









1 介绍
年份:2019
会议: 2019CVPR
引用量:341
Ostapenko O, Puscas M, Klein T, et al. Learning to remember: A synaptic plasticity driven framework for continual learning[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019: 11321-11329.
本文提出了一种名为动态生成记忆(DGM,生成回放+动态扩展网络结构)的持续学习框架。通过结合真实样本和合成样本的对抗训练,以及通过学习二进制掩码来模拟神经可塑性,从而实现对新任务的学习和对旧任务记忆的保持),DGM算法的核心在于使用神经掩码来模拟神经连接的可塑性,并通过动态网络扩展机制来适应新任务,以在连续学习过程中保持旧知识并有效地整合新知识。
2 创新点
- 动态生成记忆(DGM)框架:提出了一个基于突触可塑性驱动的持续学习框架,用于处理连续学习任务中的灾难性遗忘问题。
- 条件生成对抗网络:DGM框架依赖于条件生成对抗网络(cGANs),并引入了可学习的连接可塑性,通过神经掩码技术实现。
- 神经掩码的两种变体:评估了神经掩码应用于层激活和直接应用于连接权重的两种变体,分别称为DGMa和DGMw。
- 动态网络扩展机制:提出了一种动态网络扩展机制,确保模型能够适应不断增长的任务数量,通过从学习到的二进制掩码动态确定添加的容量。
- 对抗训练中的增量学习:DGM能够在对抗训练中不依赖于重放先前知识的情况下,增量学习新信息。
- 参数级注意力机制:DGM通过参数级注意力机制学习稀疏的注意力掩码,这在以往的研究中尚未被同时学习并与基础网络一起训练。
- 资源高效的持续学习:通过比较所提出的方法与现有持续学习方法,展示了DGM在效率、参数重用性和网络增长速度方面的优势。
- 实验验证:在多个视觉分类任务上评估了DGM的性能,并与现有的持续学习方法进行了比较,证明了其有效性。
3 算法
3.1 算法原理
本文介绍了一个名为Dynamic Generative Memory (DGM)的框架,它是一个基于突触可塑性原理的持续学习(Continual Learning, CL)框架。DGM旨在解决持续学习中的两个主要挑战:1) 在学习新任务的同时保持旧知识并从中受益;2) 保证模型的可扩展性,以适应不断增长的数据量。DGM框架的核心思想和算法原理如下:
- 条件生成对抗网络(Conditional Generative Adversarial Networks, GANs):
- DGM利用条件生成对抗网络(CGANs)来模拟学习过程中的神经可塑性。CGANs能够生成特定任务的数据样本,这些样本可以被用来在后续任务中重放,以帮助模型保持对先前任务的记忆。
- 神经掩码(Neural Masking):
- DGM通过学习神经掩码来实现连接可塑性,这些掩码可以应用于网络的层激活或直接应用于连接权重。掩码的作用是模拟神经突触的强化或削弱,通过这种方式,模型可以在学习新任务时保护和重用旧知识。
- 动态网络扩展机制(Dynamic Network Expansion):
- 为了适应不断增长的任务数量,DGM引入了动态网络扩展机制。这个机制通过增加网络容量来保证模型有足够的容量来处理新任务,而不会耗尽模型的容量。
- 二进制掩码学习(Learning Binary Masks):
- DGM学习一组二进制掩码,这些掩码用于控制生成器网络中每一层的权重。这些掩码通过一个阈值函数(如sigmoid函数)来确定,以模拟神经突触的开启或关闭。
- 对抗性训练(Adversarial Training):
- DGM在对抗性训练的背景下进行,这意味着生成器和判别器网络在训练过程中相互竞争,以提高生成样本的质量和判别能力。
- 参数重用与保留(Parameter Reusability and Reservation):
- DGM通过动态调整掩码来控制哪些参数被用于新任务,哪些被保留用于旧任务。这种机制有助于减少灾难性遗忘(Catastrophic Forgetting),即在学习新任务时丢失旧任务知识的现象。
- 稀疏注意力掩码(Sparse Attention Masks):
- DGM通过学习稀疏的注意力掩码来有效地模拟网络权重或激活的连接可塑性,这有助于在不重放先前知识的情况下增量学习新信息。
3.2 算法步骤
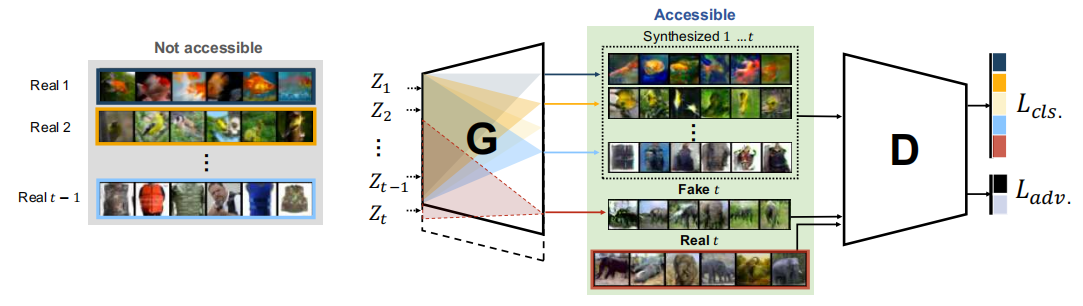
- 初始化:
- 初始化一个条件生成对抗网络(CGAN),包括一个生成器(G)和一个判别器(D)。
- 初始化生成器和判别器的参数,以及用于模拟神经可塑性的二进制掩码。
- 训练任务 ( t ):
- 对于每个新任务 ( t ),使用当前任务的数据 ( S_t ) 来训练模型。
- 使用辅助输出对生成器进行分类任务的训练。
- 使用真实样本和生成的假样本训练判别器。
- 学习二进制掩码:
- 对于生成器的每一层,学习一个二进制掩码 ( M_t ),该掩码决定了哪些权重或激活将参与到当前任务的学习中。
- 使用阈值函数(如sigmoid)和缩放参数 ( s ) 来更新掩码,以模拟神经突触的开启或关闭。
- 动态网络扩展:
- 根据学习到的二进制掩码,动态扩展网络以保持足够的容量来处理新任务。
- 对于DGMw(掩码应用于权重),扩展输出神经元的数量。
- 对于DGMa(掩码应用于激活),扩展输出神经元的数量以保持自由参数的数量。
- 对抗性训练:
- 使用CGAN架构,同时训练生成器和判别器。
- 生成器的目标是生成尽可能真实的样本,而判别器的目标是区分真实样本和生成样本。
- 正则化和稀疏性:
- 通过正则化项 ( R_t ) 来促进掩码的稀疏性,鼓励重用先前任务中使用的参数。
- 参数更新:
- 在梯度下降过程中,根据累积掩码 ( m_{\leq t} ) 调整梯度,以保护先前任务的知识不被新任务的学习所覆盖。
- 评估和测试:
- 在测试阶段,评估模型在所有已学习任务上的分类性能。
- 使用单头评估(single-head evaluation)来测试模型对所有已学习类别的识别能力。
- 迭代:
- 重复步骤2-8,直到所有任务都已学习完毕。
- 结果分析:
- 分析模型在不同任务上的性能,包括分类准确率和网络扩展情况。
- 比较DGM与其他持续学习方法的性能。
4 实验分析
- 数据集和设置:
- 实验在MNIST、SVHN、CIFAR-10和ImageNet-50这四个基准数据集上进行。
- 采用严格类增量设置(class-incremental setup),意味着模型需要在不同时间学习不同类别的数据,且不允许存储先前类别的真实样本。
- 性能比较:
- 与现有的几种方法相比,包括基于情景记忆(episodic memory)的方法和基于生成记忆(generative memory)的方法。
- 使用联合训练(Joint Training, JT)作为性能上限的基准。
- DGM的性能:
- 在MNIST数据集上,DGM在5任务(A5)和10任务(A10)的平均准确率超过了其他基于生成记忆的方法,并且接近或超过了联合训练的性能。
- 在SVHN数据集上,DGM显著优于其他方法,显示出更好的抗灾难性遗忘能力。
- 网络扩展:
- DGM有效地扩展了生成器网络,以适应新任务的学习,而不需要存储旧样本。
- 在MNIST和SVHN上,DGM的网络扩展效率比线性增长模式更高。
- 存储效率:
- 与存储预处理的训练样本相比,存储DGM的生成器(包括权重和掩码)需要的磁盘空间更少,显示出更高的存储效率。
- DGMw与DGMa的比较:
- DGMw(掩码应用于权重)在性能上优于DGMa(掩码应用于激活),尤其是在参数重用和网络增长方面。
- DGMw的网络增长速度比DGMa慢,显示出更高的效率。
- 与iCarl的比较:
- 当允许部分存储真实样本时,DGM与iCarl(一种基于存储真实样本的方法)进行了比较。
- 在某些条件下,DGM的性能超过了iCarl,尤其是当添加真实样本到重放循环中时。
- 掩码学习动态:
- 分析了DGMa中掩码值随训练时间的变化,展示了从短期记忆到长期记忆的转变。
- 图像生成质量:
- 在MNIST、SVHN和ImageNet数据集上,DGM生成的图像质量在多个任务学习后仍然保持了类别区分性。


















 1170
1170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











