







一、介绍
R语言是一种用于统计分析和数据可视化的编程语言,而Spark是一个开源的大数据处理框架。R语言和Spark的互操作性是指在Spark环境中使用R语言进行数据分析和处理。R语言和Spark的互操作性可以帮助用户在大数据环境下充分利用R语言的数据分析和统计建模能力。
二、为什么需要R语言和Spark的互操作性
- R语言拥有丰富的数据分析和统计建模库,可以方便地进行各种数据处理和分析任务。而Spark是为大数据处理而生的框架,具有分布式计算能力。将两者结合起来可以充分发挥各自的优势,提高数据处理和分析的效率和性能。
- R语言和Spark的互操作性可以帮助用户在大规模数据集上进行高效的统计分析和建模。用户可以利用R语言的强大功能进行数据探索、可视化、建模等操作,并利用Spark的分布式计算能力进行大规模数据处理和分析。
- R语言和Spark的互操作性可以帮助用户更好地利用R语言生态系统中的各种扩展包和工具。R语言拥有丰富的生态系统,用户可以通过在Spark环境中使用R语言来调用和集成这些扩展包和工具,从而实现更复杂的数据分析和处理任务。
三、R语言和Spark的互操作性的实现方式
R语言和Spark的互操作性可以通过以下几种方式实现:
- SparkR:SparkR是Spark提供的一个R语言接口,用户可以在Spark环境中使用R语言进行数据分析和处理。SparkR提供了一系列的R语言函数和接口,可以方便地与Spark的数据结构进行交互,如DataFrame和RDD。用户可以使用R语言中的各种数据分析和统计建模函数,通过SparkR进行分布式计算和数据处理。
- Sparklyr:Sparklyr是由RStudio开发的一个R语言包,用于在R语言中操作Spark。Sparklyr提供了一系列的函数和接口,可以方便地与Spark进行交互。用户可以使用R语言中的各种数据分析和统计建模函数,通过Sparklyr将任务提交到Spark集群上进行分布式计算和数据处理。
- rJava:rJava是R语言中的一个扩展包,可以用于在R语言中调用Java代码。用户可以使用rJava来调用Spark的Java API,从而在R语言中操作Spark。通过rJava,用户可以利用R语言的各种数据分析和统计建模函数,调用Spark的Java API进行分布式计算和数据处理。
四、使用SparkR进行R语言和Spark的互操作性
下面是一个使用SparkR进行R语言和Spark的互操作性的示例代码:
| # 加载SparkR包 library(SparkR) # 初始化SparkR上下文 sparkR.session(appName = "R and Spark Interoperability") # 创建一个Spark DataFrame df <- createDataFrame(iris) # 使用SparkR中的函数操作DataFrame df_filtered <- filter(df, df$Sepal_Length > 5) # 使用R语言中的函数对DataFrame进行数据分析 summary(df_filtered$Sepal_Length) # 关闭SparkR上下文 sparkR.session.stop() |
在这个示例中,我们首先加载了SparkR包,并通过sparkR.session函数初始化了一个SparkR上下文。然后,我们使用createDataFrame函数创建了一个Spark DataFrame,将R语言中的iris数据集转换为Spark DataFrame。接下来,我们使用filter函数对DataFrame进行筛选操作,保留Sepal_Length大于5的行。最后,我们使用R语言中的summary函数对筛选后的DataFrame的Sepal_Length列进行了统计分析。
五、使用Sparklyr进行R语言和Spark的互操作性
下面是一个使用Sparklyr进行R语言和Spark的互操作性的示例代码:
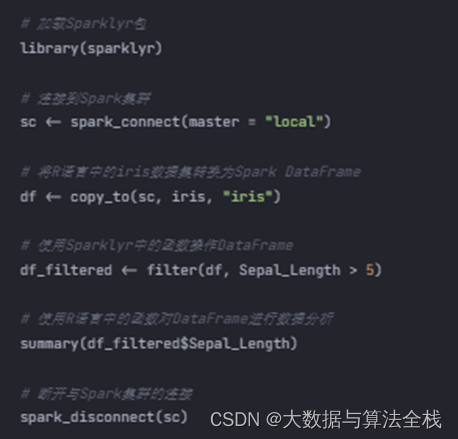
| # 加载Sparklyr包 library(sparklyr) # 连接到Spark集群 sc <- spark_connect(master = "local") # 将R语言中的iris数据集转换为Spark DataFrame df <- copy_to(sc, iris, "iris") # 使用Sparklyr中的函数操作DataFrame df_filtered <- filter(df, Sepal_Length > 5) # 使用R语言中的函数对DataFrame进行数据分析 summary(df_filtered$Sepal_Length) # 断开与Spark集群的连接 spark_disconnect(sc) |
在这个示例中,我们首先加载了sparklyr包,并通过spark_connect函数连接到Spark集群。然后,我们使用copy_to函数将R语言中的iris数据集转换为Spark DataFrame,并指定名称为"iris"。接下来,我们使用filter函数对DataFrame进行筛选操作,保留Sepal_Length大于5的行。最后,我们使用R语言中的summary函数对筛选后的DataFrame的Sepal_Length列进行了统计分析。
六、总结
R语言和Spark的互操作性可以帮助用户在大数据环境下充分利用R语言的数据分析和统计建模能力。通过SparkR和Sparklyr等工具,用户可以在Spark环境中使用R语言进行数据处理和分析,从而提高数据处理和分析的效率和性能。同时,用户可以充分利用R语言生态系统中的各种扩展包和工具,通过在Spark环境中使用R语言调用和集成这些扩展包和工具,实现更复杂的数据分析和处理任务。
















 499
499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











