







文章目录
The Sparse Vector Technique稀疏向量技术
1.学习目标
- 描述稀疏向量技术和使用它的原因
- 定义并实现阈值以上
- 稀疏向量技术在迭代算法中的应用
我们已经看到了一种机制的例子——指数机制——它通过保留一些信息来实现低于预期的隐私成本。
上一章节我们学习了指数机制,它有更低的隐私机制的消费。SVT同样可以做到,稀疏向量技术对一个数据集上的灵敏度为1查询流进行操作,它释放通过测试的流中第一个查询的标识,而不是其他内容。
SVT的优点是,无论考虑多少个查询,它都会产生固定的总隐私成本。
这篇博客描述稀疏矢量技术及其使用原因,并且定义并实现阈值以上的SVT。在迭代算法中应用稀疏向量技术。
2.Above Threshold高于阙值算法
这是一种算法,DWork写的。SVT最基本一种实例是Above Threshold算法
输入:sensitivity-1查询流、数据集D、阙值T以及隐私参数ϵ
该算法保留ϵ-差分隐私
下面这段话引用大佬的文章链接: https://blog.csdn.net/qq_41691212/article/details/121579532
可以细看
在某些情况下,我们只会关心知道高于某个阈值的查询的标识。在这种情况下,我们希望通过放弃对明显低于阈值的查询的数字答案,而仅报告这些查询确实低于阈值,从而获得本质的分析。(如果我们这样选择的话,我们也将能够获得阈值以上查询的数字值,而只需花费额外的费用)。这类似于我们在3.3节中的“Report Noisy Max”机制中所做的事情,实际上,对于非交互式或脱机情况,可以选择迭代该算法或指数机制。
Algorithm
我们首先论证了 AboveThreshold 算法是私有的,并且是准确的,该算法专门针对一个高于阈值的查询。算法的具体过程很简单,输入阈值,先对阈值加噪。对于每个查询加拉普拉斯噪声,如果加噪后的结果大于加噪的阈值则释放回答,构造拒绝回答。
1、⊥为永假含义,拒绝回答
2、⊤为永真含义,释放回答

AboveThreshold算法(近似地)返回结果超过阈值的查询中的第一个查询的索引。该算法通过有时返回错误的索引来保护差别隐私。有时,返回的索引可能是结果没有超过阈值的查询,有时,索引可能不是第一个查询结果超过阈值的索引。
import matplotlib.pyplot as plt
plt.style.use('seaborn-whitegrid')
import pandas as pd
import numpy as np
adult = pd.read_csv("../data/adult_with_pii.csv")
def laplace_mech(v, sensitivity, epsilon):
return v + np.random.laplace(loc=0, scale= sensitivity / epsilon)
def pct_error(orig, priv):
return np.abs(orig - priv) * 100.0
# 相当于满足第一个满足条件的下标呗
def above_threshold(queries, df, T, epsilon):
T_hat = T + np.random.laplace(loc=0, scale= 2/ epsilon)
for idx, q in enumerate(queries):
nu_i = np.random.laplace(loc=0, scale= 4/ epsilon)
if q(df) + nu_i >= T_hat:
return idx
return -1 # the index of the last element
该算法通过生成一个噪声阈值T_hat来工作,然后将有噪声的查询答案(q(i) + nu_i)与噪声阈值进行比较,算法返回第一个成功比较的索引。
让人有点惊讶的是,这个算法的隐私成本只有𝜖,因为它可能会计算出许多查询的答案。特别地,这个算法的简单版本可能会先计算所有查询的噪声答案,然后选择第一个值高于阈值的查询的索引:
代码如下
def naive_above_threshold(queries, df, T, epsilon):
for idx, q in enumerate(queries):
nu_i = np.random.laplace(loc=0, scale= 1/ epsilon)
if q(df) + nu_i >= T:
return idx
return None # the index of the last element
对于长度为𝑛的查询列表,该版本根据顺序组合保留了𝑛𝜖-差分隐私。
为什么AboveThreshold做得这么好?正如我们在指数机制中看到的,顺序组合将允许AboveThreshold释放比实际更多的信息。我们算法的简单版本可以释放超过阈值的每个查询的索引(不仅仅是第一个)。加上嘈杂的查询答案本身,并且它仍然可以保留nϵ-差分隐私。事实是,AboveThreshold保留了所有这些信息,这允许对隐私成本进行更严格的分析。
3.Applying the Sparse Vector Technique应用稀疏向量技术
运行很多查询的时候很有用诶,但我们只关心其中一个问题的答案(或其中的一小部分)。事实上,正是这个应用程序给了这项技术一个名字,当查询向量稀疏时,它最有用-大多数答案都没有超过阈值。
我们已经看到了这种情况的一个完美例子,为求和查询选择一个截断边界。早些时候,我们采用了类似于上面定义的AboveThreshold的简单版本的方法,在许多不同的裁剪边界下计算噪声答案,然后选择答案变化不大的最低的那个。自己理解:趋于稳定的一个程度。
我们可以用稀疏向量技术做得更好。考虑这样一个查询,它截取了数据集中每个人的年龄,然后把它们加起来:
def age_num_query(df, b):
return df['Age'].clip(lower=0, upper=b).sum()
print(age_num_query(adult, 30))
为b选择一个好的值的朴素算法是为b的许多值获得差分私有答案,在值停止增长时返回最小的一个:
def naive_select_b(query, df, epsilon):
bs = range(1, 1000, 10)
best = 0
threshold = 10
epsilon_i = epsilon / len(bs)
for b in bs:
# print('这里 敏感度/epsilon_i 的比值', b / epsilon_i, 'b的值', b, 'epsilon_i的值', epsilon_i)
r = laplace_mech(query(df, b), b, epsilon_i)
# if the new answer is pretty close to the old answer, stop
if r - best <= threshold:
return b
# otherwise update the "best" answer to be the current one
else:
best = r
# 没有满足条件的就返回最后一个好了
return bs[-1]
naive_select_b(age_num_query, adult, 1)
# print(naive_select_b(age_num_query, adult, 1))
我们可以在这里使用SVT吗?我们只关心一件事:age_sum_query(df, b)中b值在哪里停止增长。但是,age_sum_query(df, b)的敏感度是b ,因为在df中添加或删除行最多可以改变的总和是b;要使用 SVT,我们需要构建一个 1-sensitive查询流。
但是,我们真正关心的值是查询的答案是否在b 的特定值(即age_sum_query(df, b) - age_sum_query(df, b + 1))处更改。
当我们像df添加一行以后,第一个查询增加b,第二个查询增加b+1。
因此,敏感度为∣ b − ( b + 1 ) ∣ = 1 - 因此每个查询将根据需要为 1-sensitive!当b 的值接近最佳值时,我们上面定义的差值将接近 0:
bs = range(1, 150, 5)
query_results = [age_num_query(adult, b) - age_num_query(adult, b+1) for b in bs]
plt.xlabel('Value of "b"')
plt.ylabel('Change in Query Output')
plt.plot(query_results)
plt.show()
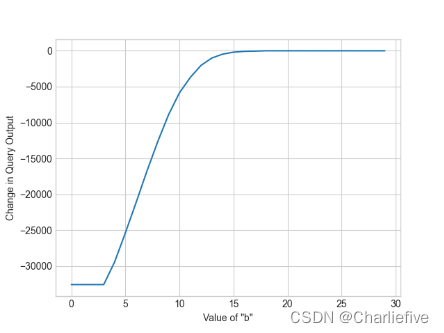
让我们定义一个差异查询流,并使用AboveThreshold使用稀疏向量技术确定b的最佳值的索引。
请注意,无论bs列表有多长并不重要 - 无论其长度如何,我们都将获得准确的结果(并支付相同的隐私费用)。SVT真正强大的效果是消除了隐私成本对我们执行的查询数量的依赖。尝试为bs更改上面的范围,然后重新运行下面的图。您将看到输出不依赖于我们尝试的b值的数量 - 即使列表包含数千个元素!
这部分代码中构建查询流的方法值得我们学习!
bs = range(1, 150, 5)
queries = [creat_query(b) for b in bs]
print(queries)
epsilon = .1
# bs[above_threshold(queries, adult, 0, epsilon)]
plt.xlabel('Chosen Value of "b"')
plt.ylabel('Number of Occurrences')
plt.hist([bs[above_threshold(queries, adult, 0, epsilon)] for i in range(1000)])
plt.show()
通过修改range的值,我们可以进行不同数量级实验。
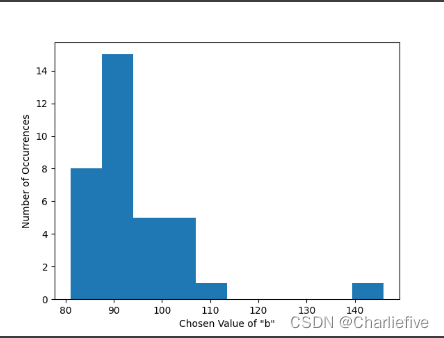
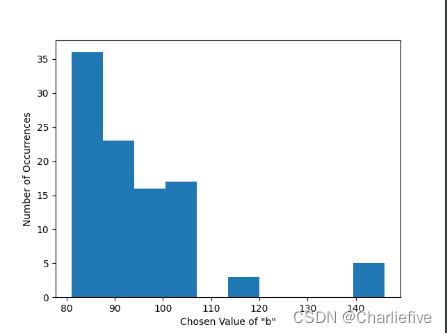
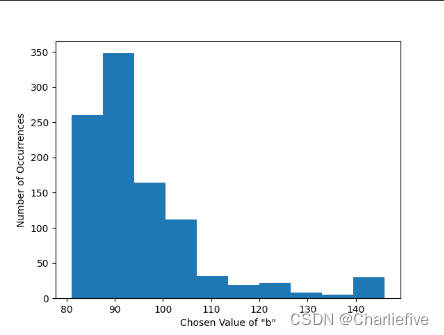
我们可以使用SVT为求和查询(并使用此算法进行平均查询)构建一个自动计算剪切参数的算法。
def auto_avg(df, epsilon):
def create_query(b):
return lambda df: df.clip(lower=0, upper=b).sum() - df.clip(lower=0, upper=b+1).sum()
# 构建查询流
bs = range(1, 150000, 5)
queries = [create_query(b) for b in bs]
# 使用AboveThreshold以及1/3的隐私预算
epsilon_svt = epsilon / 3
final_b = bs[above_threshold(queries, df, 0, epsilon_svt)]
# Compute the noisy sum and noisy count, using 1/3 of the privacy budget for each
epsilon_sum = epsilon / 3
epsilon_count = epsilon / 3
noisy_sum = laplace_mech(df.clip(lower=0, upper=final_b).sum(), final_b, epsilon_sum)
noisy_count = laplace_mech(df.clip(lower=0, upper=final_b).sum(), 1, epsilon_count)
return noisy_sum / noisy_count
auto_avg(adult['Age'], 1)
0.9999879592915891
auto_avg(adult['Capital Gain'], 1)
1.0335597145369202
此算法调用三个差分隐私机制:AboveThreshold一次,拉普拉斯机制两次,每个机制都有1/3 的隐私预算。通过顺序组合,它满足ϵ-差分隐私。因为我们可以自由地测试b的可能值范围非常广泛,所以我们能够对许多不同尺度上的数据使用相同的auto_avg函数!例如,我们也可以在资本收益capital gain列上使用它,即使它与年龄列的尺度非常不同。
面对大规模的数据,我们可以通过增加步长(5,在上面的实现中)或通过指数尺度构建bs来降低此成本。
4.Returning Multiple Values返回多个值
在上面的应用程序中,我们只需要超过阈值的第一个查询的索引,但在许多其他应用程序中,我们希望找到所有此类查询的索引。
我们可以使用SVT来做到这一点,但我们必须支付更高的隐私成本。我们可以实现一个名为Sparse的算法来完成任务,使用一种非常简单的方法:
步骤:
- 开始一段查询流 q s = { q 1 , … , q k } q s=\left\{q_{1}, \ldots, q_{k}\right\} qs={q1,…,qk}
- AboveThreshold在qs上运行,以了解超过阈值的第一个查询的索引i
- 使用 q s = { q i + 1 , … , q k } q s=\left\{q_{i+1}, \ldots, q_{k}\right\} qs={qi+1,…,qk}重新启动算法(转到第一步)(即剩余的查询)
算法调用AboveThreshold n次,每次调用的隐私参数为ϵ,则通过顺序组合满足nϵ-差分隐私。如果要确定总隐私成本上限,我们需要绑定n - 因此算法Sparse要求分析师在调用AboveThreshold次数上指定上限c 。
def sparse(queries, df, c, T, epsilon):
idxs = []
pos = 0
epsilon_i = epsilon / c
while pos < len(queries) and len(idxs) < c:
next_idx = above_threshold(queries[pos:], df, T, epsilon_i)
if next_idx == -1:
return idxs
pos += next_idx
idxs.append(pos)
pos += 1
return idxs
epsilon = 1
sparse(queries, adult, 3, 0, epsilon)
[18, 20, 22]
[19, 20, 21]
[21, 31, 38]
输出同样略有偏差...
通过顺序组合,稀疏算法满足𝜖-差分隐私。AboveThreshold每次调用
ϵ
i
=
ε
c
\epsilon_{i}=\frac{\varepsilon}{c}
ϵi=cε.
Dwork 和 Roth 中描述的版本使用高级组合,为每个AboveThreshold调用设置ϵ 值,以便总隐私成本为ϵ(zCDP或 RDP 也可用于执行组合)。
5.Application: Range Queries应用:范围查询
范围查询询问:“数据集中存在多少行,其值位于范围(𝑎,𝑏)中?”范围查询是计数查询,因此它们具有敏感性1;但是,我们不能对一组范围查询使用并行组合,因为它们检查的行可能重叠。
考虑一组跨年龄范围的查询(即形式为"有多少人在a aa和b bb之间有年龄?"的查询)。我们可以随机生成许多这样的查询:
def age_range_query(df, lower, upper):
df1 = df[df['Age'] > lower]
df2 = df1[df1['Age'] < upper]
return len(df2)
def create_age_range_query():
lower = np.random.randint(30, 50)
upper = np.random.randint(lower, 70)
return lambda df: age_range_query(df, lower, upper)
range_queries = [create_age_range_query() for i in range(10)]
print(type(range_queries))
results = [q(adult) for q in range_queries]
此类范围查询的答案差异很大 ,某些范围创建具有小计数的微小(甚至空)组,而其他范围创建具有高计数的大型组。在许多情况下,我们知道小团体在差分隐私下会有不准确的答案,所以即使运行查询也没有多大意义。我们想做的是了解哪些查询值得回答,然后为这些查询支付隐私费用。
我们可以使用稀疏向量技术来做到这一点。首先,我们将确定流中超出我们决定的"好"阈值的范围查询的索引。然后,我们将使用Laplace机制来为这些查询找到不同的私有答案。总隐私费用将与高于阈值的查询数成正比,而不是查询总数。如果我们预计只有几个查询高于阈值,这可能会导致隐私成本小得多。
def range_query_svt(queries, df, c, T, epsilon):
# 首先,运行Sparse来获取“好的”查询的索引
sparse_spsilon = epsilon / 2
indices = sparse(queries, adult, c, T, sparse_spsilon)
# 然后,在每个“好的”查询上运行拉普拉斯机制
laplace_epsilon = epsilon / (2*c)
results = [laplace_mech(queries[i](df), 1, laplace_epsilon) for i in indices]
return results
print(range_query_svt(range_queries, adult, 5, 10000, 1))
[11414.679057297042, 13508.569842254232, 14097.522976966913, 12053.201520475446]
[10520.973451022277, 15194.215658266863, 12569.098710094859]
[20997.71792852193, 18264.232192451385]
[12903.85809791682, 14087.12574864797, 20466.540367649446]
使用这种算法,我们支付一半的隐私预算来确定第一个𝑐查询,这些查询位于10000的阈值之上,然后支付另一半预算来获得这些查询的噪声答案。如果超过阈值的查询数量与总数相比微不足道,那么我们就能够使用这种方法获得更准确的答案。
六、总结
- 稀疏向量技术对数据集上的
敏感度为1的查询流进行操作。它释放流中第一个通过测试的查询的标识,而不是其他任何内容。SVT的优点是,无论考虑多少查询,它都会产生固定的总隐私成本。 - 在这种情况下,我们希望通过放弃对明显低于阈值的查询的数字答案,而仅报告这些查询确实低于阈值,从而获得本质的分析。(如果我们这样选择的话,我们也将能够获得阈值以上查询的数字值,而只需花费额外的费用)。该技术很简单:
添加噪音并仅报告噪声值是否超过阈值。 - 该AboveThreshold算法通过有时返回错误的索引来保护差分隐私。有时,返回的索引可能用于结果未超过阈值的查询,有时,索引可能不是查询结果超过阈值的第一个索引。
- 为什么AboveThreshold做得更好?正如我们在指数机制中看到的那样,
顺序组合将允许AboveThreshold发布比实际信息更多的信息。特别是,我们的算法的朴素版本可以释放每个超过阈值的查询的索引(不仅仅是第一个查询),加上嘈杂的查询答案本身,并且它仍然可以保留nϵ-差分隐私。AboveThreshold隐瞒所有这些信息的事实允许对隐私成本进行更严格的分析。















 2647
2647











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









