






目录
摘要
提出了一种非线性中间模态生成器(MMG),它有助于减少模态差异。MMG 可以有效地将 VIS 和 IR 图像投影到统一的中间模态图像 (UMMI) 空间中,以生成中间模态 (M-modality) 图像。生成的 M 模态图像和原始图像被馈送到主干网络以减少模态差异。为了将 UMMI 空间中从 VIS 和 IR 图像生成的两种类型的 M 模态图像拉在一起,提出了一个分布一致性损失 (DCL),以使生成的 M 模态图像的模态分布一致尽可能。最后提出了一个中间模态网络(MMN),以显式方式进一步增强特征的区分度和丰富度。
主要贡献
(1)提出了一种非线性中间模态生成器来生成中间模态图像来辅助 VI-ReID 任务。特别是,所提出的中间模态生成器可以有效地将 VIS 和 IR 图像投影到统一的中间模态图像空间中。
(2) 我们提出了一种有效的分布一致性损失,使从VIS和IR图像中获得的两种中间模态图像在UMMI空间中的模态分布一致,进一步提高了所提出方法的性能。
(3) 大量实验表明,所提出的方法在 SYSUMM01 和 RegDB 数据集上都显着优于其他竞争方法。
 方法
方法
中间模态生成器(MMG),分布一致性损失(DCL
Middle Modality Generator

在通道级别对齐可见光图像和红外图像。将可见光转换为红外比将红外转换为可见光更容易。分别对这两种模式进行编码,对于VIS模式
![]()
对于IR模式
![]()
通过如上图所示操作,我们获得了可见光和红外图像的特征,并在通道级别执行了可见光图像和红外图像之间的对齐。
Modality Information Decoder
提出的MID用于将编码为一个通道的数据投影到统一的三通道图像空间。在这个统一的图像空间中,可见光和红外图像之间的距离变得更近,可以减少模态差异。
MID包括通道级的1×3全连接层,然后是ReLU激活层,以获得三通道中间模态图像. ReLU激活层用于进一步增加非线性关系。通过上述操作,我们可以生成M-模态图像。生成的M-模态图像与VIS图像和IR图像具有相同的标签。最后,将M-模态、VIS和IR模态图像一起送入主干网络
Distribution Consistency Loss (DCL)
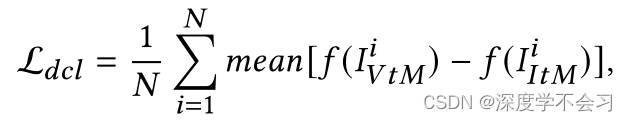
N是图片数量,f()是网络的输出,mean[A-B]是是A和B之差的平均运算,DCL的优化将使两种M-模态特征相似。
损失函数
![]()
![]()
结果
















 299
299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









