






基于docker本地部署QWQ-32B-AWQ版
本地部署参考下面这篇文件
https://editor.csdn.net/md/?articleId=146147888
Open WebUI
Open WebUI 是一款功能丰富、用户友好的自托管 AI 平台,设计为完全离线运行。 它支持多种语言模型运行器,如 Ollama 和 兼容 OpenAI 的 API,并配备了 内置推理引擎 用于 RAG。
- 开源网址
https://gitcode.com/gh_mirrors/op/open-webui
- 第一种方法操作流程
1.创建虚拟环境,要求python版本为3.11。安装Open WebUI。
conda create -n qwq python==3.11 #创建虚拟环境
pip install open-webui #安装open-webui
2、启动qwq容器
docker run -dp 8880:11434 --runtime=nvidia --gpus device=0 --name qwq-32b -v /custom/model/path:/root/.ollama/models ollama/ollama:0.5.7
–name qwq-32b:本地部署qwq时的容器名称
–8880:11434:本地端口 :映射端口
–v /custom/model/path:/root/.ollama/models:本地模型路径:容器模型路径
ollama/ollama:0.5.7: 镜像
3、运行 Open WebUI
open-webui serve #如果端口被占用,后面加 --port 1111 自定义端口
正常启动如下,没有error和warning
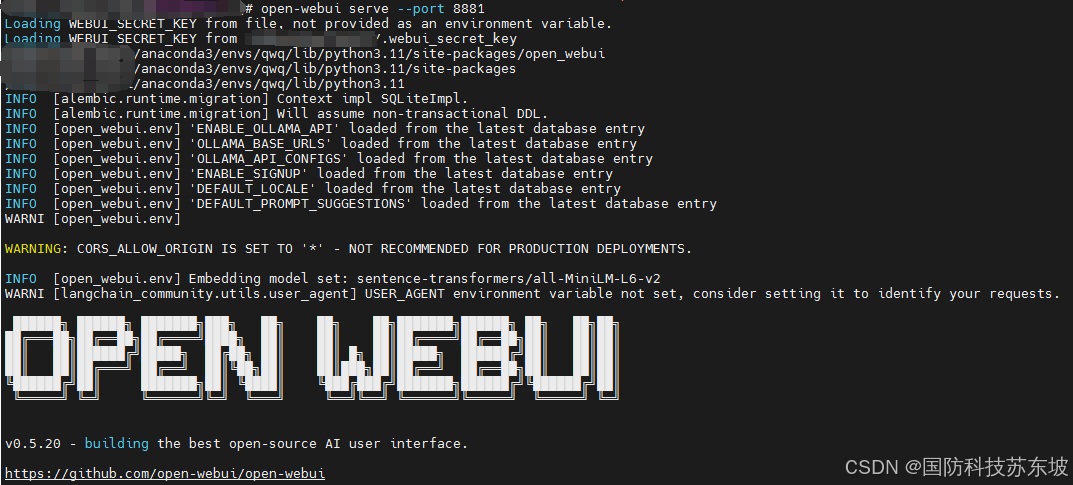
4、浏览器输入网址
进入页面后,注册邮箱帐号。第一次进入可能会比较慢。
http://localhost:8880 # localhost为宿主机地址 8880为容器本地端口(--port 自定义的端口)
5、选择本地模型
选择本地部署的qwq:lastest模型,Arena Model为自带模型。

如果没有搜索模型,说明OpenWebUI 配置未指向模型服务地址。
问题:OpenWebUI 默认连接本地 Ollama(http://localhost:11434),若模型服务部署在其他地址(如容器 IP 或远程服务器),需手动修改配置。
解决:登录 OpenWebUI → 设置 → 管理员设置 → 外部连接,设置 Ollama Base URL 为实际服务地址,例如:http://<宿主机IP>:8880(8880为本地容器暴露出来的端口,第四步的容器端口)。保存,保存!!!
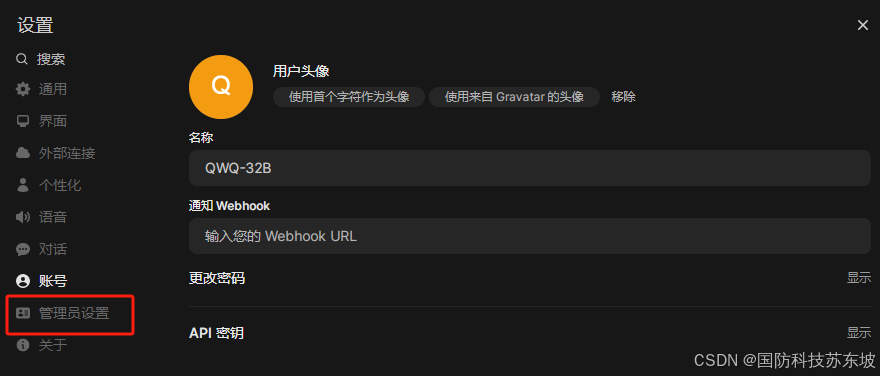

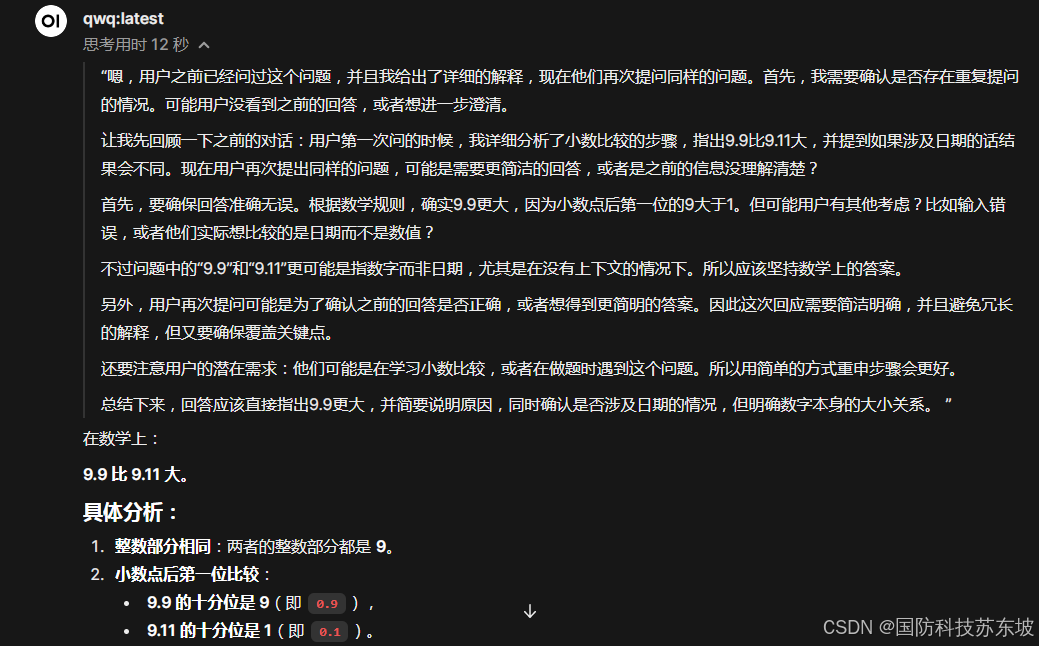
6、问答结果
经典问题:9.9和9.11哪个大?
可以看到有思考过程,用时12秒,结果正确。一张3090显卡足够运行模型,效果还是很不错的。
- 第二种方法操作流程
第一种方法在后台启动,并不稳定。第二种方法在容器中启动,更加稳定,不会因为终端意外关掉而断连。
安装带有 Ollama 支持的 Open WebUI,此安装方法使用单个容器镜像,将 Open WebUI 和 Ollama 打包在一起。
这种方法下载镜像特别慢,先用方法一走通流程。用下面命令启动容器后,相当于完成方法一的第三步,后续流程一样。
docker run -d -p 8880:8080 --gpus=all -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollama

















 1216
1216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









