







看这玩意儿,解决了高数没曾理解的一些东西的概念。数学不好,算法难搞???
一个算法的实现,离不开数学的支撑。
本文参考:https://www.jianshu.com/p/c7e642877b0e
(形象,清楚)
本文讲解内容:
- 1.导数 偏导数,方向导数,梯度的数学概念
- 2.梯度下降法思维原理。
- 3.运用梯度下降法,拟合直线实例
数学:
那么首先引入高数一些东西的概念:
1.导数:
- 是描述函数在某一点的变化率的
2.偏导数:
- 描述函数在某点在坐标轴的正方向的变化率的。
- 导数与偏导数区别:导数用于一元函数中,偏导数用于多元函数。
- 导数与偏导数关系:偏导数也是导数。导数囊括了:偏导数,方向导数。
3.方向导数与偏导数:
- 方向导数:也是导数,其意义是描述函数在某点任意方向变化率。
- 方向导数与偏导数区别:偏导数仅仅描述坐标轴的正方向,而方向导数描述任意方向。
- 可以理解:偏导数是方向导数的一种,他是含于方向导数。
4.导数的意义:
- 函数图像中,函数图像在某点的切线的斜率。
5.微分的概念及意义:
- 概念:表示如:z=f(x,y)函数对x,y都要进行求导。 说白了就是求导。
- 意义:
函数的变化率。(因为微分是对函数中的自变量,都进行求导,所以像是结合,对应的就是函数变化率)
6.梯度的概念 :
-
问题:函数在空间的某一点上,沿着这个点的哪个方向,函数具有最大的变化率?
为了解决这个问题,引入了梯度。 -
梯度是向量,具有方向。 梯度表示了函数往这个方向有最大变化率,他的方向就是函数变化最快的方向。
他的方向就是最大方向导数的方向, 梯度的值,就是最大方向导数的值。 -
百度百科给出:梯度的本意是一个向量(矢量),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)。
7.梯度下降法
维基百科给出:
- 梯度下降法(英语:Gradient descent)是一个一阶最优化算法,通常也称为最速下法。
要使用梯度下降法找到一个函数的局部极小值,必须向函数上当前点对应梯度(或者是近似梯度)的反方向的规定步长距离点进行迭代搜索。如果相反地向梯度正方向迭代进行搜索,则会接近函数的局部极大值点;这个过程则被称为梯度上升法。 - 梯度下降方法基于以下的观察:如果实值函数 F(x)在a处可微且有定义,那么F(x)函数在a点沿着梯度方向的负方向—△ F(a)下降最快。(ps:△F(a)为梯度函数,—△F(a)为负方向的梯度函数,即梯度下降最快的方向。)
- 梯度下降计算方法:如果 b=a-α△F(x),那么F(b)<F(a)
- 通俗的讲:梯度下降是一个最优化算法,他就是沿着梯度下降的方向来求出一个函数的极小值
数学中梯度的下降计算实例
1.单变量函数梯度下降:
引入一个单变量的函数:
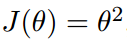
函数的微分:
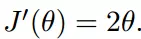
初始化,开始的起点:
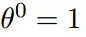
学习率(步长):控制每次行走的步伐的长度,因为梯度是一个基数,通过前面加一个常量,来控制每次行走的长度。
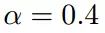
计算梯度下降(这里迭代四次):
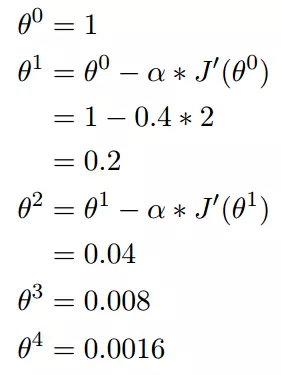
2.多变量函数的梯度下降计算实例
引入一个二元函数:
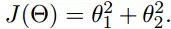
我们初始起点:

学习率:
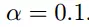
这个二元函数的梯度,
(不要惊讶哦,梯度就是对每个自变量都求导数,这里是向量表示出来的哦)
(原函数恐怕你忘记了吧??,请往上翻)

迭代计算梯度:

以上就都是数学方面的内容啦
#分割线#分割线#分割线#分割线#分割线#分割线#分割线#分割线#分割线#分割线#分割线#分
python
梯度下降算法的实现–线性回归的应用
------目标:用梯度算法实现 拟合这条直线。

分析:
.回顾一下,梯度下降算法,一个最优算法。为什么拟合这条直线和这个相关?
因为,我们要找出的这条直线,一定是要这些点离这条直线的平均距离最小。
也就是运用梯度下降法,求出这个能表示 每个点到目标函数的距离的 函数(代价函数)的最小值,值越小,说明拟合程度越高。当然最小值是0.此时距离最近,拟合程度越高。就是最贴近的直线。
首先给出代价函数(每个点到这条直线的距离的函数):
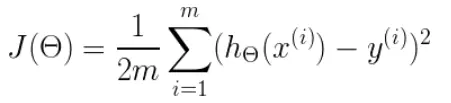
参数解释:
- m表示点的个数,要把每个点到目标直线的距离都要求出来。
- h(θ)这个是预测函数,我们最终要求的那个直线的函数。
- y表示每个点的y坐标值。
这是线性回归,看图预测,我们要求的函数形式为:h(θ)=θ0+θ1(x) 也就是 y=b+ax
步骤:
1.求出代价函数的偏导。算出最小距离,距离越小,那么拟合程度越高。
2.梯度下降计算出θ0和θ1 。
梯度下降计算公式:θ1=θ0-α△J(θ)
代码实现:
"""
一.说明一些概念的理解:
1.导数:
是描述函数在某一点的变化率的。
2.偏导数:
描述函数在某点在坐标轴的正方向的变化率的。
导数与偏导数区别:导数用于一元函数中,偏导数用于多元函数。
导数与偏导数关系:偏导数也是导数。导数囊括了:偏导数,方向导数。
3.方向导数与偏导数:
方向导数:也是导数,其意义是描述函数在某点任意方向变化率。
方向导数与偏导数区别:偏导数仅仅描述坐标轴的正方向,而方向导数描述任意方向。
可以理解:偏导数是方向导数的一种,他是含于方向导数。
4.导数的意义:
函数图像中,函数图像在某点的切线的斜率。
5.微分的概念及意义:
概念:表示如:z=f(x,y)函数对x,y都要进行求导。 说白了就是求导。
意义:
函数的变化率。(因为微分是对函数中的自变量,都进行求导,所以像是结合,对应的就是函数变化率)
1.梯度的概念 :
问题:函数在空间的某一点上,沿着这个点的哪个方向,函数具有最大的变化率?
为了解决这个问题,引入了梯度。
梯度是向量,具有方向。
梯度表示了函数往这个方向有最大变化率,他的方向就是函数变化最快的方向。
就是他的方向就是最大方向导数的方向,
梯度的值,就是最大方向导数的值。
二。数学知识:
计算两点之间的距离
"""
#这是出发起点
theta = [0,0,] # [b,a] y=b+ax
#所有的点,用向量表示,二维数据
data=[
[1,1],
[2,2],
[3,3],
[4,4]
]
m = len(data)
#学习率,就是控制步伐的,以免错过最佳点。
alpha = 0.001
#梯度下降 迭代次数
iterm = 50000
def cost(theta,data):
#总的距离
sum = 0
#迭代data中的每一个点,计算出起点到每个点之间的距离。
for i in data:
#梯度函数,来求距离的最小值。
sum += (theta[0]+theta[1]*i[0]-i[1])**2
print(sum)
def gd(theta,data,alpha,iterm):
for _ in range(iterm):
cost(theta,data)
temp_theta = theta
for i in data:
#梯度下降的计算,得到新的点。
temp_theta[0] = theta[0]- ((theta[0]+theta[1]*i[0]-i[1])*alpha/m)
temp_theta[1] = theta[1] - ((theta[0]+theta[1]*i[0]-i[1])*i[0]*alpha/m)
#沿着梯度反向,得到新的点。
theta = temp_theta
print(theta)
if __name__ == "__main__":
gd(theta,data,alpha,iterm)














 13万+
13万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









