







文章目录
1 神经网络的数据表示
张量
一个数据容器,包含的数据几乎总是数值数据。张量是矩阵向任意维度的推广。
张量的维度叫作轴。
1.1 标量(0D张量)
标量(Scaler,也叫作标量张量、零维张量、0D张量),仅包含一个数字。
标量张量有0个轴(ndim==0),张量轴的个数也叫作阶(rank)。
1.2 向量(1D张量)
向量(Vector,一维张量、1D张量),由数字组成的数组。
X = np.array([12, 3, 6, 14, 7])
这个向量有5个元素,所以称为5D向量。不要把5D向量和5D张量混淆,前者只有一个轴,沿着轴有5个维度,而5D张量有5个轴。
维度可以表示沿着某个轴上的元素个数(比如5D向量),也可以表示张量中轴的个数(比如5D张量)。
1.3 矩阵(2D张量)
矩阵(matrix,二维张量、2D张量),由向量组成的数组。
矩阵有2个轴(行和列),第一个轴上的元素叫做行,第二个轴上的元素叫做列。
1.4 3D张量与更高维张量
3D张量,由多个矩阵组成的数组。
将多个3D张量合成数组,创建出4D张量,以此类推。
深度学习处理的一般是0D到4D的张量,但处理视频数据时可能遇到5D张量。
1.5 关键属性
张量由以下三个关键属性定义:
- 轴的个数(阶)
即ndim,3D张量有3个轴。 - 形状
这是一个整数数组,表示张量沿每个轴的维度大小(元素个数)。例如,矩阵的形状为(3, 5),向量形状只包含一个元素,比如(5,);而标量的形状为空,即()。 - 数据类型
这是张量中所包含数据的类型。
1.6 在Numpy中操作张量
张量切片:选择张量的特定元素。
(1)常见的切片运算
例1:选择第10~100个数字,并将其放在形状为(90,28,28)的数组中。
# shape == (90, 28, 28)
my_slice = train_images[10:100]
my_slice = train_images[10:100, :, :] # 同上,:等同于选择整个轴
my_slice = train_images[10:100, 0:28, 0:28] # 同上
(2)还可以沿着每个张量轴在任意两个索引之间进行选择。
例2:在所有图像的右下角选出14*14像素的区域。
my_slice = train_images[:, 14:, 14:]
(3)也可以使用负数索引,表示与当前轴终点的相对位置。
例3:在图像中心裁剪出14像素*14像素的区域。
my_slice = train_images[:, 7:-7, 7:-7]
1.7 数据批量的概念
通常来说,深度学习中所有数据张量的第一个轴(0轴)都是样本轴(sample axis,也称样本维度)。
此外,深度学习模型不会同时处理整个数据集,而是将数据拆分为小批量,对于这种批量张量,第一个轴叫做批量轴(batch axis, 批量维度)。
1.8 现世界中的数据张量
- 向量数据:2D张量,形状为(samples, features)
- 时间序列数据或序列数据:3D张量,形状为(samples, timesteps, features)
- 图像:4D张量,形状为(samples,height, width, channels)或(samples, channels, height, width)
- 视频:5D张量,形状为(samples,frames,height,width,channels)或(samples,frames,channels,height,width)
1.9 向量数据
对于这种数据集,每个数据点都被编码为一个向量,因此一个数据批量被编码为2D张量,其中第一个轴是样本轴,第二个轴是特征轴。
1.10 时间序列数据或序列数据
当时间(或序列顺序)对于数据很重要时,应该将数据存储在带有时间轴的3D向量中。每个样本可以被编码为一个向量序列(2D张量),因此一个数据批量就被编码为一个3D张量。
按照惯例,时间轴始终是第2个轴(索引为1)。
形如(样本,时间步长,特征)
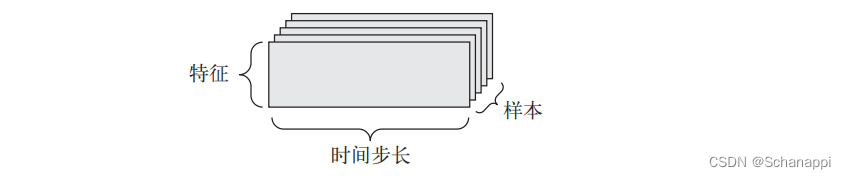
1.11 图像数据
图像通常具有三个维度:高度、宽度和颜色深度。
虽然灰度图像(MNIST数字图像)只有一个颜色通道,因此可以保存在2D张量里。
但按照惯例,图像张量始终都是3D张量。
形如(样本,高度,宽度,颜色通道)–通道在后 TensorFlow使用
或(样本,颜色通道,高度,宽度)–通道在前 Theano使用
Keras框架同时支持以上两种格式。
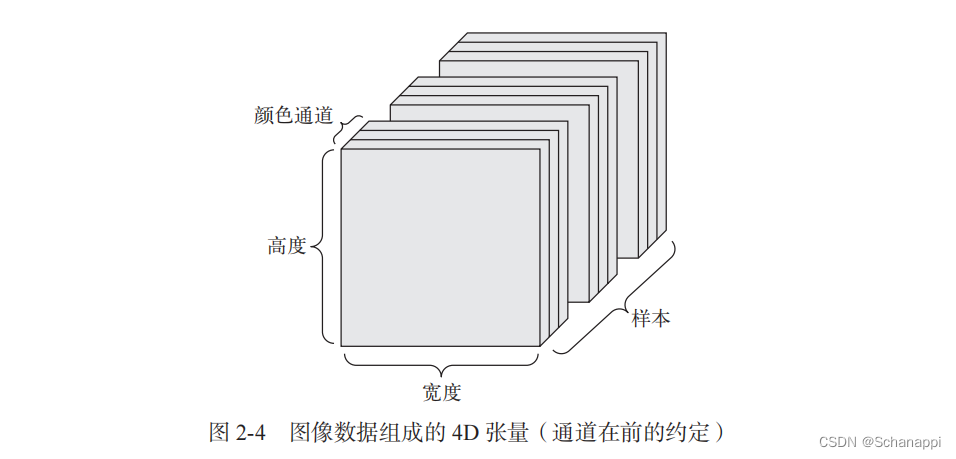
1.12 视频数据
视频可以看作一系列帧:
- 每一帧都是一张彩色图像,因此可以保存在形如(height,width,color_depth)的3D张量中;
- 一系列帧可以保存在形如(frames,height,width,color_depth)的4D张量中;
- 不同视频组成的批量 可以保存在形如(samples,height,width,color_depth)的5D张量中。
2 张量运算
2.1 逐元素运算
relu运算和加法都是逐元素的运算,即该运算独立地应用于张量中的每个元素,它们非常适合大规模并行(向量化)实现。
2.2 广播
1. 概念
如果两个形状不同的张量相加,较小的张量会被广播,以匹配较大的张量。
2. 广播的两个步骤
- 向较小的张量添加轴(广播轴),使其ndim与较大的张量相同;
- 较小的张量沿着新轴重复,使其形状与较大的张量相同。
2.3 张量点积 np.dot
1. 概念
张量点积,也叫张量积,它将输入张量的元素合并在一起,需要和逐元素的乘积区分。
2. 点积概念
- 两个向量之间的点积是一个标量,而且只有元素个数相同的向量之间才能做点积;
- 一个矩阵和一个向量做点积,返回值是一个向量,其中每个元素是y和x每一行之间的点积;
- 两个矩阵x和y做点积,当且仅当x.shape[1]==y.shape[0] 时,才可以做点积,得到形如(x.shape[0],y.shape[1])的矩阵,其元素为x的行与y的列之间的点积。
- 如果两个张量中有一个的ndim大于1,那么dot运算不再对称,即dot(x,y) ≠ dot(y,x)
- 更高维的张量做点积,只要其形状匹配遵循与前面2D张量相同的原则:
(a,b,c,d). (d,) -> (a, b, c)
(a,b,c,d). (d,e) -> (a,b,c,e)
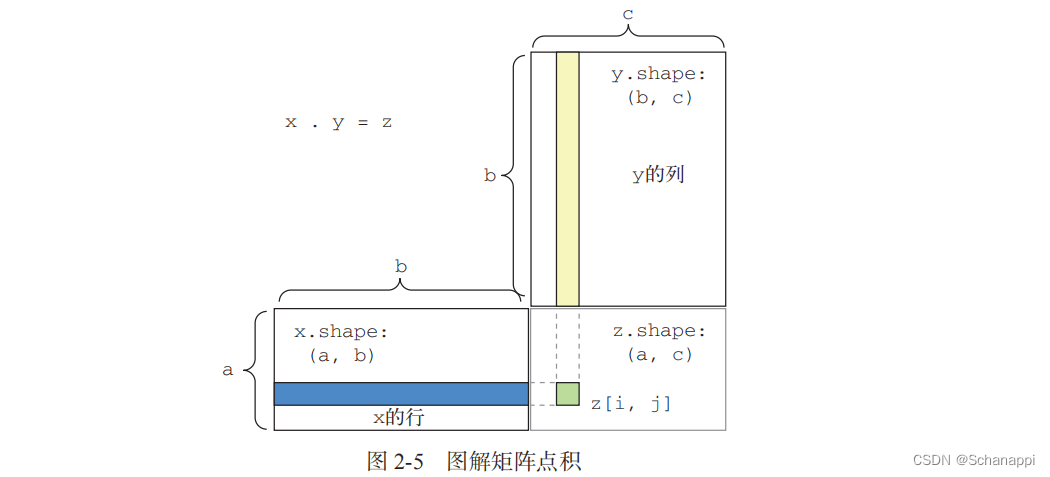
2.4 张量变形
1.定义: 改变张量的行和列,得到想要的形状。变形后张量的元素总个数与初始张量相同。
2.例子
- x.reshape()
- 转置np.transpose(x),将行和列互换,使得x[i, :]变为x[:, i]
3 基于梯度的优化
以下是每个神经层对输入数据进行的变换
output = relu(dot(W, input) + b)
W和b都是张量,被称为该层的权重或可训练参数,分别对应kernel和bias属性。
一开始,这些权重矩阵取较小的随机值,这一步叫做随机初始化。由于W和b都是随机的,因此output肯定不会得到任何有用的表示,所以下一步是根据反馈信号调节权重,这个过程称为训练。
如何调节网络中的权重系数呢?
- 计算损失相对于网络系数的梯度,向梯度的反方向改变系数,从而降低损失。
3.1 导数
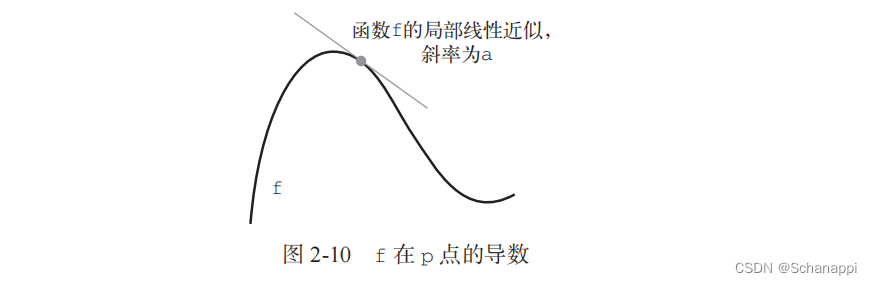
1.斜率a是f在p点的导数:
- 如果a是负的,说明x在p点附近的微小变化导致f(x)减小;
- 如果a是正的,说明x在p点附近的微小变化导致f(x)增大;
- a的绝对值表示增大或减小的速度快慢
2.在神经网络中,目的是使得损失函数f(x)最小化,因此只需要将x沿着导数的反方向移动一小步。
3.2 梯度
1.梯度是张量运算的导数,它是导数这一概念向多元函数导数的推广。
2.f在W0点的导数是一个张量gradient(f)(W0),其形状和W相同,每个系数gradient(f)(W0)[i, j]表示改变W0[i, j]时loss_value变化的方向和大小。gradient(f)(W0)也可以看作表示f(W)在W0附近曲率的张量。因此,可以通过将W向梯度的反方向移动来减小f(W)。
3.3 随机梯度下降
1.小批量随机梯度下降(mini-batch SGD)
- 抽取训练样本x和对应目标y组成的数据批量;
- 在样本上运行网络,得到预测值y_pred;
- 计算网络在这批数据上的损失,衡量y_pred和y之间的距离;
- 计算损失相对于网络参数的梯度(一次反向传播);
- 将参数沿着梯度的反方向移动一点,使得这批数据的损失减少一点。
2.小批量SGD的变体
- 真SGD:每次迭代时只抽取一个样本和目标;
- 批量SGD:每次迭代时在所有数据上运行。
- 优化方法/优化器,包括带动量的SGD、Adagrad、RMSprop,它们在计算下一次权重更新的时候还要考虑上一次权重更新。
其中,动量解决了SGD的两个问题:收敛速度和局部极小点。
3.4 链式求导:反向传播算法
反向传播,从最终损失值开始,从最顶层反向作用至最底层,利用链式法则计算每个参数对损失值的贡献大小。
4 本章小结
- 学习是指找到一组模型参数,使得在给定的训练数据样本和对应的目标值上的损失函数最小化;
- 学习的过程:随机选取包含数据样本及其目标值的批量,并计算批量损失相对于网络参数的梯度。随后将网络参数沿着梯度的反方向移动。
- 整个学习过程之所有能够实现,是因为神经网络是一系列可微分的张量计算,因此利用求导的链式法则来得到梯度函数,这个函数将当前参数和当前数据批量映射为一个梯度值。
- 损失是在训练过程中需要最小化的量,能够衡量当前任务是否已经成功解决。
- 优化器是使用损失梯度更新参数的具体方法。















 742
742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









