









代码
import os, re
global countFile
countFile = 0
global format
# format=0 #0 for typora, 1 for obsidian
'''
由于obsidian和typora支持的链接格式不同
这里定义了一个全局变量format
当format=0时候为typora
format=1的时候为obsidian
这里默认是obsidian格式的
'''
def get_filename(path, allfile, dict_filetype=None):
'''递归获得所有符合条件的文件名
@param : path 起始目录,要检查的根目录
@param : allfile 传入的初始文件名列表,填空即可
@param : dict_filetype 要检查的文件类型,为None时则不检查返回所有。默认为None
@return: 列表 所有与 dict_filetype 对应的文件名
'''
global countFile
global format
filelist = os.listdir(path)
for filename in filelist:
filepath = os.path.join(path, filename)
# 判断文件夹
if os.path.isdir(filepath):
# 文件夹继续递归
with open(outFileName, "a", encoding="utf-8") as o:
if (re.search('.obsidian', filepath)):
pass
else:
o.write("\n ## "+ filepath[2:].replace('\\','/') + '\n')
get_filename(filepath, allfile, dict_filetype)
else:
temp_file_type = filepath.split(".")[-1]
# 判断文件类型
if dict_filetype is None or temp_file_type in dict_filetype:
allfile.append(filepath)
countFile+=1
base = os.path.basename(filepath)
# print(filepath[2:])
# print(base)
with open(outFileName, "a", encoding="utf-8") as o:
if format == 0:
o.write('【'+str(countFile)+'】['+base+']')
o.write('('+filepath.replace('\\','/')+')'+'\n')
elif format == 1:
o.write('【'+str(countFile)+'】[['+base+']]\n')
return allfile
def generate(outFileName):
global countFile
# 判断文件是否存在
if (os.path.exists(outFileName)) :
#存在,则删除文件
os.remove(outFileName)
#打印时间
import datetime
time = datetime.datetime.now().strftime('%Y年%m月%d日 %H:%M:%S')
get_filename('.', [], ["pdf"])
with open(outFileName, 'r+', encoding='utf-8') as o:
file_data = o.read()
o.seek(0, 0)
print("目录生成完成,生成时间:"+time,"\n共有PDF文献"+str(countFile)+"个\n"+file_data, file=o)
print("目录生成完成,生成时间:"+time,"\n共有PDF文献"+str(countFile)+"个")
countFile=0
format=0
outFileName = "自动生成文献目录-typora.md"
generate(outFileName)
format=1
outFileName = "自动生成文献目录-obsidian.md"
generate(outFileName)
用法:
复制上述代码保存为: 自动生成文献目录.py
右键在当前文件夹打开powershell终端输入
python .\自动生成文献目录.py
由于obsidian和typora支持的链接格式不同
这里定义了一个全局变量format
当format=0时候为typora
format=1的时候为obsidian
这里默认是obsidian格式的
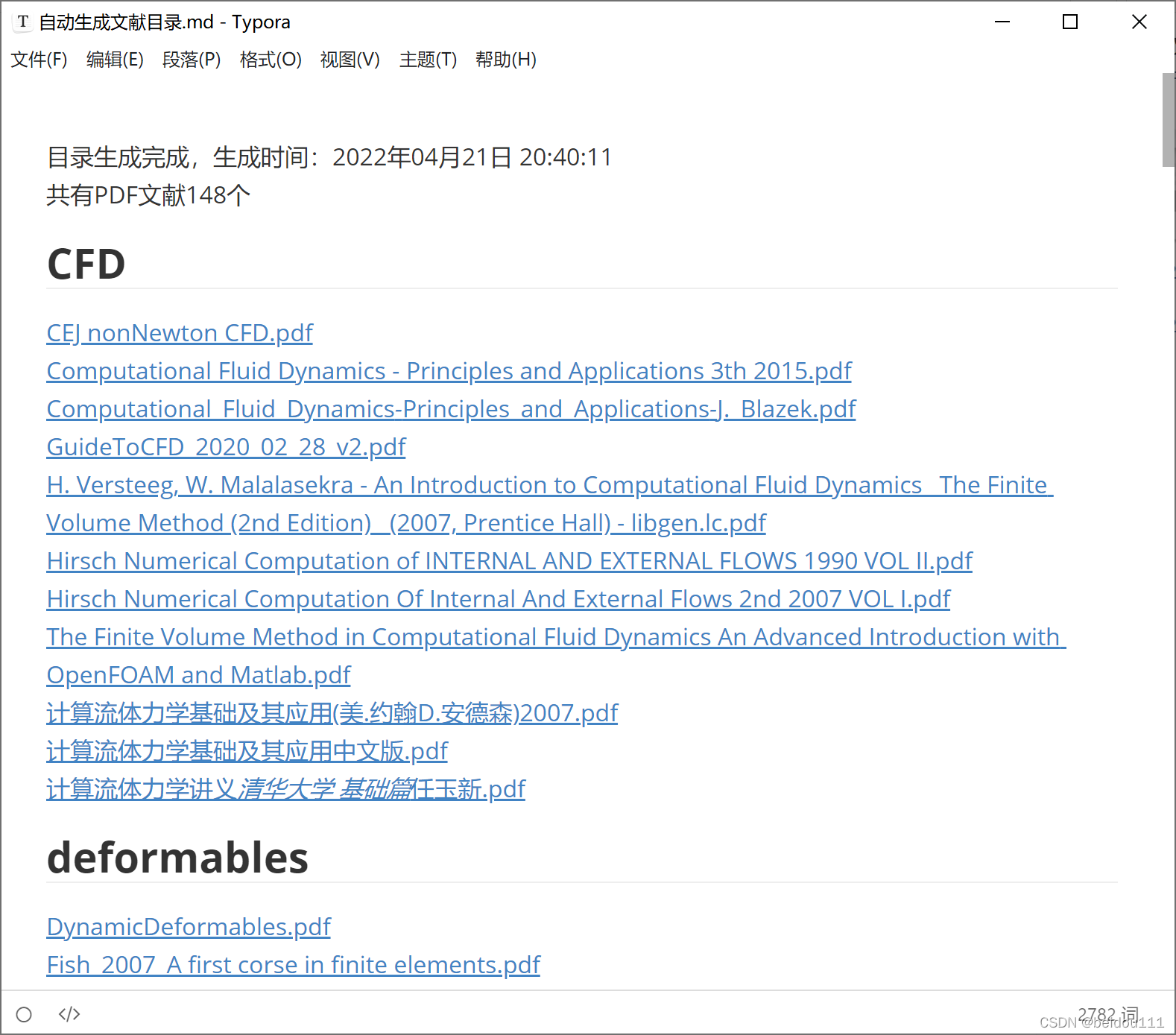
效果

Typora
obsidian
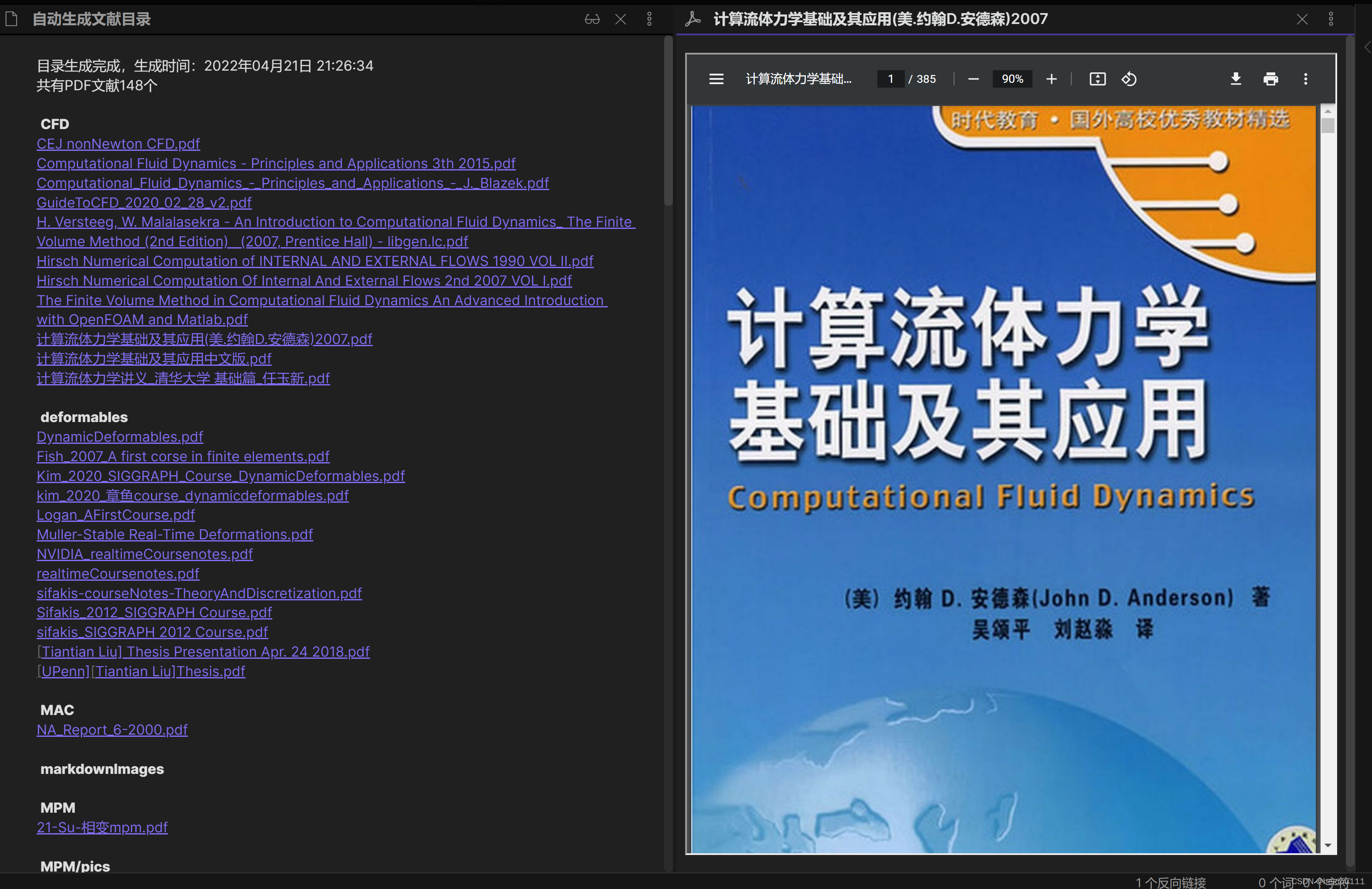
obsidian的一个好处是能自动生成关系图谱


















 395
395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









