







多模态|增强多模式学习:元学习跨模式知识提炼以处理缺失模式|Enhancing Multi-modal Learning: Meta-learned Cross-modal Knowledge Distillation for Handling Missing Modalities
原文链接:http://arxiv.org/abs/2405.07155
文章目录
摘要
缺少重要模态 / 元学习 / 知识蒸馏 / 自适应估计模态权重 /
在多模态学习中,某些模态比其他模态更具影响力,它们的缺失可能会对分类/分割准确性产生显著影响。
因此,一个重要的研究问题是,即使在输入数据中缺少重要的模态,训练好的多模态模型是否可能具有高准确性。
本文提出了一种称为元学习跨模态知识蒸馏(MCKD)的新方法来解决这个研究问题。
MCKD通过元学习过程自适应地估计每个模态的重要性权重。这些动态学习的模态重要性权重在成对的跨模态知识蒸馏过程中使用,以将来自具有较高重要性权重的模态的知识转移到具有较低重要性权重的模态。
在跨模态知识蒸馏过程中,动态学习的模态重要性权重被用来对模态之间的知识进行转移。这些权重确定了每个模态对于任务的重要性,而在知识蒸馏中,来自被认为更为重要的模态的知识被转移到被认为较不重要的模态上。
这种跨模态知识蒸馏即使在缺少重要模态的情况下也能产生高度准确的模型。
与领域中先前的方法不同,我们的方法设计为在多个任务(例如,分割和分类)中以最小的调整即可工作。
对Brain tumor Segmentation Dataset 2018(BraTS2018)和Audiovision-MNIST分类数据集的实验结果显示了MCKD相对于当前最先进模型的优越性。特别是在BraTS2018中,我们在平均分割Dice分数方面取得了显著的改进,分别为增强肿瘤3.51%,肿瘤核心2.19%,整个肿瘤1.14%。
一、模态缺失的相关工作
为了解决多模态学习中缺失模态的问题,已经开发了各种方法[19–21, 24]。
1. 特征嵌入
在MIA中,开发了HeMIS模型[14]来学习模态特定的嵌入,允许对这些嵌入进行算术运算(例如,均值和方差),以产生分割结果。
"学习模态特定的嵌入"指的是在多模态学习中,为每个模态(例如图像、文本、音频等)学习特定的表示形式或嵌入空间。这意味着对于每个输入模态,系统会学习一个独特的特征表示,使得该模态的信息能够被有效地表达和处理。这些特定的嵌入通常由神经网络模型学习而来,经过训练后,它们可以捕获每个模态的重要特征,并将其转换为一个向量或特征表示,以便在后续的任务中进行处理和分析。
Dorent等人[10]通过多模态变分自动编码器(MVAE)扩展了HeMIS,根据均值和方差特征产生了像素级的分类。类似地,自编码器结构已经被用于无监督学习缺失模态[6, 36]。
其他几种方法[15, 34, 42]提出了从完整模态模型中学习缺失模态特征以增强嵌入的方法。
"增强嵌入"指的是在特征表示中加入额外的信息或增强其表达能力的过程。在多模态学习中,增强嵌入可能包括对特征进行一些变换、组合或增强,以提高其在任务中的性能或表达能力。这种增强可以通过各种方式实现,例如引入更多的上下文信息、使用更复杂的模型或技术、应用特定的正则化方法等。增强嵌入的目标是提升特征的表示质量,使得它们能更好地捕捉数据的特征和模式,从而提高模型的性能。
2. 特征解耦
一些论文[7, 38]提出了一种旨在学习模态共享和模态特定特征以获得更好性能的特征解耦方法。
"特征解耦"是指将特征表示中的不同方面或组件分离开来,使它们能够更清晰地表达数据中的不同属性或特征。在多模态学习中,特征解耦旨在分离出模态共享的特征和模态特定的特征,以便更好地理解不同模态之间的关系,并提高模型的性能。
具体而言,特征解耦可以通过多种方式实现,包括使用不同的特征提取器或编码器来处理不同的模态数据,引入额外的正则化项来鼓励模态之间的独立性,或者使用特定的网络结构来促进特征的分离和解耦。通过特征解耦,模型可以更好地学习到每个模态的独特特征,并将这些特征有效地整合到一个统一的表示中,从而提高模型在多模态任务中的性能。
一种视觉变换器架构[45]被引入用于多模态脑肿瘤分割,旨在将来自所有模态的特征融合成综合表示。在CV中,[44]中的模型旨在学习一个统一的子空间以处理不完整和未标记的多视角数据。
3. 迁移学习、元学习
Albanie等人[1]开发了一个跨模态转移模型来在模态之间传递知识。然而,它无法自动学习模态重要性,而且仅适用于视频语音分类。
还有其他一些试图处理缺失模态的作品[2, 9, 43, 46],但它们要么只能应用于分割任务,要么仅适用于特定类型的疾病,这不可避免地阻碍了这些模型的应用。
Ma等人[25]提出了SMIL模型,该模型采用了元学习算法来从缺失模态中重构特征。
与SMIL不同的是,我们应用元学习来训练一组模态重要性权重以进行跨模态知识蒸馏,而不是通过更新两个辅助网络来处理缺失模态。此外,我们注意到,在实践中,SMIL具有较高的内存复杂度,并且在缺失模态的情况下表现不稳定。
与2.1节介绍的多模态方法类似,现有的处理缺失模态的方法通常是针对特定任务设计的,**不能很容易地适应不同的任务,**比如分类和分割。而且,这些方法忽视了一些模态在分类或分割任务中的表现较好的事实。即使在训练或测试中缺失了这些“重要”模态,保留这些模态的性能也是值得的。
作者提出的MCKD方法旨在通过自动识别和提取具有重要影响的模态的知识,从而显著增强模型的性能,尤其是当这些重要模态在输入数据中不存在时。此外,MCKD还被设计成可以轻松适应不同的任务,比如分类或分割任务。
二、SMIL模型【基于生成 / 学习分布】
这篇文章是基于SMIL模型改进的。【Ma, M., Ren, J., Zhao, L., Tulyakov, S., Wu, C., Peng, X.: Smil: Multimodal learning with severely missing modality. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 35, pp. 2302–2310 (2021)】
1. 摘要
一种常见的多模态学习假设是训练数据的完整性,即所有训练样本中都有完整的模态。虽然已有研究致力于开发新方法来解决测试数据不完整的问题,例如测试样本中部分模态缺失,但很少有研究能够处理【训练】模态不完整的问题。如果考虑到严重缺失的情况,例如90%的训练样本可能缺失模态,问题将变得更加具有挑战性。这篇论文首次在文献中正式研究了在训练、测试或两者中模态缺失情况下的多模态学习的灵活性(训练和/或测试中的模态缺失)和效率(大多数训练数据缺失模态)。在技术上,我们提出了一种新的方法,名为SMIL,通过贝叶斯元学习来统一实现这两个目标。为了验证我们的想法,我们在三个流行的基准数据集(MM-IMDb、CMU-MOSI 和 avMNIST)上进行了一系列实验。结果证明,SMIL在现有方法和生成基线(包括自编码器和生成对抗网络)上具有最先进的性能。我们的代码可以在 https://github.com/mengmenm/SMIL 获取。
2. 多模态学习的四种配置
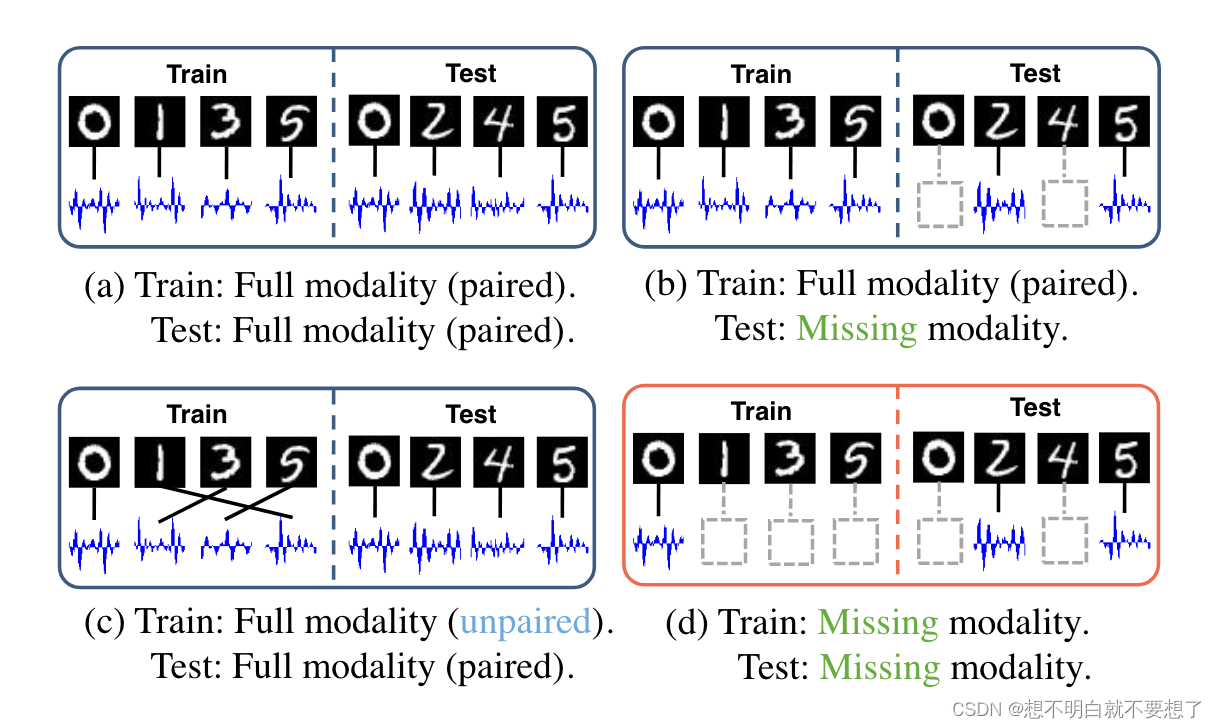
图1
(a) 训练和测试都使用完整且配对的模态(Ngiam et al. 2011);
(b) 测试时存在模态缺失(Tsai et al. 2019);
© 训练时使用不配对的模态(Shi et al. 2020);
(d) 我们研究了在训练、测试或两者中模态严重缺失的最具挑战性的配置。
3. Meta-regularization的相关工作
元学习算法专注于设计能够快速学习新知识并适应新环境的模型,且只需要少量的训练样本。
之前的方法从度量学习(Koch 2015;Vinyals et al. 2016;Sung et al. 2018;Snell, Swersky, and Zemel 2017)或概率建模(Fe-Fei et al. 2003;Lawrence and Platt 2004)的角度研究元学习。
近年来,基于优化的方法在元学习中引起了更多关注。MAML(Finn, Abbeel, and Levine 2017)是一种通用的优化算法,设计用于小样本学习和强化学习,兼容通过梯度下降学习的模型。Nichol等人(Nichol, Achiam, and Schulman 2018)进一步提高了MAML的计算效率。其他研究则将MAML应用于领域泛化(Li et al. 2018;Qiao, Zhao, and Peng 2020)和知识蒸馏(Zhao et al. 2020)。
在这项工作中,我们通过学习两个辅助网络来扩展MAML,用于缺失模态重建和特征正则化。传统的手工正则化技术(Hoerl and Kennard 1970;Tibshirani 1996)正则化模型参数以避免过拟合并增加可解释性。Balaji等人(Balaji, Sankaranarayanan, and Chellappa 2018)将正则化函数建模为通过元学习学习的附加网络,以正则化模型参数。Li等人(Li et al. 2019)遵循了(Balaji, Sankaranarayanan, and Chellappa 2018)的相同思路,但学习了一个附加网络来正则化潜在特征。Lee等人(Lee et al. 2020b)提出了一个更通用的潜在特征正则化算法。
除了扰动特征外,我们还提出学习正则化函数(遵循Lee等人 2020b),但通过正则化特征来减少重建模态和真实模态之间的差异。
总的来说,SMIL方法结合了贝叶斯元学习和优化技术,通过学习两个辅助网络实现了灵活和高效的多模态学习。这些辅助网络分别用于缺失模态的重建和特征的正则化,从而提升模型在训练和测试数据不完整情况下的表现。通过这种方式,SMIL不仅克服了传统方法在处理训练和测试数据不完整性方面的局限,还在性能上达到了新的高度。
4. Multimodal generative models 的相关工作
用于多模态学习的生成模型可分为两类:跨模态生成和联合模型生成。
跨模态生成方法:如条件变分自编码器(CVAE)(Sohn, Lee, and Yan 2015)和条件多模态自编码器(Pandey and Dukkipati 2017),学习所有模态的条件生成模型。
联合模型生成方法:学习多模态数据的联合分布。多模态变分自编码器(MVAE)(Wu and Goodman 2018)将联合后验建模为专家的乘积。多模态VAE(JMVAE)(Suzuki, Nakayama, and Matsuo 2016)使用联合编码器学习共享表示。
通过对原始算法进行少量修改,我们展示了多模态生成模型作为学习的强大基线。
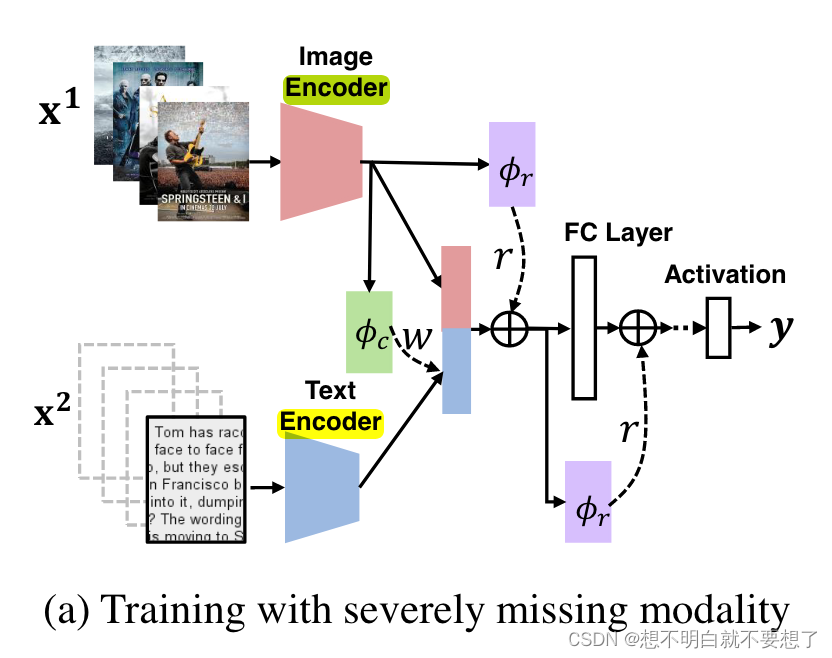
5. 模型
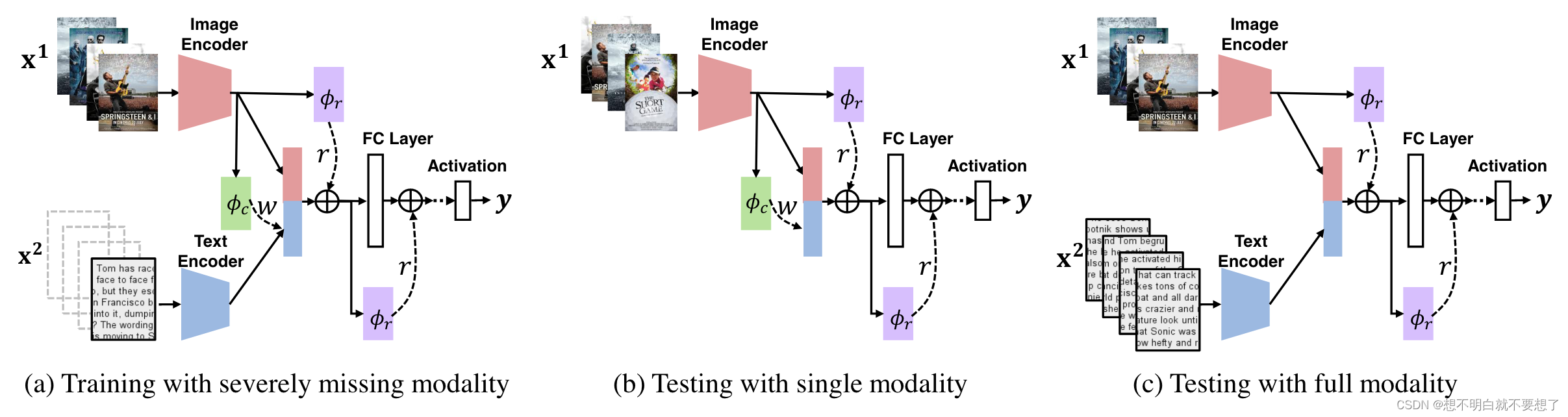
图2:
SMIL能够在模态严重缺失的情况下进行统一学习,并在测试时使用单一或完整模态。
重建网络φc:输出后验分布,从中采样权重ω,以使用模态先验重建缺失模态。
正则化网络φr:输出后验分布,从中采样正则器r,以扰动潜在特征,实现平滑嵌入。
φc和φr的协作保证了灵活和高效的学习。
这两个辅助网络分别用于缺失模态的重建和特征的正则化,从而提升了模型在训练和测试数据不完整情况下的表现。
平滑嵌入(Smooth Embedding)
通常指在数据表示空间中使相似的数据点在嵌入空间中保持相近的距离,从而实现对数据的连续和平滑的编码。在机器学习和数据挖掘领域,平滑嵌入通常用于将高维数据映射到低维表示空间,以便于可视化、降维、聚类等任务。
在深度学习中,平滑嵌入通常是通过学习数据的低维表示来实现的。例如,在自编码器和变分自编码器等模型中,通过学习编码器将输入数据映射到低维表示,同时尽可能地保持数据之间的相似性,从而实现平滑嵌入。在这种情况下,嵌入空间中的距离通常由编码器的损失函数来衡量,该损失函数通常包括重构误差和正则化项,以确保生成的嵌入是平滑的。
平滑嵌入的主要优势在于它能够将原始数据转换为更加紧凑和连续的表示形式,从而方便进行后续的数据分析和处理。此外,平滑嵌入还可以帮助发现数据中的潜在结构和模式,从而为进一步的数据挖掘和分析提供有益的线索。
5.1 缺失模态重建 φc
我们引入特征重建网络φc来近似缺失的模态。对于一个模态不完整的样本,缺失的模态是基于现有模态进行重建的。给定观察到的模态 x 1 x_1 x1,为了获得缺失模态的重建 x ^ 2 \hat{x}_2 x^2,我们为重建网络优化以下目标:
ϕ c ∗ = arg min ϕ c E p ( x ^ 1 , x 2 ) ( − log p ( x ^ 2 ∣ x 1 ; ϕ c ) ) . \phi^*_c = \arg \min_{\phi_c} \mathbb{E}_{p(\hat{x}_1, x_2)}(-\log p(\hat{x}_2 \mid x_1; \phi_c)). ϕc∗=argϕcminEp(x^1,x2)(−logp(x^2∣x1;ϕc)).
然而,在模态严重缺失的情况下,从有限的模态完整样本中训练一个重建网络并不容易。受 (Kuo et al. 2019) 的启发,我们使用从模态完整数据集中学习的模态先验的加权和来近似缺失的模态。*在这种情况下,重建网络被训练来预测这些先验的权重,而不是直接生成缺失的模态。*我们通过学习一组模态先验 M M M 来实现这一点,这些先验可以使用 K-means (MacQueen 1967) 或 PCA (Pearson 1901) 在所有模态完整的样本中进行聚类。
具体来说,设 ω \omega ω 表示分配给每个模态先验的权重。我们将 ω \omega ω 建模为具有固定均值和可变方差的多变量高斯分布 N ( I , σ ) N (I, \sigma) N(I,σ)。方差由特征重建网络预测,即 σ = f ϕ c ( x 1 ) \sigma = f_{\phi_c} (x_1) σ=fϕc(x1)。给定权重 ω \omega ω,我们可以通过计算模态先验的加权和来重建缺失的模态 x ^ 2 \hat{x}_2 x^2。于是,重建的缺失模态可以表示为:
x ^ 2 = ⟨ ω , M ⟩ , 其中 ω ∼ N ( I , σ ) . \hat{x}_2 = \langle \omega, M \rangle, \quad \text{其中} \quad \omega \sim N (I, \sigma). x^2=⟨ω,M⟩,其中ω∼N(I,σ).
我们注意到,将 ω \omega ω 建模为多变量随机变量在重建过程中引入了随机性和不确定性,这在学习复杂分布时已被证明是有益的(Lee et al. 2020b)。
通过这种方法,我们可以在训练样本中严重缺失模态的情况下,有效地近似并重建缺失的模态。这种方法不仅增强了模型的灵活性,还提升了处理不完整数据的能力,从而在多模态学习中取得更优异的表现。
重建网络的任务不是直接生成缺失的模态数据,而是预测用于重建缺失模态的权重。这些权重将应用于预先学习到的模态先验,以计算出缺失的模态。具体来说,重建过程可以分为以下几步:
- 模态先验的学习:首先,从模态完整的数据集中提取模态先验。这些模态先验可以通过聚类算法(如 K-means 或 PCA)来得到,它们代表了不同模态的特征分布。
- 权重的预测:对于一个模态不完整的样本,重建网络会根据现有模态的数据预测一组权重。这些权重反映了每个模态先验在重建缺失模态中的重要程度。具体来说,对于一个给定的模态不完整的样本 x 1 x_1 x1,重建网络通过学习训练数据来预测一组权重 ω \omega ω,而不是直接由输入 x 1 x_1 x1 生成。重建网络会被训练来最小化一个损失函数,该损失函数度量重建的模态与真实模态之间的差异。通过调整网络参数,使得在训练数据上的重建误差最小化。这样,网络学习到的权重 ω \omega ω 能够最大程度地减小重建误差,使得重建的模态尽可能接近真实的缺失模态。因此,重建网络通过学习训练数据,学会了如何将给定的模态 x 1 x_1 x1 转化为一组权重 ω \omega ω,这些权重会用于加权模态先验以生成缺失的模态数据。
- 模态的重建:使用预测的权重和预先学习到的模态先验,通过加权求和的方法重建缺失的模态。
重建网络的核心工作是学习如何将现有模态的信息转化为一组权重,然后利用这些权重和模态先验来近似缺失的模态。这种方法通过利用已有的模态先验,可以在训练数据严重缺失的情况下仍然有效地进行重建。
假设我们有两个模态先验 M 1 M_1 M1 和 M 2 M_2 M2,重建网络根据现有模态 x 1 x_1 x1 预测出权重 ω 1 \omega_1 ω1 和 ω 2 \omega_2 ω2。然后,我们用这两个权重对模态先验进行加权求和,得到重建的模态 x ^ 2 \hat{x}_2 x^2:
x ^ 2 = ω 1 M 1 + ω 2 M 2 \hat{x}_2 = \omega_1 M_1 + \omega_2 M_2 x^2=ω1M1+ω2M2
这样,重建网络的任务就是预测 ω 1 \omega_1 ω1 和 ω 2 \omega_2 ω2,而不需要直接生成 x ^ 2 \hat{x}_2 x^2。
5.2 不确定性引导的特征正则化 φr【平滑嵌入】
我们提出通过特征正则化网络φr对潜在特征进行正则化。
在每一层中,正则化网络将前一层的特征作为输入,并对当前层的特征进行正则化。设
r
r
r 表示生成的正则化,
h
l
h_l
hl 为第
l
l
l 层的潜在特征。
我们不是生成确定性的正则化
r
=
f
ϕ
r
(
h
l
−
1
)
r = f_{\phi_r}(h_{l-1})
r=fϕr(hl−1),而是假设
r
r
r 符合多变量高斯分布
N
(
μ
,
σ
)
N(\mu, \sigma)
N(μ,σ),其中均值和方差通过
(
μ
,
σ
)
=
f
ϕ
r
(
h
l
−
1
)
(\mu, \sigma) = f_{\phi_r}(h_{l-1})
(μ,σ)=fϕr(hl−1) 计算。然后,我们可以通过以下方程计算正则化特征:
h
l
:
=
h
l
⊙
Softplus
(
r
)
,
其中
r
∼
N
(
μ
,
σ
)
h_l := h_l \odot \text{Softplus}(r), 其中 r \sim N(\mu, \sigma)
hl:=hl⊙Softplus(r),其中r∼N(μ,σ),其中
⊙
\odot
⊙ 是预定义的操作(加法或乘法)用于特征正则化。在我们的实验中,我们观察到直接对潜在特征应用正则化会阻止特征正则化网络的收敛。因此,我们采用 Softplus 激活函数来减弱正则化。
特征正则化网络是一个神经网络,它的作用是对潜在特征进行正则化。
**正则化是一种约束,旨在使得模型的学习过程更加稳定,防止过拟合等问题。**通过特征正则化网络对潜在特征进行正则化,意味着我们利用这个网络来调整或者限制潜在特征的表示,以使得模型更好地泛化和学习数据的共性,而不是过度拟合训练数据。
具体而言,特征正则化网络会接收上一层的特征作为输入,并对当前层的特征进行某种形式的变换,以施加一定的约束或规范化。在给定的上下文中,这种正则化可能通过调整特征的分布,或者限制特征的大小等方式来实现。这样,特征正则化网络的目标是优化特征的表示,以促进模型的学习效果。
5.3 贝叶斯元学习框架
旨在同时优化多个神经网络模型。在这个框架中,有两个关键的网络:重建网络和正则化网络。
重建网络用于生成缺失的模态,而正则化网络用于调整潜在特征以减少过拟合。
这些网络与主网络一起,在一个称为元训练的过程中,在一个模态完整的数据集上进行训练。然后,在另一个数据集上进行元测试,以评估主网络的性能。之后,通过梯度下降对所有网络的参数进行更新。
在训练过程中,目标是最小化一个经验损失函数,它衡量了模型在测试数据上的性能。这个损失函数的计算需要通过内循环步骤来更新主网络的参数,以适应于元训练数据。通过摊薄分布来近似真实的后验分布,以便优化过程更加高效。
整个框架的最终目标是最大化条件似然,但是由于后验分布的复杂性,我们无法直接求解。因此,我们通过蒙特卡洛采样来估计似然函数,并最大化一个近似下界,从而达到优化的目的。
在算法的最后,通过多次采样和梯度下降,我们得到了一个完整的训练过程,其中主网络和辅助网络(重建网络和正则化网络)的参数都得到了更新,以适应于多模态数据的学习和生成。
三、本文模型
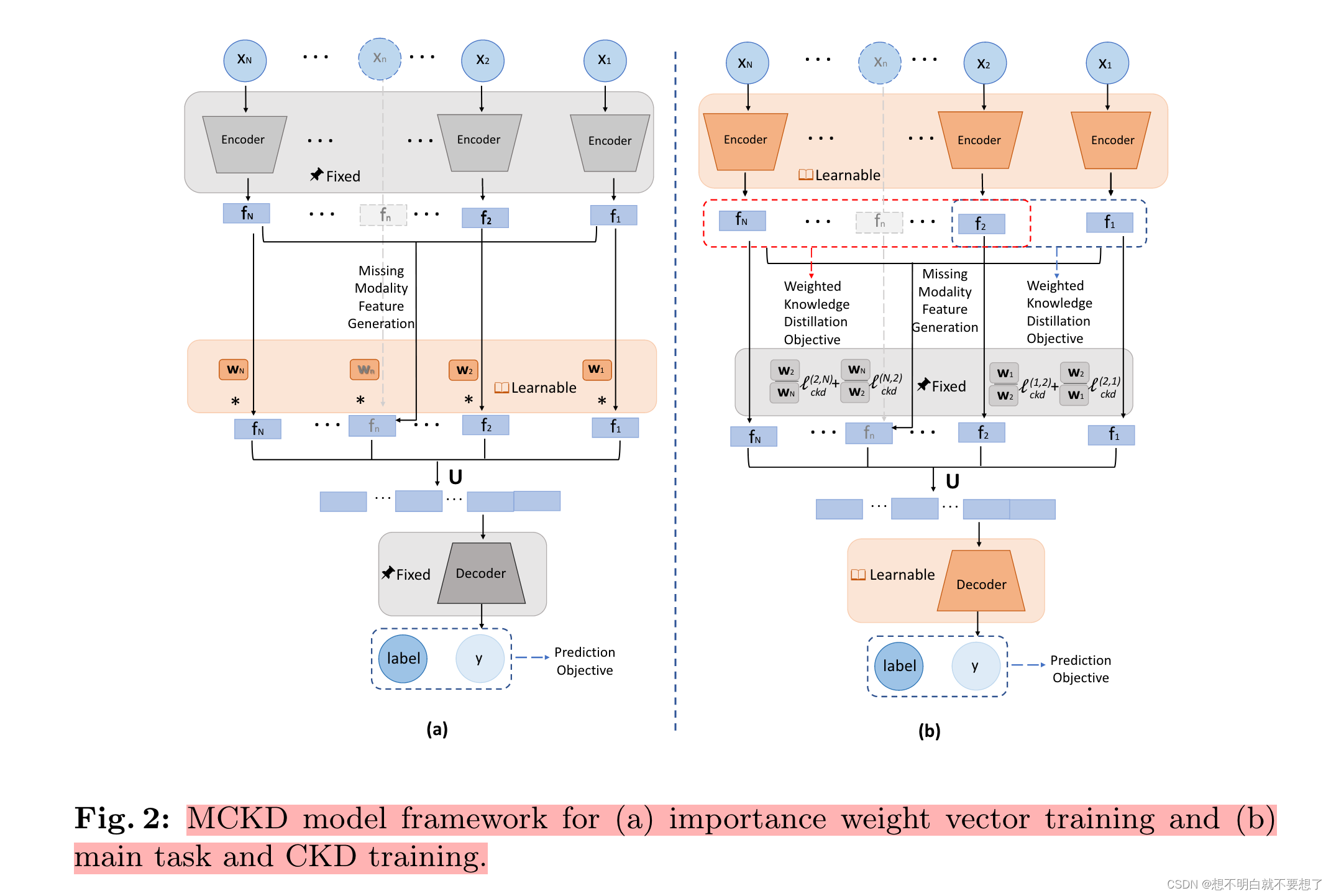
1. 模态重要性权重
我们提出的MCKD(见图2)采用了两阶段的元学习方法。首先,第一阶段用于估计在训练标签为y的任务时每种模态的重要性权重。需要注意的是,某个数据集可能包含多个子任务,比如BraTS2018数据集中的三种肿瘤分割任务。这些模态的重要性权重表示了其中包含的知识量。
接下来,第二阶段包括多个师生训练过程,同时进行主要任务优化(例如分类或分割)。对于每一对可用的模态,我们使用它们的重要性权重比例将知识从老师传递给学生。具体来说,对于每个非缺失模态xi,我们将其输入到由θi参数化的编码器中,提取出特征fi(其中fi = fθi(xi))。
为了简化模型,所有模态共享相同的编码器参数{θi}Ni=1。对于方程(1)中缺失的模态,在假设Q ⊂ M中的模态不可用时,即所有xn ∈ Q都用xn = ∅表示时,可以基于可用特征来生成缺失模态的特征。生成的特征通过方程(2)计算得出,然后与从方程(1)中提取的特征进行连接,再输入到由ζ参数化的解码器中进行预测(如方程(3)所示)。这里,ˆy表示预测结果,⊕Ni=1表示N个提取特征的连接器运算符。
2. 跨模态知识蒸馏
。。。

















 215
215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









