






目录
基于级联聚合的模态协同互补学习在可见光-红外人员识别中的应用
简述
级联聚合的模态协同互补学习网络(MSCLNET)。 基本思想是协同两个模态来构造不同的身份鉴别语义和较少噪声的表示。 然后,在这两种模式的优点下对协同表征进行了补充。 此外,提出了级联聚合策略,用于细粒度的特征分布优化,该策略将子类、类内和类间的特征嵌入进行渐进聚合。
传统的硬样本挖掘和特征聚合方法在实例级优化特征嵌入距离。 这种粗粒度度量学习忽略了所有实例的综合分布。 我们的目标是以级联的方式在不同的层次上进行优化。 其基本思想是根据相同的拍摄摄像机将每个身份的实例细分为若干个子类。 每个子类中的实例更容易聚合,其特征嵌入具有更高的类内相似性。 这样,我们可以逐步限制特征嵌入之间的距离。

红外和可见光优势的演示。 红外图像包含相似的语义,其特征嵌入更容易聚合。 可见的图像包含不同的语义,即使它们描述的是同一个人。
模态协同互补学习网络(MSCLNET)。 它旨在减少类内差异,增强身份识别的表征。,通过构造一个与模态协同模块(MS)的协同表示,保留了可见光和红外模态固有的语义多样性和身份相关性。 然后,通过上图所显示的两种模式的具体优势,增强了协同表征 ,MC包含这两个平行的互补过程,具有可见和红外表示。 一方面,它从可见的模态中提供了细粒度和区分特征的指导。 另一方面,它从红外模式提供全球行人统计数据。 MS和MC极大地提高了网络跨模态表示身份的能力。 此外,我们提出了级联聚合策略(CA)来优化特征嵌入的分布。 它逐步地将样本聚合到子类、类内和身份间。 通过级联的方式,将属于相同身份的实例倾向于聚合,将属于不同身份的实例映射为分散。
贡献
为了获取更有鉴别性的语义,它通过不同的语义和可见光和红外模式的特定优势来学习增强的特征表示提出了一个新的VI-Reid级联聚合的模态协同互补学习网络(MSCLNet)框架。
1、 提出了一个模态协同模块(MS)和一个模态补充模块(MC),该模块创新性地挖掘了模态特有的多样性语义,并通过两个并行的模态特有优势准则进一步增强了特征表示。 它们为进一步的高级身份表示提供了参考。
2、设计了一种级联聚合策略(CA)来优化特征嵌入在细粒度级别上的分布。 它以级联的方式逐步聚合总体实例,并增强身份的区分。
MSCLNet
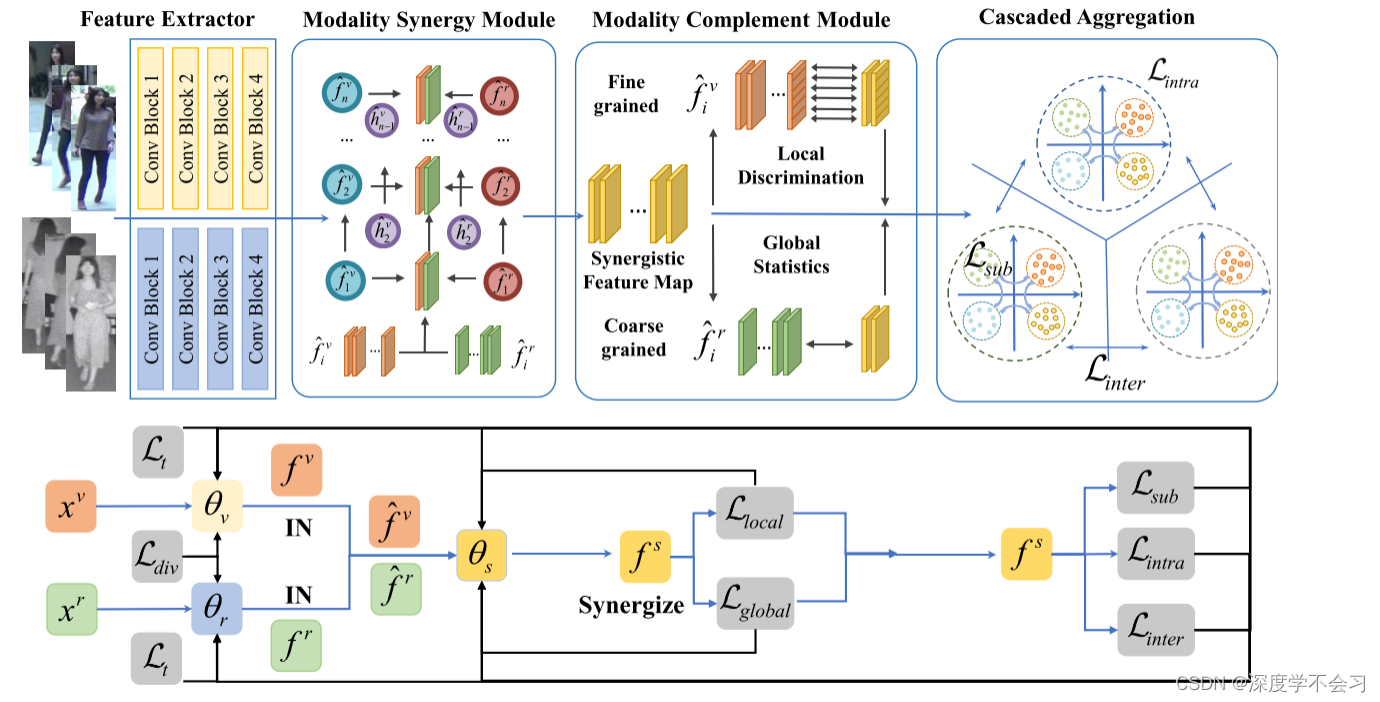
采用双流网络作为特征提取器。 首先,基于从可见光和图像中提取的特征表示FV和FR,MSCLNET通过约束两种模式之间特征分布的多样性来构造协同表示FS。 模式补充指导将进一步加强协同作用。 可见模态提供细粒度的鉴别语义,而红外模态提供稳定的全局行人统计。 然后通过级联聚合策略对同一类特征嵌入进行聚合,从三个方面逐步优化特征嵌入的综合分布。
方法
模态协同模块
双流网络提取它们的特征fv i和fr i特性fv i和fr i通过以下操作进行规范化。

![]()
Var [fv i ]表示在小批处理中为每个实例分别按维度计算。设S(·)表示模态协同模块,在fv i,fr i的基础上构造带有标签YI的协同特征fs i:
![]()
其中θs作为模态协同模块S(·)的参数。利用Mogrifier LSTM[25]作为协同特征编码器来最大限度地提高模态协同学习的效果,并将协同特征fs i与可见光和红外特征及其共享的地面真值标记编码。 为了构造具有不同语义的fs i,我们利用KL-散度来约束可见光和红外特征fv i,fr i的Logistic分布,其表述如下:

其中n表示一批样品的数量。 θv和θr分别作为可见光和红外模态的学习特征提取器,旨在最大限度地提高模态语义表示的多样性。 首先在表示空间中设计fv和fr,以最大限度地提高身份之间的模态区分度。 然后,协同特征提取器θs投影f v ,f r 构建了一个共享的表示空间,并构造了协同特征fs i.
在此基础上,引入交叉熵来约束可见光和红外特征PV I和PR I的逻辑概率,并引入地面真值标记YI来约束不同的语义

其中λdiv和λt是用于平衡单个损失项贡献的参数, θv和θr的优化过程分别跟踪(fv xv,fs xv)和(fr xr,fr xr)的梯度。
模态补充模块
考虑到细粒度语义,我们利用可见特征fv i在局部方面的优势来增强协同特征。 在考虑粗粒度语义的基础上,结合全局部分红外特征的优点,增强了协同特征。
在细粒度层次上,我们将可见特征和协同特征分成n=6个部分,即MPANET[45],得到单独的特征块fv i=[BV1,BV2···,BV n],fs =[BS i1,BS2···,BS n]。 协同特征的局部区分可以通过可见模态的细微区域来增强。 利用余弦相似度COS(·,·)进行优化

同时,在粗粒度层次上,通过保持协同特征的统计中心与红外特征fr i的统计中心一致来监督fs i。 协同特征的全局统计量可以通过红外模态的中心一致性得到优化。

其中Cs yi,Cr yi表示协同特征fs i,fr i的yi类的中心。 LGlobal有助于协调协同和红外特征的语义,并过滤协同表示的身份无关性。
在模态补码模块中,我们更新了协同特征提取器θs的参数,旨在为每个身份构造噪声更小、更多样、语义描述更精确的特征。 θs优化如下:
![]()
级联聚合策略
在Reid问题中广泛采用中心损失[23]和三重损失[14]来同时学习特征嵌入的集中表示和挖掘硬样本。 中心损耗LC和三重损耗LTRI可表述为:

子类级聚合
利用每个图像的拍摄摄像机的同一性作为自然子类,因为同一摄像机拍摄的同一个人的图像彼此具有很高的相似性,其中Csi表示Sth I子类中心:

类内聚合
在训练过程中保持特征的结构先验。 聚合的公式可以表示如下,其中ns表示每个标识的子类的数目。

类间级上的聚合
本文提出的聚合方法不仅使类内实例的相似度最大化,而且使类间实例的相异度最大化。

度量学习CA的损失函数可以表示为:

目标函数
首先,我们利用协同损失LSynergy来丰富对不同语义的表示。 特征提取器θv和θr的参数更新为
![]()
在此基础上,利用可见光特征中的局部识别性和红外特征中的全局身份统计性两种方法的优点,对协同特征表示进行了改进。 我们利用互补损耗LCOM来更新模态协同特征提取器θs:
![]()
















 6403
6403











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









