






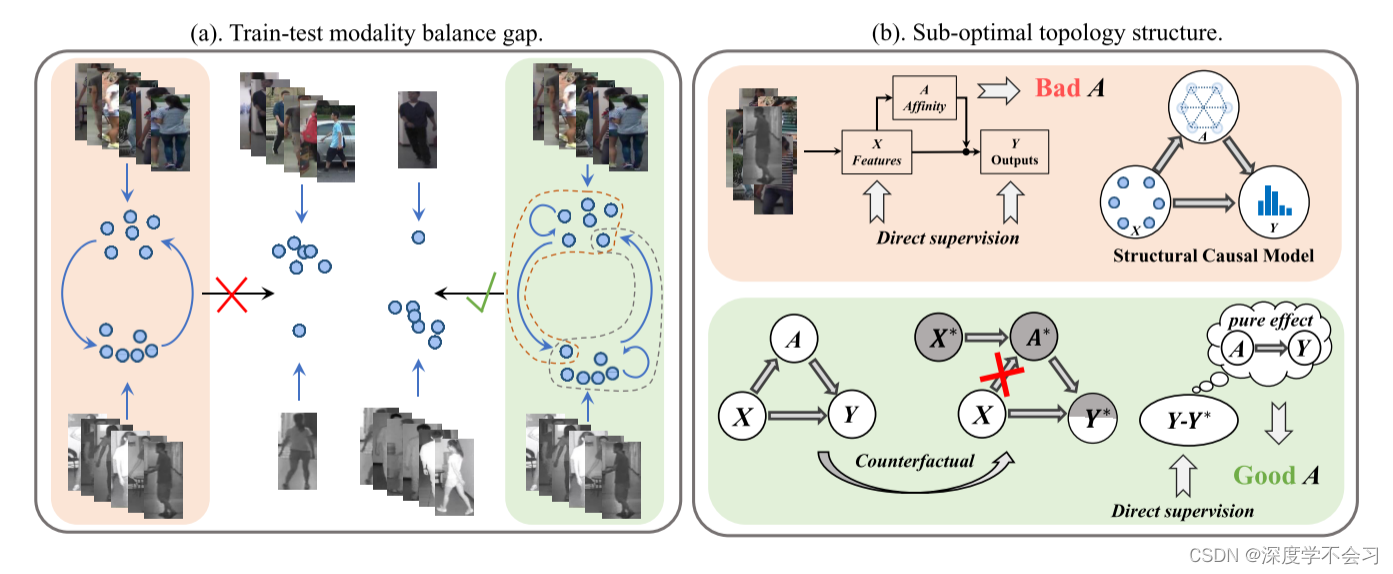
简介:基于图的模型计算不同人之间的图拓扑结构 (亲和力),然后将信息传递以实现更强的特征。基于图的可见光人再识别任务 (VI-ReID) 中的方法由于以下两个问题:
(1)训练-测试模态平衡间隙,两种模态数据的数量在训练阶段是平衡的,但在推理上却极不平衡,导致基于图形的VI-ReID方法的泛化程度较低。
(2)端到端学习方式对图模块造成次优拓扑结构,分析了主干特征和图特征的联合学习削弱了图拓扑的学习。
在本文中,提出了一种反事实干预特征转移 (CIFT) 方法来解决这些问题。设计了同质和异质特征传输 (H2FT),以通过两种独立类型的精心设计的图形模块和不平衡场景模拟来减少训练-测试下模态平衡差距。此外,提出了一种反事实关系干预 (CRI),利用反事实干预和因果效应工具来突出拓扑结构在整个训练过程中的作用,从而使图拓扑结构更加可靠。
H2FT旨在从训练算法和模型设计两个方面减小训练-测试模态平衡差距。通过对平衡训练数据进行重组,模拟不平衡模态分布场景,并让H2FT在该环境下进行训练,指导模型适应不平衡模态分布的情况。
CRI通过突出图结构(预测的亲和力)在总的端到端训练中的作用来解决次优图拓扑问题。 利用因果推理的工具来实现这一动机。在图的结构因果模型中表示我们的图模块 1(b)并将图模块的训练目标从仅最大化概率似然修改为最大化概率似然和总间接效应(TIE)的组合。 前一项指导整个模型对每个人图像的身份进行分类。 后者实质上等于最大化原始输出与仅由亲和力变化贡献的反事实输出之间的差异(图1(B)绿色背景),使模型能够感知到图亲和力的作用。
方法
(1)针对训练-测试模态平衡差距,提出了一个同质和异质特征转移(H2FT)模块,包括两种独立的设计良好的图形模块和一个非平衡场景模拟,它更适合于处理非平衡模态分布场景中的样本交互。
(2)针对次优拓扑结构问题,提出了一种新的反事实关系干预算法。 它利用反事实干预和因果关系工具突出拓扑结构在特征传递模块中的作用,使整个模块的训练更加泛化。
基于图的VI-Reid模型综述
步骤1:模态不变特征提取。
步骤2:特征增强。
步骤3:计算结果。
步骤4:特征学习。
基于图的VI-Reid泛化能力差的分析
(1)训练-测试模态平衡间隙
训练-测试模态平衡差距是由训练和测试阶段模态信息比的差异造成的。在训练阶段,CM-SSFT和DDAG都在包括相等数目的可见和红外图像的批数据上传递消息和传递特征。 因此,训练中提供的两种情态信息的比例为1:1。 但在测试中,可用数据为{q,g},由一个查询样本q和一个图库集g组成。这里,两个图库集之间的模态信息比为1:ng,其中ng是图库集的大小。 很明显,训练和测试的模态信息比率有很大的不同。
(2)次优拓扑结构
用CM-SSFT和DDAG计算的亲和力A可以反映不同样品之间的关系。 因此,A可以解释为给定数据上的一种图拓扑结构。 但是认为现有的图Vi-Reid模块学习的结构都是次优的,因为是端到端的联合学习。
CM-SSFT和DDAG都同时增加了对主干特征和图特征的监督,而对亲和力A没有任何限制,不利于推广。 对于图模块,如Transformer或图关注力,以端到端的联合方式训练A是常见的。 但是这里的情况不同,对主干的监督使得主干特征在训练集中具有判别性。 此时,一个具有标准质量的A可以使最终输出属于特征学习约束1,因此结构A无法得到太多有用的指导。 如果没有A的监督,图形模块很难捕捉到不同样本之间的复杂关系。
以上分析表明,提高基于图的VI-Reid泛化能力的关键在于减少训练-测试之间的模态平衡差距,并在端到端联合学习中引入额外的约束条件。 在这个方向上,我们提出了一个反事实干涉特征传递模块,并展示了该模型是如何解决这些问题的。
Counterfactual Intervention Feature Transfer
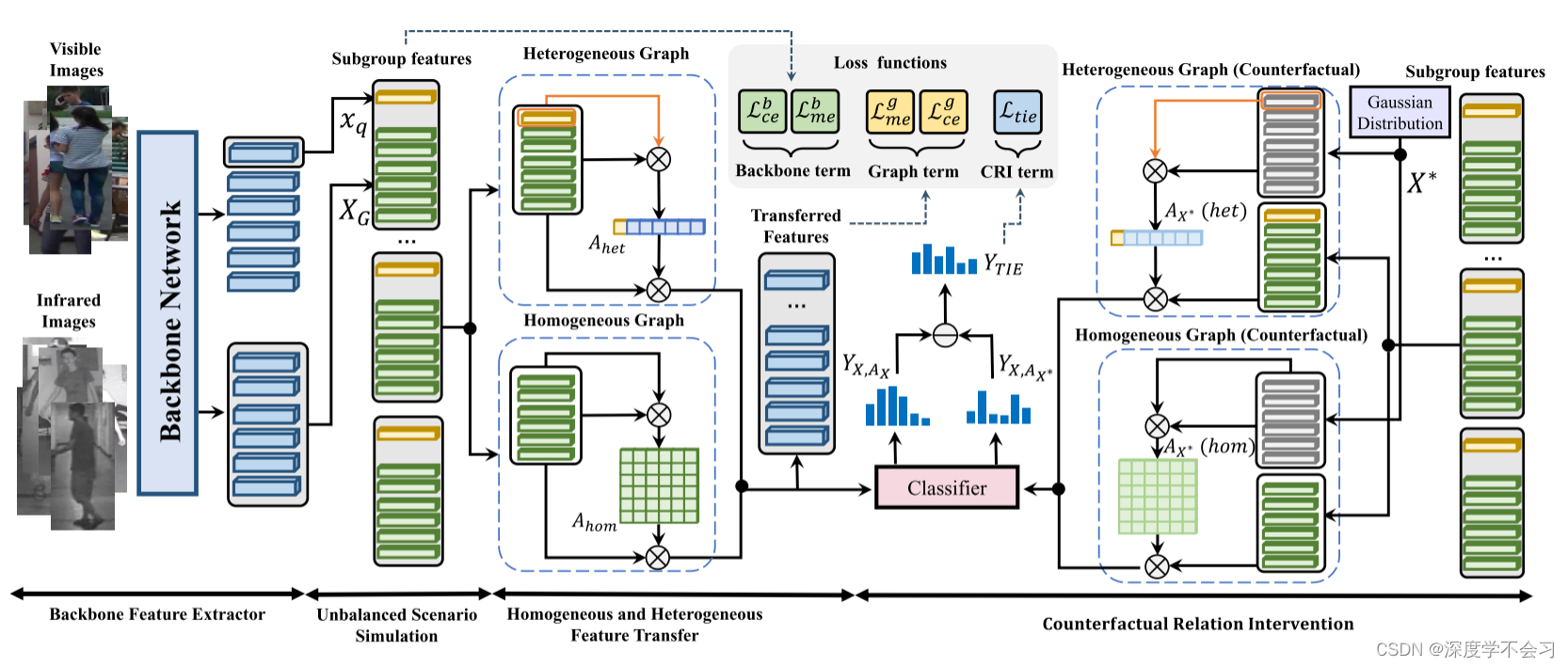
同质和异质特征转移
对于一个给定的批量数据,包括N幅可见光和N幅红外图像,我们的目标是模拟不平衡模态分布场景来训练我们的模型。 批处理数据被分成一系列组,每个组由来自一个模态的单个图像(视为查询Q)和n个其他模态图像(视为图库集G)组成。 具体地说,每个组可以具有一个可见图像和n个红外图像,或者一个红外图像和n个可见图像。 每个组都用1:N的模态比模拟场景,这在推理设置中是相似的(一个查询vs更多的图库)。 因此,在此条件下训练的H2FT能够适应单个查询的推理,而不影响泛化能力。
在这种背景下,情态信息是相当不平衡的。 被视为查询的样本只能与来自其他模态的N个图像交互。 对于图库数据,模态间的交互是微不足道的,因为它只是引入了固定查询所提供的信息,这些信息是冗余的,甚至是噪声的。 为了避免这一问题,我们为查询数据和图库数据分别提供了一个异构和同构的图形模块,就像图一样 2场演出。 它的方程式可以写成:
![]()
其中和
分别表示查询特征向量和图库特征矩阵。 [•,•]表示列维度中的串联。 函数V(·)是一个具有可学习权值的bnneck,用于增强特征。
和
表示查询和图库集的转移特征。A表示其对应样本之间关系的均值亲和矩阵。 为了实现A,我们首先根据输入特征计算相似度矩阵:
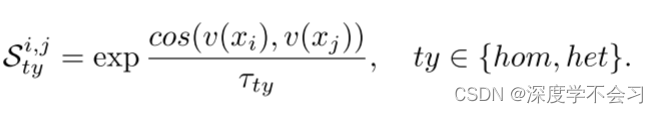
COS(·,·)是衡量样本间相似度的余弦距离函数。 τ是调节总相似分布平滑度的温度参数。 对于异质过程和同质过程,由于模态内和模态间的相似性差异很大,我们采用了不同的τ。 为了滤除噪声关系,我们使用近邻选择函数t(•,k)来保持每行相似度矩阵中的top-k值:s'=t(s,k)。 最后亲和矩阵计算如下:
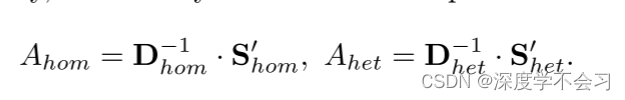
是S'的拉普拉斯矩阵,用于归一化总亲和力。在得到最终的转移特征F后,由分类层导出logits Y,并利用交叉熵损失对Y进行训练,该训练等于最大似然度,以保持特征携带更丰富的身份信息。 然后将度量学习项加入到输出中,使特征携带更多的判别信息。 沿着这条管道,非平衡场景模拟使模型适应单一查询推理场景。 异构和同构两种消息传递过程引导查询样本与潜在的图库进行交互,而图库数据只在自身之间进行消息传递,保留了每组数据之间非平凡的信息交互过程,更适合于解决这种不平衡的情况。
反事实关系干预
为了增加对亲和力A的额外监督,并保持整个端到端的训练管道,提出了突出图拓扑结构在整个学习过程中的作用。 为了这个目标,在这里带来了因果推论的工具。 首先把H2FT表示成结构因果模型(SCM),就像图一样 1(b)显示。 X→A表示亲和计算,X→Y→A表示消息传递过程(包括输出计算)。
从输入X导出输出Y的过程可以看作两种效应:直接效应X→Y和间接效应X→A→Y。H2FT的分类损失等于最大似然,会以端到端的方式影响这两种效应,因此间接效应路径中的A不能得到充分的提高。
为了突出整个训练过程中的A,我们在这里使用总间接效应(TIE)。 首先给出它的方程:
![]()
是我们图形模块的原始输出,这意味着前馈不同的样本特征X并计算它们的输出。 注意,这里的亲和力矩阵表示为
,这意味着亲和力是基于输入特征X计算的。
意味着通过将原始亲和力
替换为一个介入的
*来计算结果,其中X*是手动给出的介入输入。 很明显,
不可能出现在现实世界中,因为特征X和亲和力
*来自不同的输入X和X*,这被称为反事实干预。 因此,将
修改为
等于保持所有势变量不变,只改变亲和力A,它可以显示A引入的纯效应。我们计算该效应的期望,以得到更稳定的效应。 用于计算
*的介入输入特征X*采用高斯分布采样:
![]()
其中Z为标准随机向量,其维数与特征X相同。通过再参数化技巧以端到端的方式学习均值Xμ和立场偏差Xσ。
将交叉熵损失添加到TIE中:ltie=lce(ytie)。 最小化交叉熵损失等于最大化正确类预测的YTIE,这引导模型增加原始输出与反事实输出之间的差距。 很明显,反事实分类结果应该比原始分类结果更差,因为介入的亲和力Ax*通常与输入X不匹配。因此,关于最大限度地提高TIE的直观理解是约束模型增加从好的Ax和坏的Ax*得到的输出之间的差异。 由于其他变量已经固定,模型必须改变AX来增加原始结果的差距增强,导致更好的训练亲和力。















 1270
1270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









