









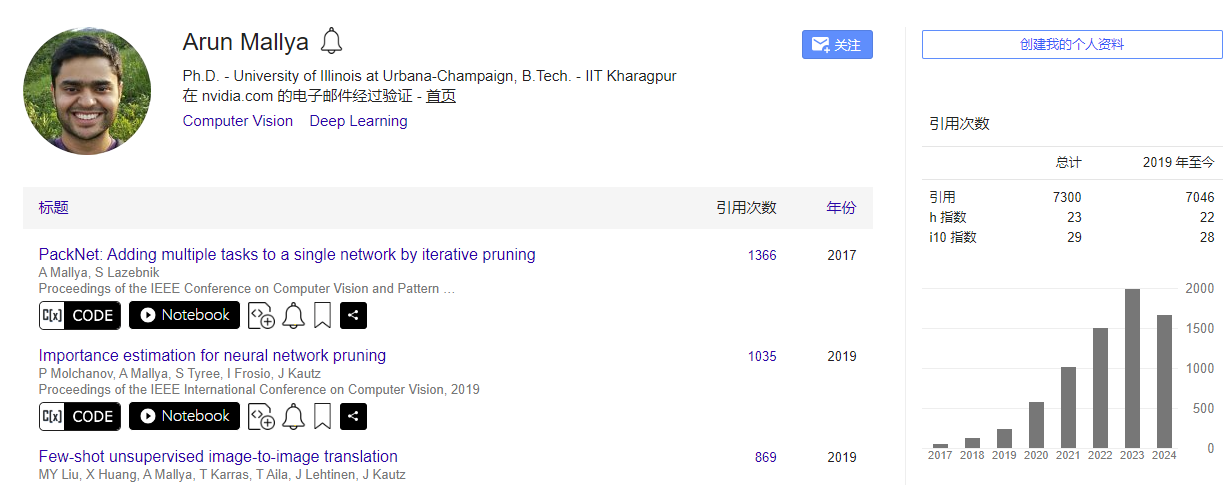
1 介绍
年份:2018
期刊: Proceedings of the IEEE conference on Computer Vision and Pattern Recognitio
引用量:1366
代码:https://github.com/arunmallya/packnet
本文的算法通过迭代剪枝和网络再训练,释放神经网络中的冗余参数,从而在单一网络中加入多个任务,避免灾难性遗忘。
Mallya A, Lazebnik S. Packnet: Adding multiple tasks to a single network by iterative pruning[C]//Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2018: 7765-7773.
2 创新点
- 基于剪枝的多任务学习方法:利用网络剪枝技术,释放神经网络中的冗余参数,确保在增加新任务时不增加网络容量,避免灾难性遗忘。
- 迭代剪枝和再训练机制:提出了一种迭代剪枝和再训练的流程,每次剪枝后对网络进行再训练,以保持当前任务的准确性,同时释放出用于学习新任务的参数。
- 任务特定的参数掩码:通过为每个任务生成特定的参数掩码(masks),这些掩码在推理阶段被应用,确保每个任务使用的参数与其训练时一致,从而保持任务的准确性。
- 无灾难性遗忘:不同于以往使用代理损失来维护旧任务性能的方法(如Elastic Weight Consolidation),本文的方法在增加新任务时,不修改对旧任务重要的权重,确保旧任务的性能不受影响。
- 低存储开销:每增加一个新任务,只需存储一个二进制参数选择掩码,存储开销较低,并且可以通过对掩码进行压缩进一步减少存储空间。
- 适用多种网络架构和大规模数据集:该方法在VGG-16、ResNet、DenseNet等多种神经网络架构上进行了实验,成功地在ImageNet训练的基础上加入了多个细粒度分类任务,且性能接近单独训练的网络。
- 可扩展性:该方法不仅能够处理多个小型任务的叠加,还能处理如Places365这种大规模数据集的任务,展示了其在大规模任务上的扩展性。
3 算法
本文提出的算法,名为 PackNet,其核心原理是通过迭代剪枝(Iterative Pruning)的方法,将多个学习任务集成到单一深度神经网络中,同时避免因学习新任务而导致的对旧任务性能的灾难性遗忘(Catastrophic Forgetting)。
- 初始训练:首先,使用一个深度神经网络(例如VGG-16)在初始任务(如ImageNet分类)上进行训练,得到一组权重。
- 迭代剪枝:
- 在每轮迭代中,算法会选择一定比例的权重(例如50%或75%),将这些权重的值设为零,从而“剪掉”这些连接,释放出参数空间。
- 剪枝操作主要基于权重的绝对大小,移除那些权重值较小的连接,因为它们对网络的贡献较小。
- 重训练:
- 剪枝后,网络需要重新训练以恢复性能。这一步骤通常需要较少的迭代次数。
- 重训练后,网络会形成稀疏的权重分布,但性能损失很小。
- 添加新任务:
- 在添加新任务时,之前通过剪枝保留的权重保持不变,而新释放的参数空间被用来学习新任务。
- 这个过程可以重复进行,以添加更多的任务。
- 参数共享与特定任务参数:
- 对于每个任务,网络会生成特定的参数掩码,这些掩码指示了哪些参数是活跃的。
- 新任务可以重用之前任务学习的权重(如果这些权重被释放),也可以修改它们以适应新任务。
- 存储与推理:
- 由于只需要存储每个任务的参数掩码,因此添加新任务的存储开销非常小。
- 在推理时,根据选定的任务,应用相应的掩码以激活网络中相应的参数,从而复制为相应任务学习的特征。
5 实验分析
对PackNet方法的性能影响因素进行了详细的分析
- 训练顺序的影响:
- 随着更多任务被添加到网络中,后续添加的任务可使用的网络参数比例减少,这导致后续任务的准确率有所下降。
- 实验表明,如果可能预先确定任务的顺序,应优先添加最困难或最不相关的任务。
- 剪枝比例的影响:
- 剪枝后立即进行重训练对于性能恢复至关重要,尤其是当剪枝比例较大时。
- 对于新添加的任务,即使在50%和75%的剪枝比例下,不进行重训练也不会显著增加错误率。
- 即使在90%的激进剪枝比例下,只要随后进行重训练,与未剪枝的错误率相比,错误率的增加也很小。
- 训练单独偏置的影响:
- 实验表明,学习每层的任务特定偏置并没有显著改善性能。
- 因此,选择共享偏置以减少所提出方法的存储开销。
- 是否需要训练所有层:
- 实验显示,仅训练全连接层的准确率提升有限,而训练卷积层可以显著提高准确率,对于获得良好性能是必要的。
- 与基于滤波器的剪枝比较:
- 与基于权重的剪枝相比,基于滤波器的剪枝(即剪枝整个滤波器而不是单个权重)在VGG-16网络上的剪枝能力有限,无法有效地适应多个任务,而不会显著降低性能。
- 基于滤波器的剪枝方法在实现上更为复杂,尤其是在处理具有残差连接和跳跃连接的网络时。
6 思考
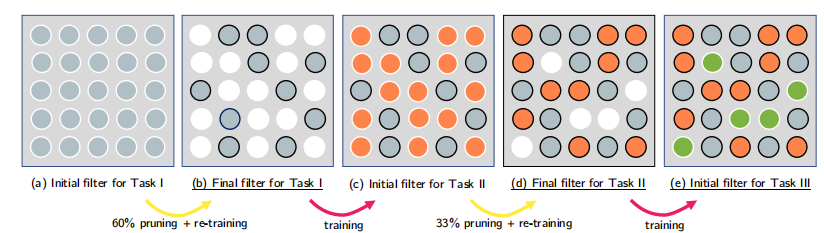
(1)没有被剪枝的神经元在下一次剪枝时,还可能会被剪枝吗?
没有被剪枝的神经元在下一次剪枝时不会再次被考虑剪枝。在每次迭代剪枝过程中,只有当前任务的权重会被考虑剪枝。对于之前任务的权重,一旦在它们的特定迭代中被保留下来(即没有被剪枝),这些权重就会被固定,并且在后续的剪枝过程中不会再被修改。图1中的例子说明了这一过程。在任务I完成后,进行了60%的剪枝,并重训练网络。在这一步骤中未被剪枝的权重(灰色圆圈)在后续步骤中保持不变,不会参与任务II的剪枝。当添加任务II时,只有那些为任务II而剪枝的权重(橙色圆圈)会参与下一次的剪枝过程。任务I中未被剪枝的权重不会被触及。这种策略确保了在添加新任务时,之前任务的性能不会受到影响,因为它们的相关权重不会被改变。因此,根据PackNet算法的原理,一旦权重在特定任务的剪枝过程中被保留,它们在后续的任务中将不会被再次剪枝,从而确保了对先前任务的鲁棒性。


















 2160
2160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











