







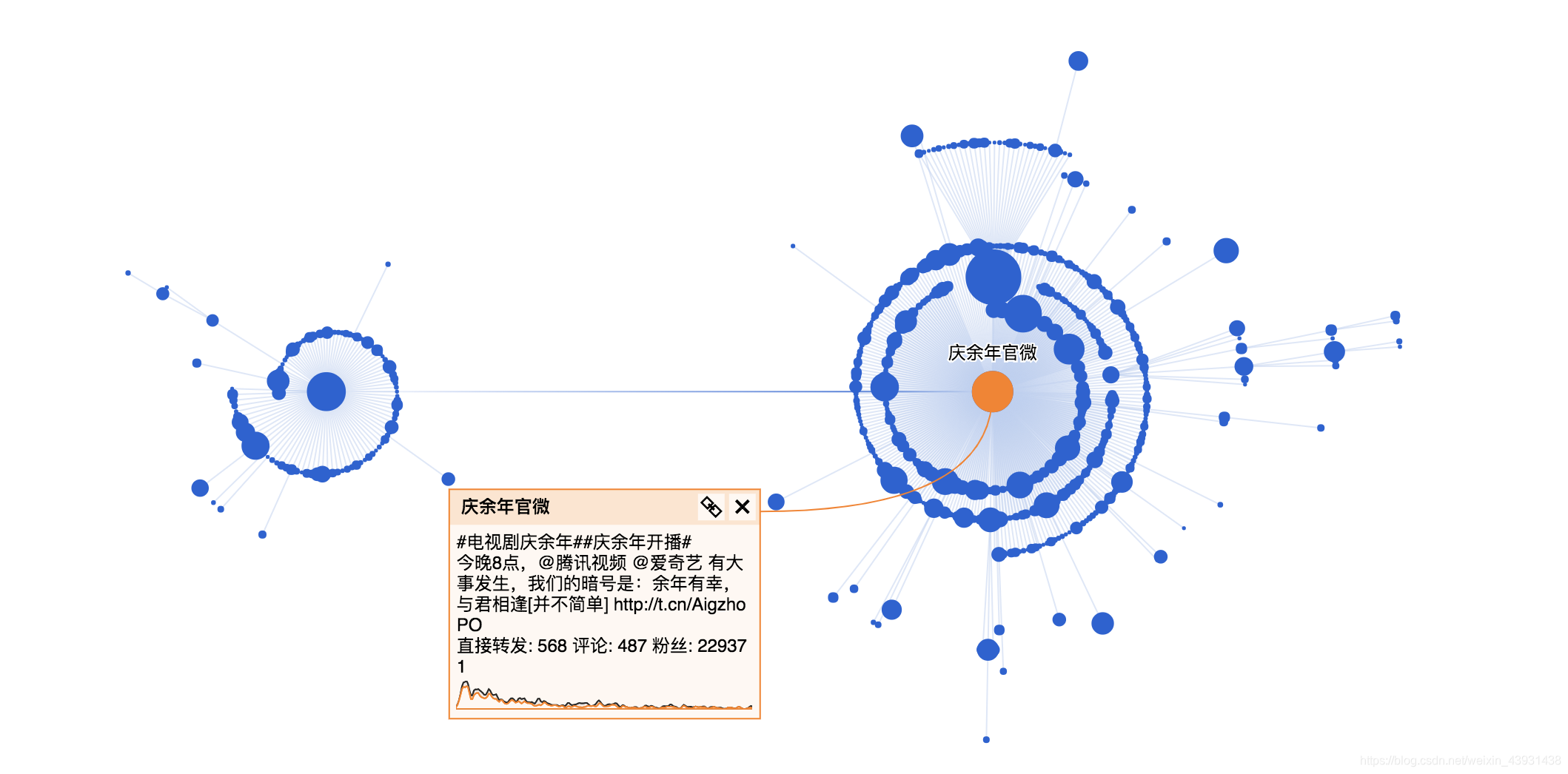
 本文利用Python分析《庆余年》在微博的传播路径,包括微博评论词云展示,发现情绪正向,传播广泛,主要由肖战等主演带动。同时,构建原著人物关系图谱,通过Gephi进行展示,主角范闲影响力突出。
本文利用Python分析《庆余年》在微博的传播路径,包括微博评论词云展示,发现情绪正向,传播广泛,主要由肖战等主演带动。同时,构建原著人物关系图谱,通过Gephi进行展示,主角范闲影响力突出。
利用Python分析《庆余年》人物图谱和微博传播路径
庆余年电视剧终于在前两天上了,这两天赶紧爬取微博数据看一下它的表现。
庆余年
《庆余年》是作家猫腻的小说。这部从2007年就开更的作品拥有固定的书迷群体,也在文学IP价值榜上有名。

期待已久的影视版的《庆余年》终于播出了,一直很担心它会走一遍《盗墓笔记》的老路。
在《庆余年》电视剧上线后,就第一时间去看了,真香。

庆余年微博传播分析
《庆余年》在微博上一直霸占热搜榜,去微博看一下大家都在讨论啥:
一条条看显然不符合数据分析师身份。
于是爬取了微博超话页面,然后找到相关人员,分别去爬取相关人员的微博评论,看看大家都在讨论啥。
import re
import time
import copy
import pickle
import requests
import argparse
'''微博爬虫类'''
class weibo():
def __init__(self, **kwargs):
self.login_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36',
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Connection': 'keep-alive',
'Origin': 'https://passport.weibo.cn',
'Referer': 'https://passport.weibo.cn/signin/login?entry=mweibo&r=https%3A%2F%2Fweibo.cn%2F&backTitle=%CE%A2%B2%A9&vt='
}
self.login_url = 'https://passport.weibo.cn/sso/login'
self.home_url = 'https://weibo.com/'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36',
}
self.session = requests.Session()
self.time_interval = 1.5
'''获取评论数据'''
def getComments(self, url, url_type='pc', max_page='all', savename=None, is_print=True, **kwargs):
# 判断max_page参数是否正确
if not isinstance(max_page, int):
if max_page != 'all':
raise ValueError('[max_page] error, weibo.getComments -> [max_page] should be <number(int) larger than 0> or <all>')
else:
if max_page < 1:
raise ValueError('[max_page] error, weibo.getComments -> [max_page] should be <number(int) larger than 0> or <all>')
# 判断链接类型
if url_type == 'phone':
mid = url.split('/')[-1]
elif url_type == 'pc':
mid = self.__getMid(url)
else:
raise ValueError('[url_type] error, weibo.getComments -> [url_type] should be <pc> or <phone>')
# 数据爬取
headers = copy 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 836
836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









