







1. 内容来源
 https://www.bilibili.com/video/BV16g411L7FG?p=1&vd_source=f94822d3eca79b8e245bb58bbced6b77
https://www.bilibili.com/video/BV16g411L7FG?p=1&vd_source=f94822d3eca79b8e245bb58bbced6b772. Pytorch实现
2.1 Encoder实现
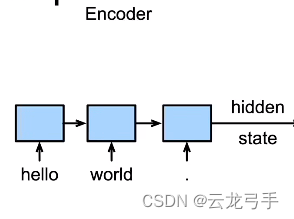
上图为seq2seq模型中的Encoder结构,其中使用一个RNN,输入为源语言的句子,输出是隐藏层状态(作为整个句子的特征表示)
在代码实现中,Encoder类:
类内定义
- embedding层:将输入句子中每个字符转化成embedding表示,类似onehot操作
- RNN层(输入维度:词向量长度)
forward
- 将输入的X经过embedding层得到(批量大小,时间步,词向量长度)的张量表示
- 将批量大小和时间步互换,方便后续for loop
- 输入RNN得到输出(时间步,批量,隐藏层单元个数)和所有隐藏层的状态(层数,批量大小,隐藏层单元个数)
代码实现:
import collections
import math
import torch
from torch import nn
from d2l import torch as d2l
class Seq2SeqEncoder(d2l.Encoder):
def __init__(self,vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size, num_hiddens, num_layers, dropout=dropout)
def forward(self, X, *args):
X = self.embedding(X)
X = X.permute(1, 0, 2)
output, state = self.rnn(X)
return output, state2.2 Decoder实现
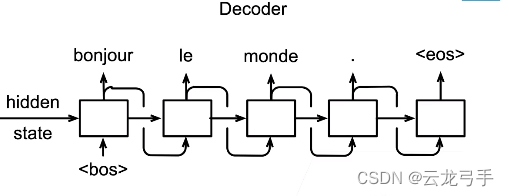
解码器以编码器最后一层最后时刻的状态拼接输入(<bos>)作为输入,每次输出一个字符,将输出再加入输入,循环输出,直到输出<eos>
在代码实现中,Decoder类:
类内定义
- embedding层:由于与Encoder语言不一致,embedding不互通
- RNN层(输入维度:源语言词向量长度+Encoder隐藏层单元数)
- Dense层(隐藏层单元数->目标语言词向量长度)
init_state(用于预测阶段)
- 接受Encoder的输出和隐藏层状态
- 返回隐藏层状态
forward
- 将输入的X经过embedding层得到(时间步,批量大小,词向量长度)的张量表示
- 将Encoder最后一层最后时刻的隐藏层状态广播成X的形状,作为原文的特征表示context
- 将context和X进行拼接(在词向量长度维度)
- 输入RNN得到输出和隐藏层的状态
- 将RNN的输出经过Dense层得到词向量表示(将时间步和批量大小维度交换)
代码实现:
class Seq2SeqDecoder(d2l.Decoder):
def __init__(self, vocab_size, embed_size,num_hiddens, num_layers, dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size+num_hiddens, num_hiddens, num_layers, dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, *args):
enc_output, enc_state = enc_outputs
return enc_state
def forward(self, X, state):
X = self.embedding(X).permute(1, 0, 2)
# 将encoder的state广播成与X相同的形状进行拼接
context = state[-1].repeat(X.shape[0], 1, 1)
X_and_context = torch.cat((X, context), 2)
output, state = self.rnn(X_and_context, state)
output = self.dense(output).permute(1, 0, 2)
return output, state2.3 带遮罩的交叉熵实现
需要将正常交叉熵函数加上遮罩是因为当译文字符数小于时间步总数,需要填充空白<pad>,但是预测译文不需要产生相应的<pad>,在计算loss时需要将填充的部分遮住以避免不必要loss累加。
填充/裁剪实现:
def truncate_pad(line, num_steps, padding_token):
"""Truncate or pad sequences.
Defined in :numref:`sec_machine_translation`"""
if len(line) > num_steps:
return line[:num_steps] # Truncate
return line + [padding_token] * (num_steps - len(line)) # Pad遮罩矩阵在代码中就是先按照输入产生对应的下标矩阵,将下标与有效词数比较,得到布尔矩阵(小于的为True,大于等于的为False),将布尔矩阵求反,True对应的值替换成‘none’即可。
代码实现:
def sequence_mask(X, valid_len, value=0):
maxlen = X.size(1)
mask = torch.arange((maxlen), dtype=torch.float32,
device=X.device)[None, :] < valid_len[:, None]
X[~mask] = value
return XMaskedSoftmaxECLoss类定义:
forward
- 按照label(正确译文)形状构建全1矩阵
- 调用sequence_mask将填充的元素位置置为‘none’
- 调用原始CrossEntropyLoss中的loss计算
- 对每个句子的loss向量求均值并返回
代码实现:
class MaskedSoftmaxECLoss(nn.CrossEntropyLoss):
def forward(self, pred, label, valid_len):
weights = torch.ones_like(label)
weights = sequence_mask(weights, valid_len)
self.reduction = 'none'
unweighted_loss = super().forward(pred.permute(0, 2, 1), label)
weighted_loss = (unweighted_loss * weights).mean(dim=1)
return weighted_loss2.4 模型训练实现
训练过程中:
Encoder
- 输入:原文
- 输出:隐藏层状态
- 隐藏层状态:随机初始化
Decoder
- 输入:<bos>-译文
- 输出:译文
- 隐藏层状态:随机初始化
代码实现:
def train_Seq2Seq(net, data_iter, lr, num_epochs, tgt_vocab, device):
# 封装不同层的初始化函数
def xavier_init_weights(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
if type(m) == nn.GRU:
for param in m._flat_weights_names:
if 'weight' in param:
nn.init.xavier_uniform_(m._parameters[param])
# 网络初始化
net.apply(xavier_init_weights)
net.to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
loss = MaskedSoftmaxECLoss()
net.train()
animator = d2l.Animator(xlabel='epoch', ylabel='loss',
xlim=[10, num_epochs])
# 训练
for epoch in range(num_epochs):
timer = d2l.Timer()
metric = d2l.Accumulator(2)
for batch in data_iter:
# 获取原文,原文有效长度,译文,译文有效长度
X, X_valid_len, Y, Y_valid_len = [x.to(device) for x in batch]
# 在译文头部加入<bos>,让模型学习<bos>代表开始翻译
bos = torch.tensor([tgt_vocab['<bos>']] * Y.shape[0],
device=device).reshape(-1, 1)
dec_input = torch.cat([bos, Y[:, :-1]], 1)
# 前向计算得到预测译文
Y_hat, _ = net(X, dec_input, X_valid_len)
# 计算遮罩后的损失
l = loss(Y_hat, Y, Y_valid_len)
# 梯度下降优化
l.sum().backward()
d2l.grad_clipping(net, 1)
num_tokens = Y_valid_len.sum()
optimizer.step()
with torch.no_grad():
metric.add(l.sum(), num_tokens)
if (epoch + 1) % 10 == 0:
animator.add(epoch + 1, (metric[0] / metric[1],))
print(f'loss {metric[0] / metric[1]:.3f}, {metric[1] / timer.stop():.1f} '
f'tokens/sec on {str(device)}')
训练代码:
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 300, d2l.try_gpu()
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = Seq2SeqEncoder(len(src_vocab), embed_size, num_hiddens, num_layers,
dropout)
decoder = Seq2SeqDecoder(len(tgt_vocab), embed_size, num_hiddens, num_layers,
dropout)
net = d2l.EncoderDecoder(encoder, decoder)
train_Seq2Seq(net, train_iter, lr, num_epochs, tgt_vocab, device)结果:

loss 0.020, 15977.5 tokens/sec on cuda:02.5 模型预测实现
预测过程中:
Encoder
- 输入:原文-<eos>
- 输出:隐藏层状态
- 隐藏层状态:随机初始化
Decoder
- 首时间步输入:<bos>
- 循环输入:上一个时间步的Decoder输出
- 输出:译文
- 首时间步隐藏层状态:Encoder的隐藏层覆盖(两者形状一致)
- 循环隐藏层状态:上一个时间步的Decoder状态
代码实现:
def predict_seq2seq(net, src_sentence, src_vocab, tgt_vocab, num_steps,
device, save_attention_weights=False):
# 关闭模型中Dropout
net.eval()
# 原文后拼接<eos>,与训练样本保持一致
src_tokens = src_vocab[src_sentence.lower().split(' ')] + [
src_vocab['<eos>']]
# 将原文长度调整至时间步长
enc_valid_len = torch.tensor([len(src_tokens)], device=device)
src_tokens = d2l.truncate_pad(src_tokens, num_steps, src_vocab['<pad>'])
# 增加‘批量’维度
enc_X = torch.unsqueeze(
torch.tensor(src_tokens, dtype=torch.long, device=device), dim=0)
# 得到Encoder的输出以及隐藏层状态
enc_outputs = net.encoder(enc_X, enc_valid_len)
# 利用Encoder最后一层隐藏层的最后时刻状态初始化Decoder的隐藏层状态
dec_state = net.decoder.init_state(enc_outputs, enc_valid_len)
# 将<bos>作为Decoder输入
dec_X = torch.unsqueeze(torch.tensor(
[tgt_vocab['<bos>']], dtype=torch.long, device=device), dim=0)
output_seq, attention_weight_seq = [], []
# 开始循环输出预测译文
for _ in range(num_steps):
# 得到Decoder输出和隐藏层状态
Y, dec_state = net.decoder(dec_X, dec_state)
# 将输出的词向量转化成译文,并作为下一个时间步的Decoder输入
dec_X = Y.argmax(dim=2)
pred = dec_X.squeeze(dim=0).type(torch.int32).item()
# 下一章内容
if save_attention_weights:
attention_weight_seq.append(net.decoder.attention_weights)
# 若输出<eos>,说明译文结束
if pred == tgt_vocab['<eos>']:
break
# 译文拼接
output_seq.append(pred)
return ' '.join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq测试代码:
engs = ['go .', 'i lost .', 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation, attention_weight_seq = predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device
)
print(f'{eng} => {translation}, bleu {bleu(translation, fra, k=2)}')结果:
go . => va !, bleu 1.0
i lost . => j'ai perdu ., bleu 1.0
he's calm . => il <unk> tomber ., bleu 0.0
i'm home . => je suis chez vous retard retard ?, bleu 0.49742922074672763其中,bleu是NLP常用评价函数,会比对连续N个词的命中率,源码:
def bleu(pred_seq, label_seq, k):
pred_tokens, label_tokens = pred_seq.split(' '), label_seq.split(' ')
len_pred, len_label = len(pred_tokens), len(label_tokens)
score = math.exp(min(0, 1 - len_label / len_pred))
for n in range(1, k + 1):
num_matches, label_subs = 0, collections.defaultdict(int)
for i in range(len_label - n + 1):
label_subs[' '.join(label_tokens[i: i + n])] += 1
for i in range(len_pred - n + 1):
if label_subs[' '.join(pred_tokens[i: i + n])] > 0:
num_matches += 1
label_subs[' '.join(pred_tokens[i: i + n])] -= 1
score *= math.pow(num_matches / (len_pred - n + 1), math.pow(0.5, n))
return score















 850
850











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











