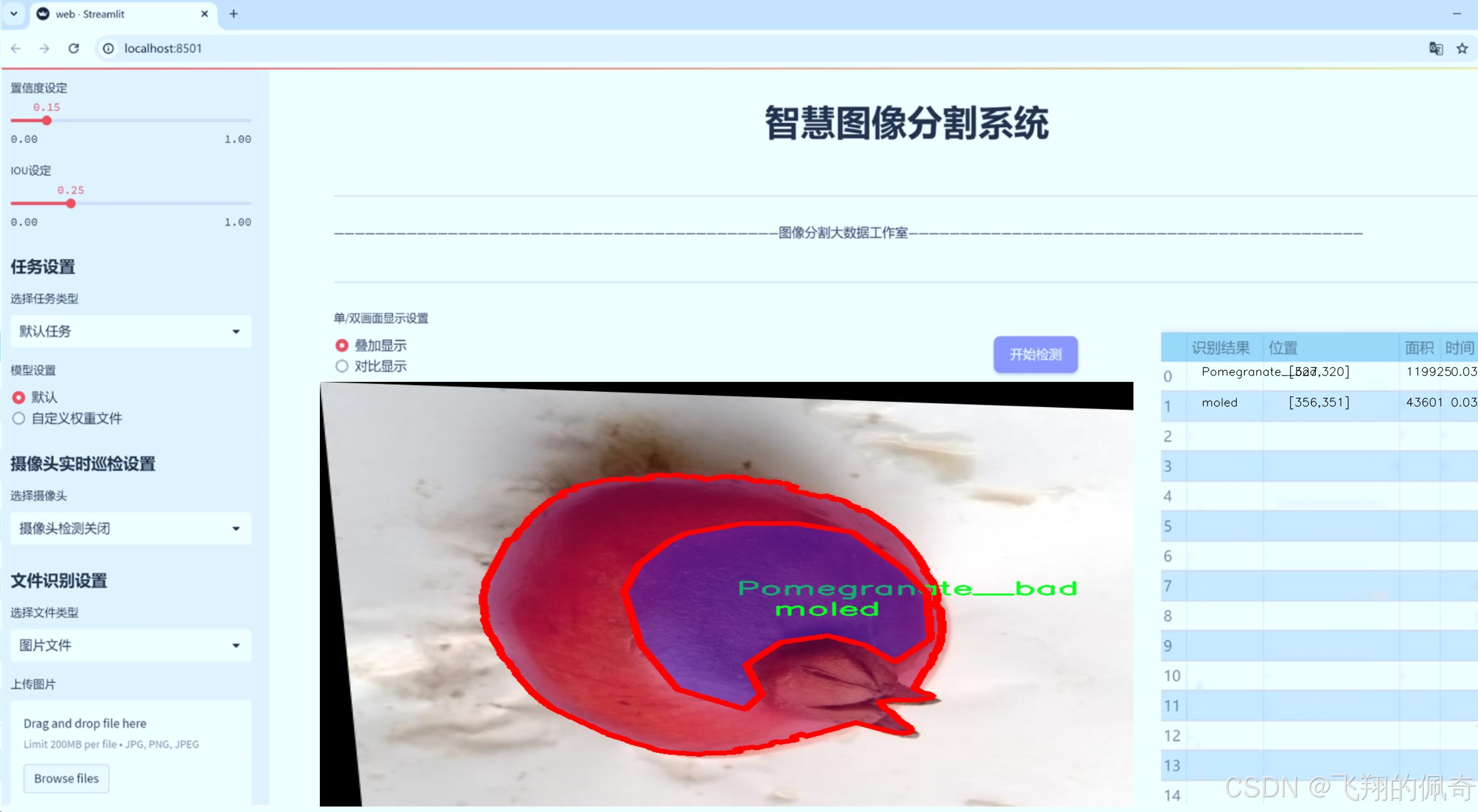
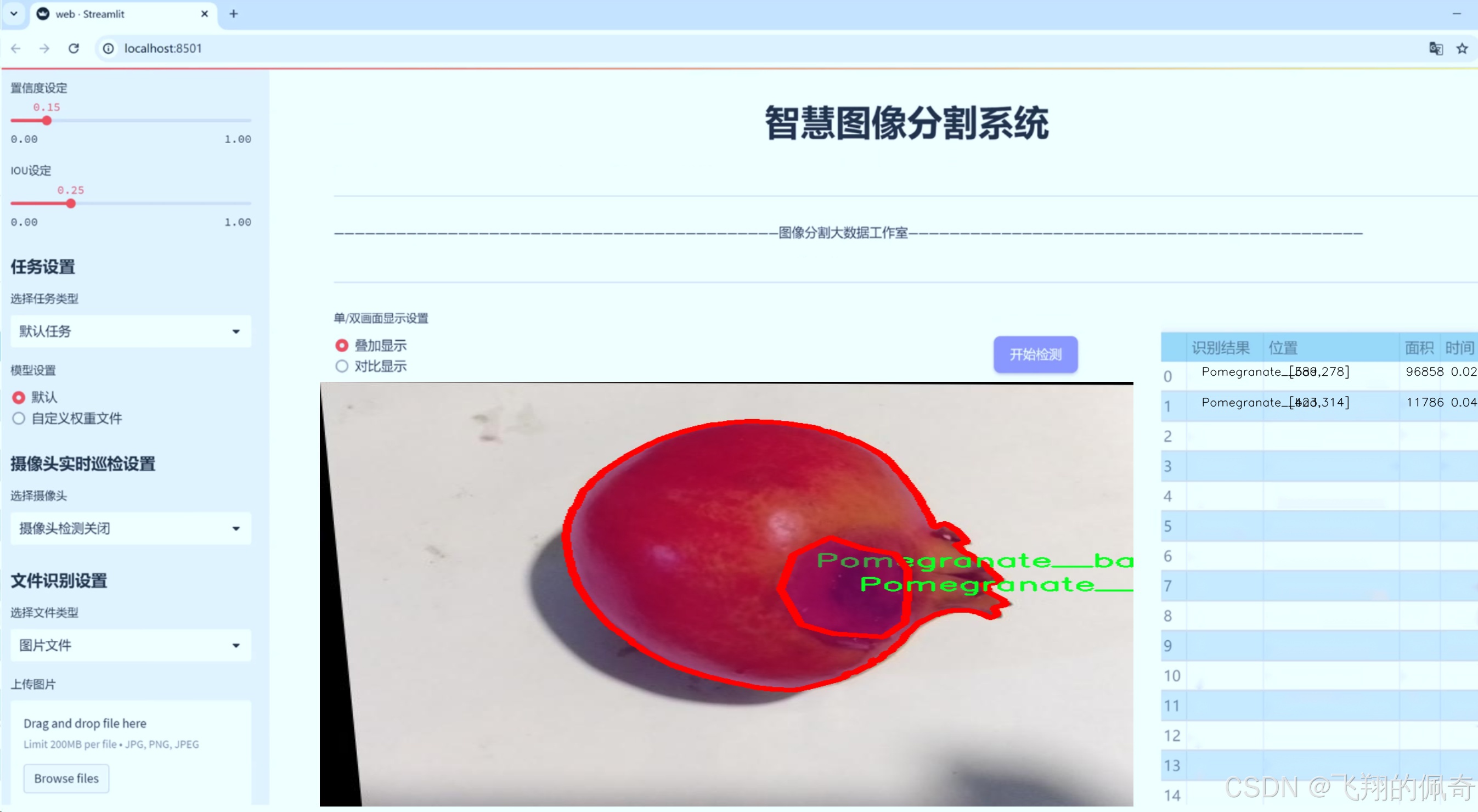
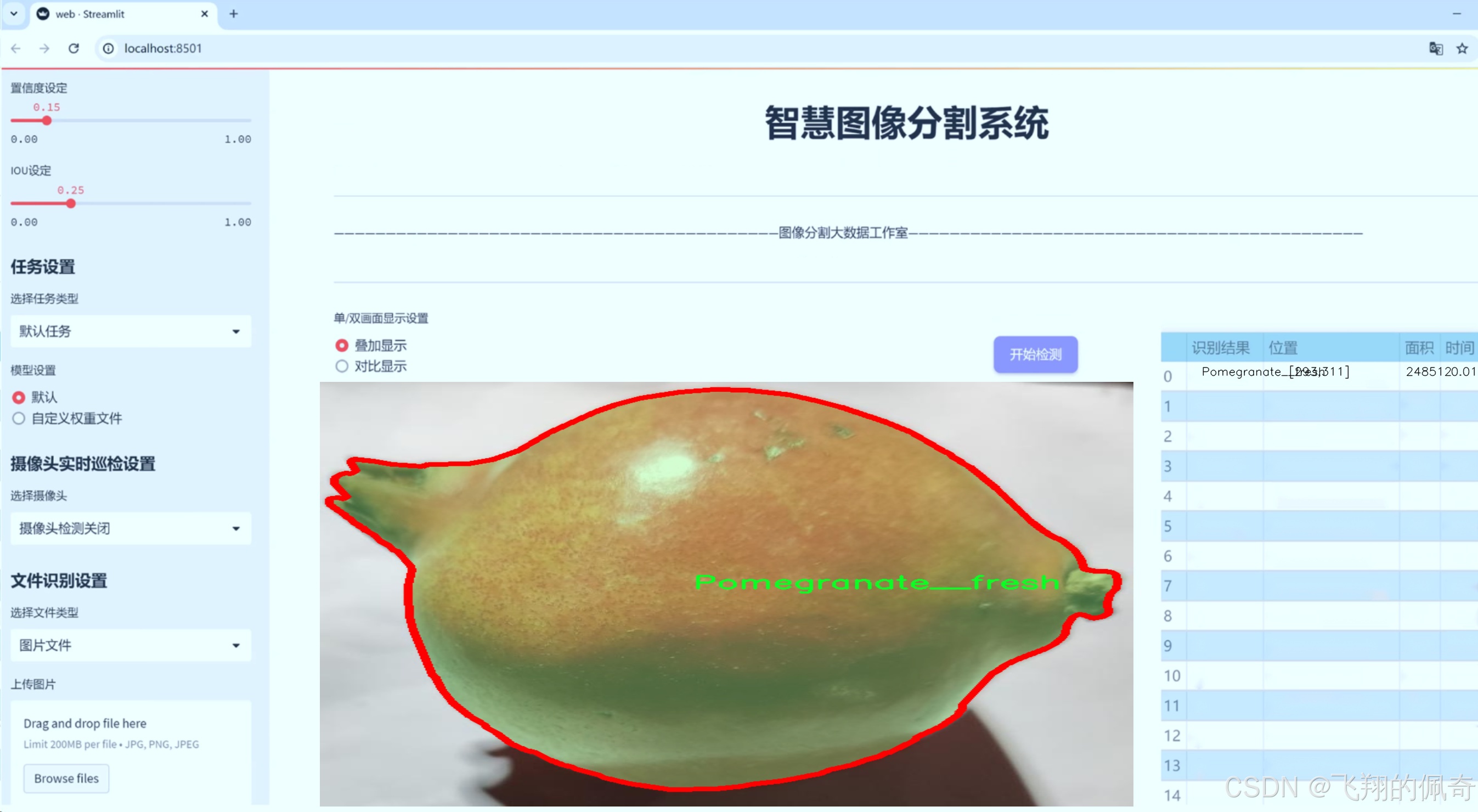
数据集信息
在本研究中,我们采用了名为“metal_segmentation”的数据集,以支持改进YOLOv8-seg的石榴病害品质识别图像分割系统的训练和评估。该数据集专注于石榴的不同品质状态,特别是针对病害和缺陷的分类,为模型提供了丰富的视觉信息,以提高其在实际应用中的准确性和鲁棒性。
“metal_segmentation”数据集包含四个主要类别,分别是“Pomegranate__bad”、“Pomegranate__fresh”、“crack”和“moled”。每个类别代表了石榴在不同生长阶段或受到不同病害影响时的特征表现。具体而言,“Pomegranate__bad”类别涵盖了那些因病害或环境因素而表现出明显劣质特征的石榴,这些特征可能包括变色、腐烂或其他病害迹象。该类别的图像将为模型提供关于病害特征的直观样本,使其能够有效识别并分类出受损的石榴。
相对而言,“Pomegranate__fresh”类别则代表了健康、成熟的石榴,其外观鲜艳、表面光滑,几乎没有任何缺陷。这一类别的图像将帮助模型学习到理想的石榴品质特征,从而在分类时能够准确区分健康与病害石榴。通过将新鲜石榴的特征与受损石榴的特征进行对比,模型将能够更好地理解何为“正常”状态,并在实际应用中作出更为精准的判断。
此外,“crack”类别专注于那些表面出现裂纹的石榴,这种情况可能是由于生长过程中的水分波动或环境压力引起的。裂纹不仅影响石榴的外观,还可能导致进一步的腐烂和病害,因此,准确识别这一类别对于果农和供应链管理者来说至关重要。最后,“moled”类别则包括那些表面有霉斑的石榴,这通常是由于储存条件不当或过度潮湿引起的。霉变不仅影响石榴的市场价值,也可能对消费者的健康构成威胁,因此及时识别这一类别的石榴对于保障食品安全具有重要意义。
整个数据集的构建旨在为改进YOLOv8-seg模型提供全面的训练样本,确保模型能够在多种环境和条件下进行有效的图像分割和分类。通过对这四个类别的深度学习,模型将能够更好地适应不同的石榴品质特征,进而提升其在实际应用中的表现。数据集中的图像经过精心标注,确保每个类别的样本都具有代表性,能够真实反映石榴在生长和储存过程中可能出现的各种情况。
综上所述,“metal_segmentation”数据集为本研究提供了丰富的图像数据,涵盖了石榴品质识别所需的关键特征。通过利用这一数据集,我们期望能够显著提升YOLOv8-seg模型在石榴病害品质识别中的准确性和效率,为果农和相关行业提供更为可靠的技术支持。
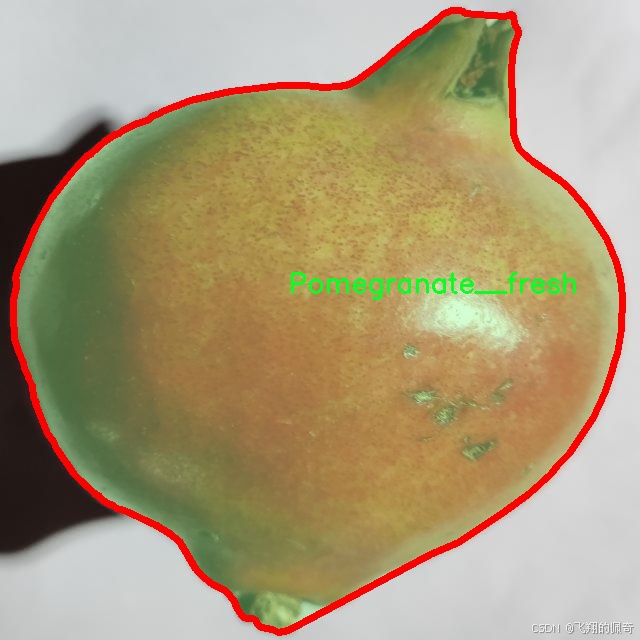
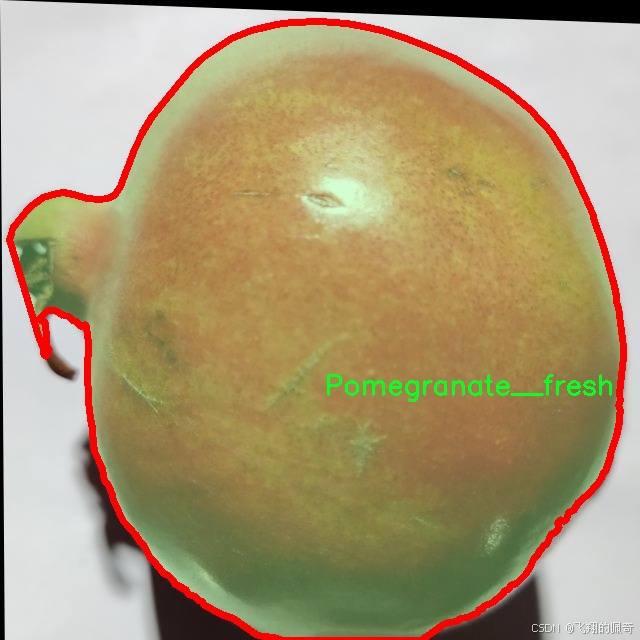
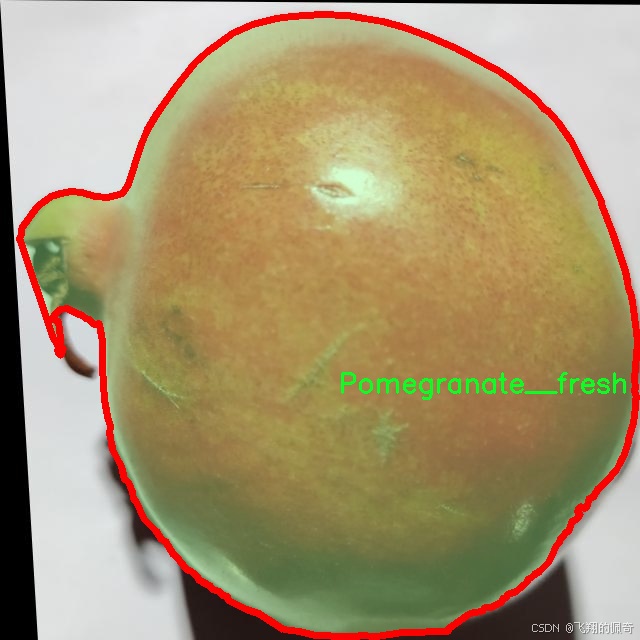
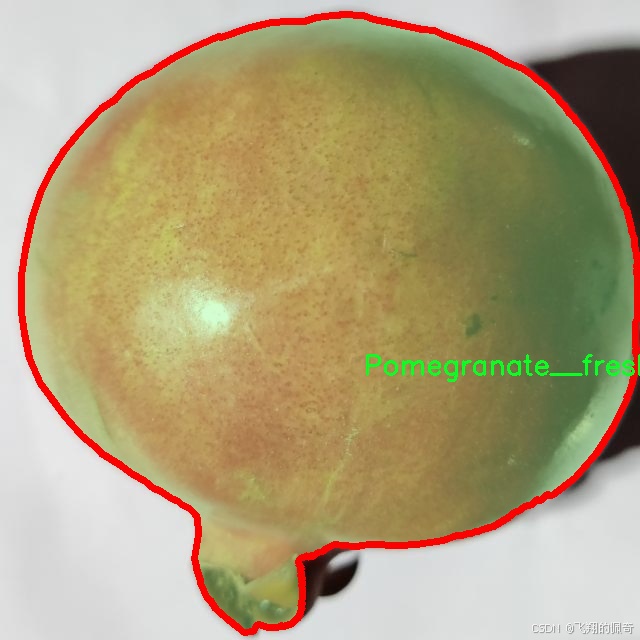
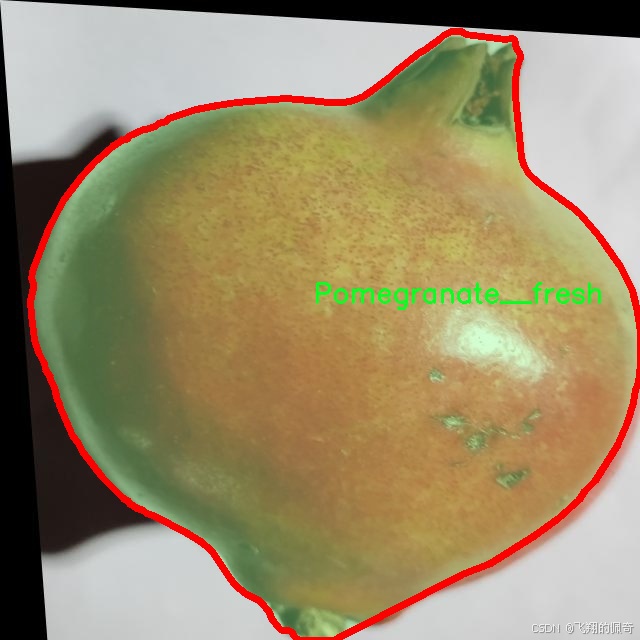
核心代码
以下是对给定代码的核心部分进行提炼和详细注释的结果:
# 导入必要的模块和类
from .predict import SegmentationPredictor # 导入用于图像分割预测的类
from .train import SegmentationTrainer # 导入用于训练图像分割模型的类
from .val import SegmentationValidator # 导入用于验证图像分割模型的类
# 定义模块的公开接口,指定可以被外部访问的类
__all__ = 'SegmentationPredictor', 'SegmentationTrainer', 'SegmentationValidator'
代码解析:
-
模块导入:
from .predict import SegmentationPredictor:从当前包的predict模块中导入SegmentationPredictor类,该类负责处理图像分割的预测任务。from .train import SegmentationTrainer:从当前包的train模块中导入SegmentationTrainer类,该类用于训练图像分割模型。from .val import SegmentationValidator:从当前包的val模块中导入SegmentationValidator类,该类用于验证训练好的图像分割模型的性能。
-
公开接口定义:
__all__是一个特殊的变量,用于定义模块的公共接口。当使用from module import *语句时,只有在__all__中列出的名称会被导入。这里列出了三个类,表明它们是该模块的核心功能部分。
通过以上分析,可以看出这段代码的主要目的是组织和导出与图像分割相关的功能类,以便于其他模块或用户进行调用和使用。```
这个文件是Ultralytics YOLO项目中的一个模块初始化文件,主要用于导入和管理与图像分割相关的类和功能。文件开头的注释表明该项目使用的是AGPL-3.0许可证,说明其开源性质和使用条款。
在文件中,首先从同一目录下导入了三个重要的类:SegmentationPredictor、SegmentationTrainer和SegmentationValidator。这些类分别负责图像分割任务中的预测、训练和验证功能。具体来说,SegmentationPredictor用于执行图像分割的预测操作,SegmentationTrainer用于训练模型以进行图像分割,而SegmentationValidator则用于验证训练后的模型性能。
最后,__all__变量定义了该模块的公共接口,指定了当使用from module import *语句时,哪些名称会被导入。在这里,它包含了之前导入的三个类。这种做法有助于清晰地管理模块的公共API,确保用户只访问到模块中希望公开的部分。
总的来说,这个文件在整个YOLO图像分割模块中起到了组织和导入的作用,使得其他模块或文件能够方便地使用这些核心功能。
```python
import math
import torch
from torch import Tensor, nn
class Attention(nn.Module):
"""注意力层,允许在投影到查询、键和值后对嵌入的大小进行下采样。"""
def __init__(self, embedding_dim: int, num_heads: int, downsample_rate: int = 1) -> None:
"""
初始化注意力模型,设置维度和参数。
Args:
embedding_dim (int): 输入嵌入的维度。
num_heads (int): 注意力头的数量。
downsample_rate (int, optional): 内部维度下采样的因子,默认为1。
"""
super().__init__()
self.embedding_dim = embedding_dim
self.internal_dim = embedding_dim // downsample_rate # 计算内部维度
self.num_heads = num_heads
assert self.internal_dim % num_heads == 0, 'num_heads必须能整除embedding_dim。'
# 定义线性投影层
self.q_proj = nn.Linear(embedding_dim, self.internal_dim) # 查询的线性投影
self.k_proj = nn.Linear(embedding_dim, self.internal_dim) # 键的线性投影
self.v_proj = nn.Linear(embedding_dim, self.internal_dim) # 值的线性投影
self.out_proj = nn.Linear(self.internal_dim, embedding_dim) # 输出的线性投影
@staticmethod
def _separate_heads(x: Tensor, num_heads: int) -> Tensor:
"""将输入张量分离为指定数量的注意力头。"""
b, n, c = x.shape # b: 批量大小, n: 序列长度, c: 特征维度
x = x.reshape(b, n, num_heads, c // num_heads) # 重塑为 B x N x N_heads x C_per_head
return x.transpose(1, 2) # 转置为 B x N_heads x N_tokens x C_per_head
@staticmethod
def _recombine_heads(x: Tensor) -> Tensor:
"""将分离的注意力头重新组合为单个张量。"""
b, n_heads, n_tokens, c_per_head = x.shape
x = x.transpose(1, 2) # 转置为 B x N_tokens x N_heads x C_per_head
return x.reshape(b, n_tokens, n_heads * c_per_head) # 重塑为 B x N_tokens x C
def forward(self, q: Tensor, k: Tensor, v: Tensor) -> Tensor:
"""根据输入的查询、键和值张量计算注意力输出。"""
# 输入投影
q = self.q_proj(q) # 查询投影
k = self.k_proj(k) # 键投影
v = self.v_proj(v) # 值投影
# 分离为多个头
q = self._separate_heads(q, self.num_heads)
k = self._separate_heads(k, self.num_heads)
v = self._separate_heads(v, self.num_heads)
# 计算注意力
_, _, _, c_per_head = q.shape
attn = q @ k.permute(0, 1, 3, 2) # 计算注意力分数
attn = attn / math.sqrt(c_per_head) # 缩放
attn = torch.softmax(attn, dim=-1) # 应用softmax以获得注意力权重
# 获取输出
out = attn @ v # 计算加权值
out = self._recombine_heads(out) # 重新组合头
return self.out_proj(out) # 输出投影
代码核心部分说明:
- Attention类:实现了基本的注意力机制,包含了查询、键和值的线性投影,并通过多头注意力的方式处理输入。
- _separate_heads和_recombine_heads方法:用于将输入张量分离成多个注意力头以及将它们重新组合,方便在多头注意力中进行计算。
- forward方法:实现了注意力的计算流程,包括输入的投影、注意力分数的计算、应用softmax和最终的输出。
以上代码片段展示了注意力机制的基本实现,适用于各种深度学习任务,如图像处理和自然语言处理等。```
这个程序文件定义了一个名为 TwoWayTransformer 的类,主要用于实现一种双向变换器模块,能够同时关注图像和查询点。该类作为一个专门的变换器解码器,利用提供的查询位置嵌入来关注输入图像。这种结构特别适用于目标检测、图像分割和点云处理等任务。
在 TwoWayTransformer 类的构造函数中,定义了一些重要的属性,包括变换器的层数(depth)、输入嵌入的通道维度(embedding_dim)、多头注意力的头数(num_heads)、MLP块的内部通道维度(mlp_dim)等。类中还包含一个 layers 属性,它是一个 nn.ModuleList,用于存储多个 TwoWayAttentionBlock 层。
在 forward 方法中,输入的图像嵌入、图像位置编码和查询点嵌入被处理。首先,图像嵌入被展平并重新排列,以便与查询点嵌入进行匹配。接着,依次通过每个 TwoWayAttentionBlock 层进行处理。最后,应用一个最终的注意力层,将查询点的输出与图像嵌入结合,并进行层归一化处理。
TwoWayAttentionBlock 类实现了一个注意力块,能够执行自注意力和交叉注意力,支持查询到键和键到查询的双向操作。该块包含四个主要层:稀疏输入的自注意力、稀疏输入到密集输入的交叉注意力、稀疏输入的MLP块,以及密集输入到稀疏输入的交叉注意力。在 forward 方法中,首先进行自注意力处理,然后进行交叉注意力处理,接着通过MLP块进行变换,最后再次进行交叉注意力处理。
Attention 类实现了一个注意力层,允许在投影到查询、键和值之后对嵌入的大小进行下采样。构造函数中初始化了输入嵌入的维度、注意力头的数量和下采样率。该类还定义了 _separate_heads 和 _recombine_heads 两个静态方法,用于将输入张量分离成多个注意力头和重新组合。
总体而言,这个程序文件实现了一个复杂的双向变换器结构,能够有效地处理图像和查询点之间的关系,适用于多种计算机视觉任务。
```python
# 导入必要的库
from ultralytics.utils import SETTINGS, TESTS_RUNNING
from ultralytics.utils.torch_utils import model_info_for_loggers
# 尝试导入wandb库并进行基本的设置检查
try:
assert not TESTS_RUNNING # 确保当前不是测试状态
assert SETTINGS['wandb'] is True # 确保wandb集成已启用
import wandb as wb # 导入wandb库
assert hasattr(wb, '__version__') # 确保wandb库不是目录
import numpy as np # 导入numpy库
import pandas as pd # 导入pandas库
_processed_plots = {} # 用于存储已处理的图表
except (ImportError, AssertionError):
wb = None # 如果导入失败,设置wb为None
def _custom_table(x, y, classes, title='Precision Recall Curve', x_title='Recall', y_title='Precision'):
"""
创建并记录自定义的精确度-召回率曲线可视化。
参数:
x (List): x轴的值,长度为N。
y (List): y轴的值,长度为N。
classes (List): 每个点的类别标签,长度为N。
title (str, optional): 图表标题,默认为'Precision Recall Curve'。
x_title (str, optional): x轴标签,默认为'Recall'。
y_title (str, optional): y轴标签,默认为'Precision'。
返回:
(wandb.Object): 适合记录的wandb对象,展示自定义的可视化指标。
"""
# 创建一个DataFrame用于存储数据
df = pd.DataFrame({'class': classes, 'y': y, 'x': x}).round(3)
fields = {'x': 'x', 'y': 'y', 'class': 'class'}
string_fields = {'title': title, 'x-axis-title': x_title, 'y-axis-title': y_title}
# 返回一个wandb表格对象
return wb.plot_table('wandb/area-under-curve/v0',
wb.Table(dataframe=df),
fields=fields,
string_fields=string_fields)
def _plot_curve(x, y, names=None, id='precision-recall', title='Precision Recall Curve', x_title='Recall', y_title='Precision', num_x=100, only_mean=False):
"""
记录指标曲线可视化。
参数:
x (np.ndarray): x轴的数据点,长度为N。
y (np.ndarray): y轴的数据点,形状为CxN,C为类别数量。
names (list, optional): 类别名称,长度为C。
id (str, optional): 在wandb中记录数据的唯一标识符,默认为'precision-recall'。
title (str, optional): 可视化图表的标题,默认为'Precision Recall Curve'。
x_title (str, optional): x轴标签,默认为'Recall'。
y_title (str, optional): y轴标签,默认为'Precision'。
num_x (int, optional): 可视化的插值数据点数量,默认为100。
only_mean (bool, optional): 是否仅绘制均值曲线,默认为True。
"""
# 创建新的x值
if names is None:
names = []
x_new = np.linspace(x[0], x[-1], num_x).round(5)
# 创建用于记录的数组
x_log = x_new.tolist()
y_log = np.interp(x_new, x, np.mean(y, axis=0)).round(3).tolist()
if only_mean:
# 仅记录均值曲线
table = wb.Table(data=list(zip(x_log, y_log)), columns=[x_title, y_title])
wb.run.log({title: wb.plot.line(table, x_title, y_title, title=title)})
else:
# 记录每个类别的曲线
classes = ['mean'] * len(x_log)
for i, yi in enumerate(y):
x_log.extend(x_new) # 添加新的x值
y_log.extend(np.interp(x_new, x, yi)) # 插值y到新的x
classes.extend([names[i]] * len(x_new)) # 添加类别名称
wb.log({id: _custom_table(x_log, y_log, classes, title, x_title, y_title)}, commit=False)
def on_fit_epoch_end(trainer):
"""在每个训练周期结束时记录训练指标和模型信息。"""
wb.run.log(trainer.metrics, step=trainer.epoch + 1) # 记录训练指标
# 记录图表
_log_plots(trainer.plots, step=trainer.epoch + 1)
_log_plots(trainer.validator.plots, step=trainer.epoch + 1)
if trainer.epoch == 0:
wb.run.log(model_info_for_loggers(trainer), step=trainer.epoch + 1) # 记录模型信息
def on_train_end(trainer):
"""在训练结束时保存最佳模型作为artifact。"""
_log_plots(trainer.validator.plots, step=trainer.epoch + 1) # 记录验证图表
_log_plots(trainer.plots, step=trainer.epoch + 1) # 记录训练图表
art = wb.Artifact(type='model', name=f'run_{wb.run.id}_model') # 创建artifact
if trainer.best.exists():
art.add_file(trainer.best) # 添加最佳模型文件
wb.run.log_artifact(art, aliases=['best']) # 记录artifact
wb.run.finish() # 结束wandb运行
代码说明:
- 导入库:导入了必要的库,包括
wandb用于可视化和记录训练过程,numpy和pandas用于数据处理。 - 异常处理:通过
try-except结构确保在没有安装wandb或其他设置不正确时,程序不会崩溃。 - 自定义表格函数:
_custom_table函数用于创建精确度-召回率曲线的可视化表格。 - 绘制曲线函数:
_plot_curve函数根据输入数据生成并记录曲线图,可以选择只记录均值曲线或所有类别的曲线。 - 训练过程回调:定义了在训练过程中的不同阶段(如每个周期结束时和训练结束时)执行的回调函数,以记录训练指标和保存模型。```
这个程序文件是用于集成WandB(Weights and Biases)库,以便在训练YOLO模型时记录和可视化训练过程中的各种指标和曲线。文件首先导入了一些必要的模块,并检查WandB库是否可用以及是否处于测试状态。若不满足条件,则将WandB设置为None。
文件中定义了几个主要的函数。首先是_custom_table函数,它用于创建和记录一个自定义的精确度-召回曲线的可视化。该函数接收x轴和y轴的数据,以及类标签,并生成一个WandB表格对象,以便在WandB中记录。
接下来是_plot_curve函数,它用于生成和记录一个指标曲线的可视化。该函数可以处理多个类的数据,并根据only_mean参数决定是否只绘制平均曲线。它会插值生成新的x值,并根据输入的y值计算对应的y值,最后调用_custom_table函数进行记录。
_log_plots函数用于记录输入字典中的图表,如果在指定的步骤中尚未记录过这些图表。它通过检查时间戳来避免重复记录。
接下来的几个函数分别在训练的不同阶段被调用。on_pretrain_routine_start函数在预训练例程开始时初始化WandB项目。on_fit_epoch_end函数在每个训练周期结束时记录训练指标和模型信息。on_train_epoch_end函数在每个训练周期结束时记录损失和学习率,并在特定条件下记录图表。on_train_end函数在训练结束时保存最佳模型,并记录验证器的图表和曲线。
最后,文件定义了一个回调字典,包含了上述的回调函数,仅在WandB可用时才会被填充。这个字典可以在训练过程中被调用,以便在适当的时机记录训练过程中的各种信息。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻


















 900
900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











