







 本文详细介绍了Spark推荐系统,包括推荐系统概述、协同过滤算法(基于用户和物品)、Spark中的参数设置与代码实现。通过实例展示了如何在Spark中使用ALS算法进行协同过滤并提供推荐。
本文详细介绍了Spark推荐系统,包括推荐系统概述、协同过滤算法(基于用户和物品)、Spark中的参数设置与代码实现。通过实例展示了如何在Spark中使用ALS算法进行协同过滤并提供推荐。
一、Spark推荐系统介绍
1.1 推荐系统概述
推荐系统是一种信息过滤系统,通过分析用户的行为、偏好和个人信息,将最相关、最有用的信息或商品推荐给用户,以提高用户的满意度和体验。在电商、社交网络、音乐、视频等领域,推荐系统已经成为用户获取信息和产品的重要工具。
1.2 推荐系统算法分类
推荐系统算法可以分为基于内容的推荐算法和协同过滤算法。基于内容的推荐算法是根据物品的属性和用户的偏好进行匹配推荐,它主要关注物品的内容特征;而协同过滤算法则是基于用户的行为数据,通过分析用户与物品的历史关系,找出具有相似行为特征的用户或物品,从而进行推荐。
二、协同过滤算法介绍
2.1 基本原理
协同过滤算法是推荐系统中最常用的算法之一。它基于用户行为数据,通过分析用户的历史行为,找出具有相似行为特征的用户或物品,从而进行推荐。协同过滤算法主要有两种类型:基于用户的协同过滤和基于物品的协同过滤。
2.2 基于用户的协同过滤
基于用户的协同过滤算法是根据用户的历史行为数据,找出具有相似行为特征的用户,将这些用户喜欢的物品推荐给目标用户。算法的基本步骤如下:
(1)计算用户之间的相似度:可以使用余弦相似度或皮尔逊相关系数等方法计算用户之间的相似度。
(2)找出与目标用户最相似的K个用户。
(3)根据这K个用户喜欢的物品,计算推荐物品的得分。
(4)将得分最高的物品推荐给目标用户。
2.3 基于物品的协同过滤
基于物品的协同过滤算法是根据用户的历史行为数据,找出用户之间喜欢的相似物品,将这些相似物品推荐给目标用户。算法的基本步骤如下:
(1)计算物品之间的相似度:可以使用余弦相似度或皮尔逊相关系数等方法计算物品之间的相似度。
(2)找出目标用户喜欢的物品。
(3)根据这些物品的相似物品,计算推荐物品的得分。
(4)将得分最高的物品推荐给目标用户。
三、Spark推荐系统实现
3.1 参数介绍
在Spark中实现推荐系统的过程中,常用的参数有:
(1)numIterations:迭代次数
(2)rank:模型的潜在因子个数
(3)lambda:正则化参数
(4)alpha:评分的信度参数
3.2 完整代码案例
下面是一个使用Spark实现协同过滤推荐算法的完整代码案例:
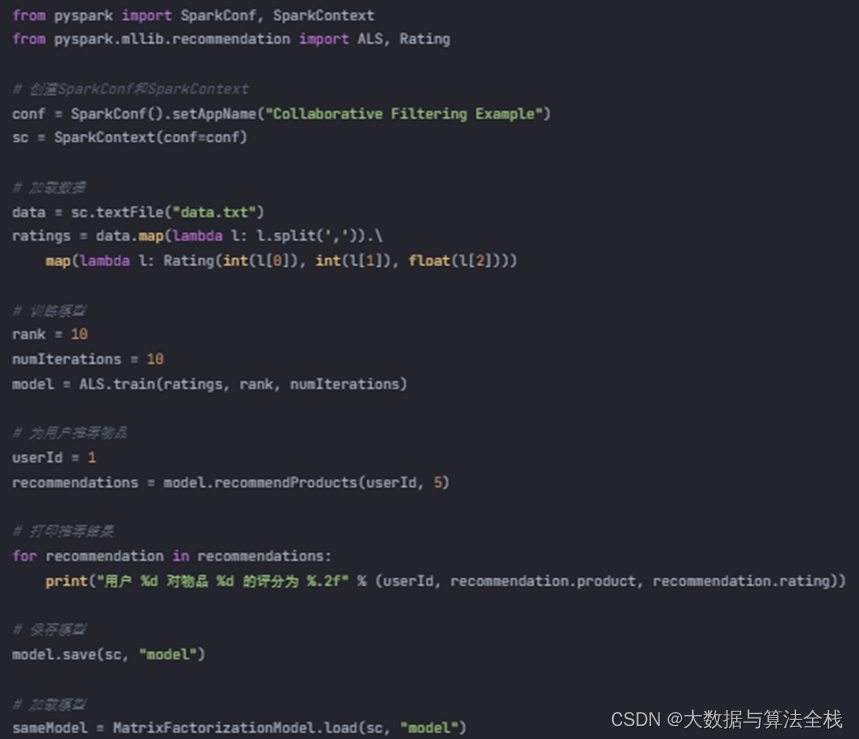
| from pyspark import SparkConf, SparkContext from pyspark.mllib.recommendation import ALS, Rating # 创建SparkConf和SparkContext conf = SparkConf().setAppName("Collaborative Filtering Example") sc = SparkContext(conf=conf) # 加载数据 data = sc.textFile("data.txt") ratings = data.map(lambda l: l.split(',')).\ map(lambda l: Rating(int(l[0]), int(l[1]), float(l[2]))) # 训练模型 rank = 10 numIterations = 10 model = ALS.train(ratings, rank, numIterations) # 为用户推荐物品 userId = 1 recommendations = model.recommendProducts(userId, 5) # 打印推荐结果 for recommendation in recommendations: print("用户 %d 对物品 %d 的评分为 %.2f" % (userId, recommendation.product, recommendation.rating)) # 保存模型 model.save(sc, "model") # 加载模型 sameModel = MatrixFactorizationModel.load(sc, "model") |
代码解释:
(1)首先创建SparkConf和SparkContext。
(2)加载数据,并将数据转化为Rating对象。
(3)使用ALS算法训练模型,设置潜在因子的个数和迭代次数。
(4)根据用户ID获取推荐结果。
(5)输出推荐结果。
(6)保存模型和加载模型。
四、总结
本文介绍了Spark推荐系统和协同过滤的概念和原理,详细解释了基于用户和基于物品的协同过滤算法。同时,给出了使用Spark实现协同过滤推荐算法的完整代码案例,包括参数介绍、代码解释和结果输出。通过学习和理解本文的内容,读者可以更好地了解和应用Spark推荐系统和协同过滤算法。



















 2871
2871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











