






论文链接:Memory Regulation and Alignment toward Generalizer RGB-Infrared Person Re-identification
简述
由于训练集和测试集之间不可忽略的模态间隙和身份类的不重叠,域转移是RGB-红外人再识别中的一个主要问题。 解决固有问题--域转移--的一个关键是强制两个域的数据分布相似。
本文以一种更清晰的方式揭示了这一问题,并提出了一种新的多粒度内存调整和对齐模块(MG-MRA)来解决这一问题。 通过显式地将一个从细粒度到粗语义粒度的潜在变量属性纳入中间特征中,可以缓解模型对已见类判别特征的过度置信度。
贡献
(1)提出了一种多粒度内存调整与对齐(MG-MRA)模块来解决这一问题。 所提出的MG-MRA是一种即插即用的方法,比以前的基于GAN或基于额外数据的方法更有效。
(2)学习到的粗到细原型能够一致地提供不同粒度的领域级语义模板,满足多级语义对齐的要求。
方法

SG-MRA
单粒度存储模块(SG-MRA)包含N个原型,这些原型由固定特征维数C的度量M∈RN×C记录。然后使用基于注意力的寻址算子访问存储器,即存储器读取器,将每个图像分配到备用原型中:
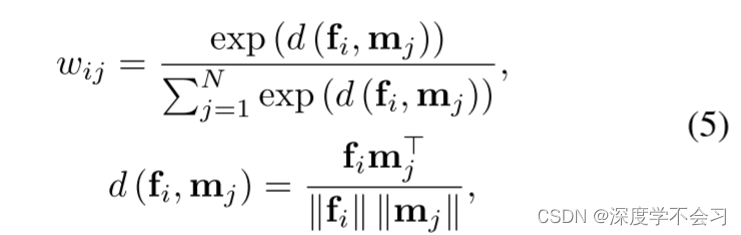
其中fi和mj是来自输入f和原型度量m的特征和原型切片,wij是度量fi和mj之间余弦相似度d(·,·)的归一化权重。 因此,从特征F分配的原型H可以计算为:

MG-MRA
在单粒度存储模块的基础上,我们构建了一个多粒度存储模块(MG-MRA),MG-MRA由层次语义原型M组成,即部分-实例-语义,以避免过度抽象。 实例原型和语义原型是从以前的低级原型中总结出来的。 因此,尽管原型中的内存槽跨越不同的语义多样性,但M是共享的,以表示所有样本的通用概念。定义了2×(P×I×S×NC)×C形状的原型度量M,其中P、I和S分别为零件、实例和语义层的每个原型数预定义,NC为类别数。 在总结语义原型之前,每个部分和实例原型都被复制为两种模态。 因此,对于模态内部差异,我们将单个模态的低层代表模式保留在部分原型和实例原型中,然后在语义层将它们联合对齐。 如图2所示,每个高级原型项目可以通过对其低级原型项目的范围进行求和来获得。 例如,实例原型子度量MINS的第I行MINS,I可以被看作是从(P×S×NC)×(I-1)+1到(P×S×NC)×I的MPart的加权子段:

其中α是通过FC+Sigmoid组合计算的权值标量来学习嵌入中心。 类似地,我们可以得到MSEM∈MSEM,然后根据方程6,MG-MRA可以表示为:

在实现过程中,将MG-MRA作为辅助分支,仅用于调节训练过程。 我们采用PCB模块来实现基本的最先进的性能,每个条纹特征也从我们的存储模块中检索相应的原型。

Loss

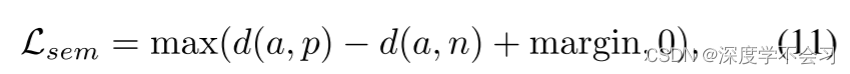
















 1180
1180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









