






目录
在Logsitic回归和线性回归以及前面的MNIST手写数字识别中使用的方法属于神经网络中的全连接层(Dense Layer 或 Fully Connected Layer)。公式如下
当维度较高的特征(二位或二维以上)使用全连接层时,需要先将这些特征展开为一维特征才能输入到全连接层中,如在之前的MNIST手写数字识别中,MNIST中的样本是图像,是[28,28,1]这样的矩阵数据,在输入全连接层时,先将数据展开为一维再输入的。对于图像数据,尤其是高分辨率的图像,直接展平后输入到全连接层会导致网络参数数量急剧增加。这是因为每个像素都会与全连接层的每个神经元建立连接,从而形成一个巨大的权重矩阵。这不仅增加了计算复杂度,也容易导致过拟合,因为模型需要学习如此多的参数。由于全连接层直接处理展平后的图像数据,它们无法学习到图像的局部特征和空间结构。这会导致模型在训练集上表现良好,但在测试集上泛化能力较差,即出现过拟合现象。
针对与在具有空间结构的数据(二维图像或三维视频),先使用卷积神经网络(Convolutional Neural Networks, CNNs)学习数据集中的特征可以使模型具有更好的性能和泛化能力。
一、卷积神经网络中卷积核
卷积神经网络(Convolutional Neural Network,CNN)中的卷积核是其关键组成部分,负责从输入数据中提取特征。卷积核是一种小型矩阵,通常在CNN的卷积层中使用,用于扫描输入图像并提取特征。卷积核通过对输入图像进行卷积操作来执行特征提取,涉及将卷积核与输入图像的一部分区域进行逐元素相乘,并将结果相加以生成输出特征图。
卷积核(Convolutional Kernel)或称为滤波器(Filter)可以被看作是一个参数矩阵(或称为权重矩阵)。这个矩阵中的每个元素都是可训练的参数,它们会在网络训练过程中通过反向传播算法进行更新,以优化网络在特定任务上的性能。
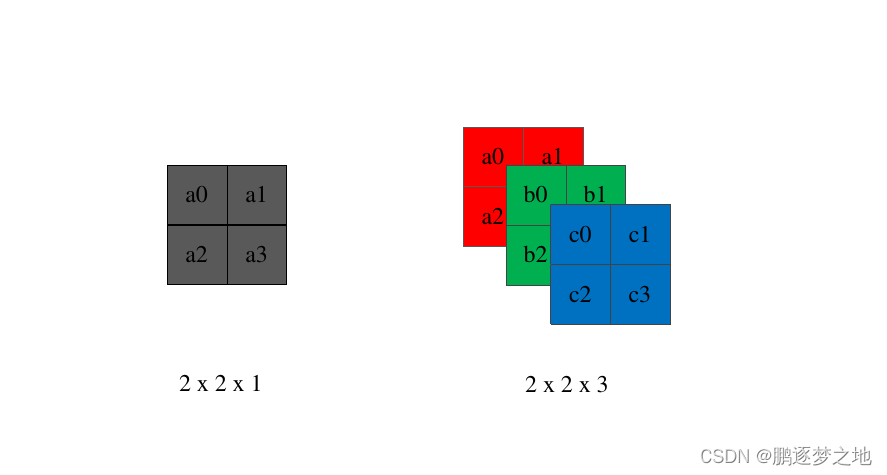
如图所示的两个卷积核,带一个卷积核只有一个通道,用于处理通道数为1的数据,如MNIST中图像通道为1;第二个卷积核有三个通道,用于处理通道数为3的数据,如彩色图像(RGB通道)。卷积核中的参数就是需要在训练模型时学习的内容,如同全连接层中权重参数weights。
二、卷积核提取特征
1.卷积核提取特征过程
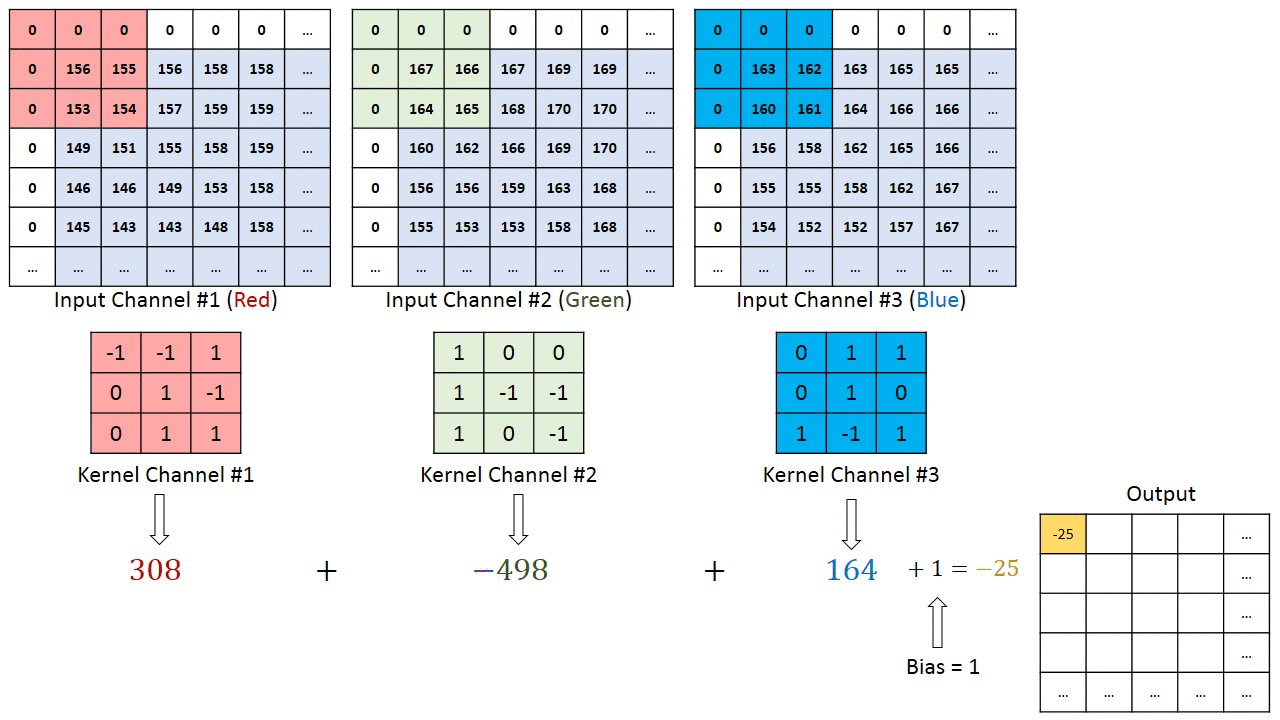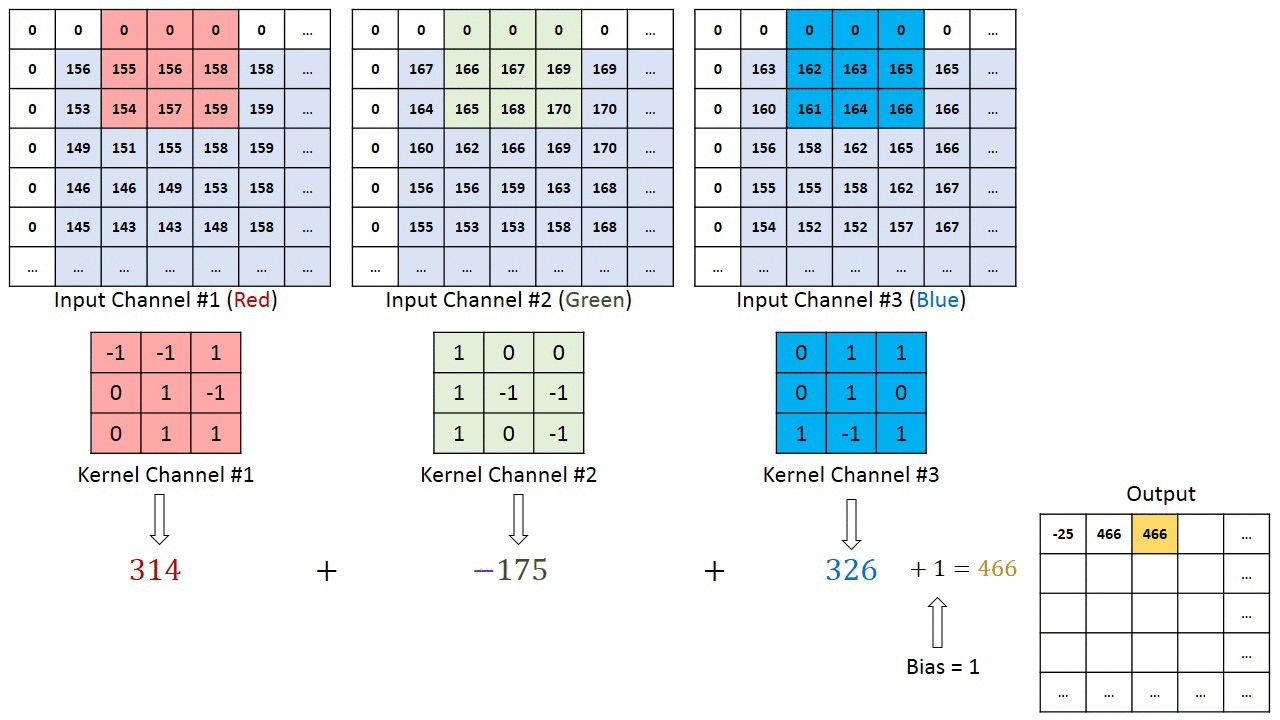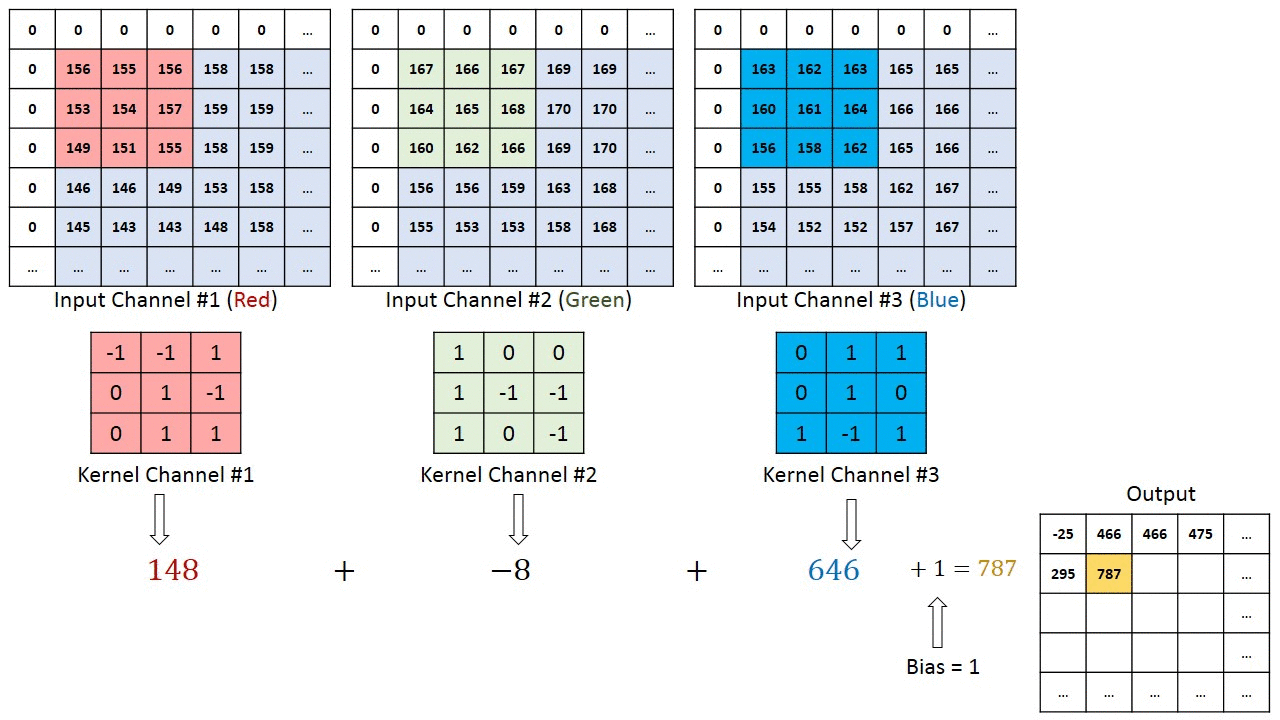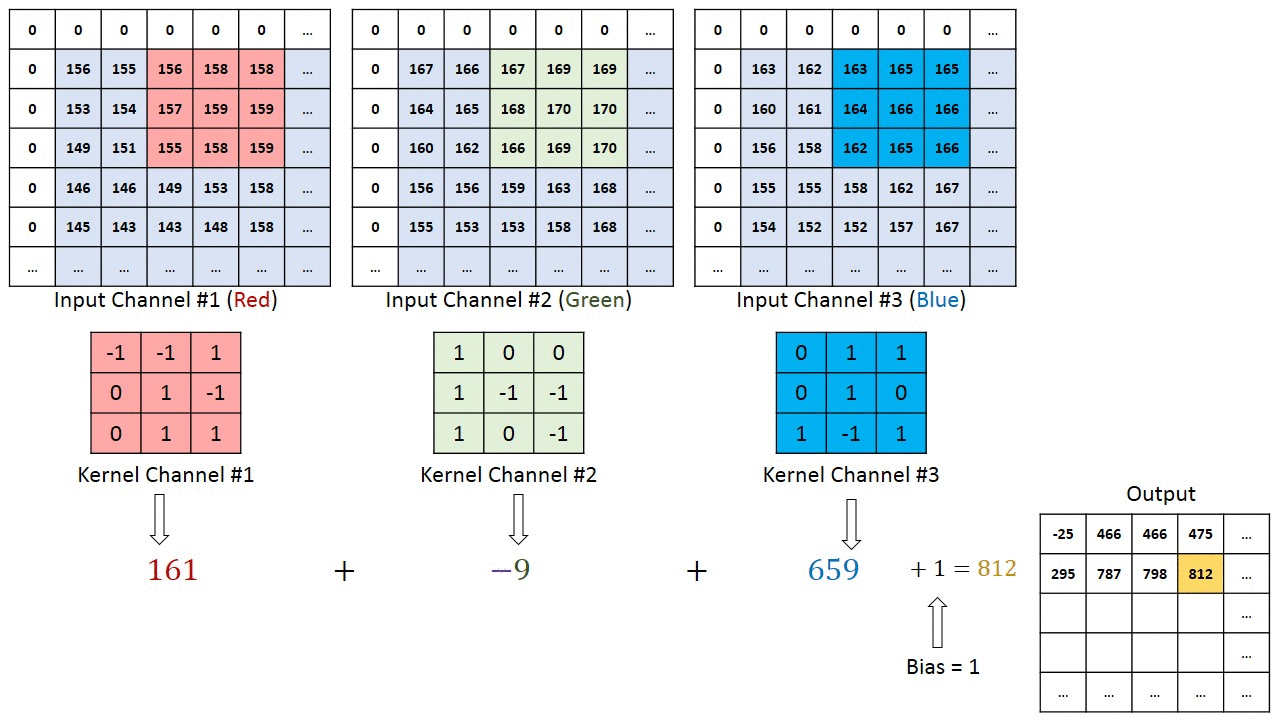
卷积核提取特征的过程
- 滑动卷积核:将卷积核在输入信号的每个位置上进行滑动。每次滑动时,卷积核都会覆盖输入信号的一个局部区域。
- 逐元素相乘:将卷积核所覆盖的区域与输入信号的对应部分进行逐元素相乘。
- 求和:将相乘后的结果进行求和运算,得到一个标量值。这个标量值就是卷积运算在该位置上的输出。
- 移动与重复:在上一步求和之后,根据设置的步长,将卷积核向下或向右移动一个像素(或其他单位),然后继续进行相乘和求和的操作(第2,3步操作)。
上图中输入是彩色图像三通道(RGB),卷积核也是三通道(3x3),卷积核的每个通道和输入的对应通道进行运算,如图像的red通道和卷积核的1号通道数据进行运算,red通道不会再和卷积核的2号3号通道运算。
2.卷积核的滑动步长、尺寸、个数与输出特征图的关系
上图中的步长为1,即卷积核提取的第一个局部区域和第二个区域的移动距离为1。假设上图输入图像的尺寸为n x m x 3,由于卷积核为3 x 3 x 3,卷积核的个数1,步长为1,最终输出的特征图为[(n-2) , (m-2) ,1]。若卷积核的步长设置为2,最终输出的特征图为[(n-1)/2 ,(m-1)/2 ,1]。即输出的特征图的尺寸与卷积核的滑动步长和尺寸有关。
卷积核的大小若是1 x 1,步长为1,则输出的特征图与输入图像的尺寸将会一样。
最终输出的通道数与卷积核的个数有关,卷积核有k个,输出的结果就有k个通道。
假设输入图像的尺寸为[m,n,c],卷积核为[p,q,c],有k个卷积核,滑动步长为s,输入图像无填充,那么输出特征图的尺寸为[ ,
, k]。
3.边界效应和填充
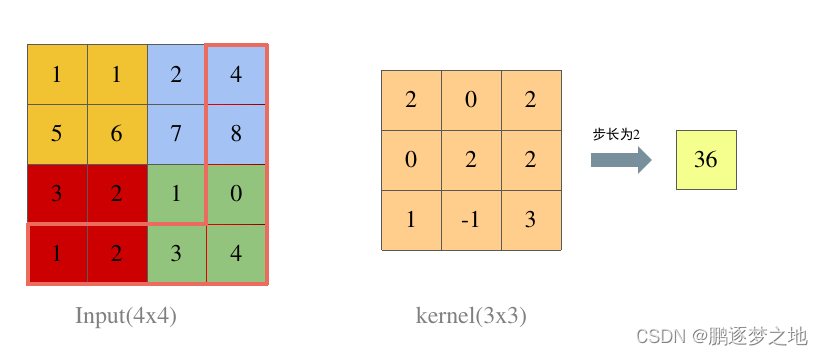
假设输入的尺寸为4 x 4,卷积核大小为3 x 3,步长为2,输出的尺寸为1 x 1。如上图所示,这种情况下输入的最后一列和最后一行的信息并没有被卷积核提取,卷积核只提取了前三行和前三列的数据,导致边缘信息丢失,这些边缘信息可能包含重要的特征,因此信息丢失可能会降低模型的性能。
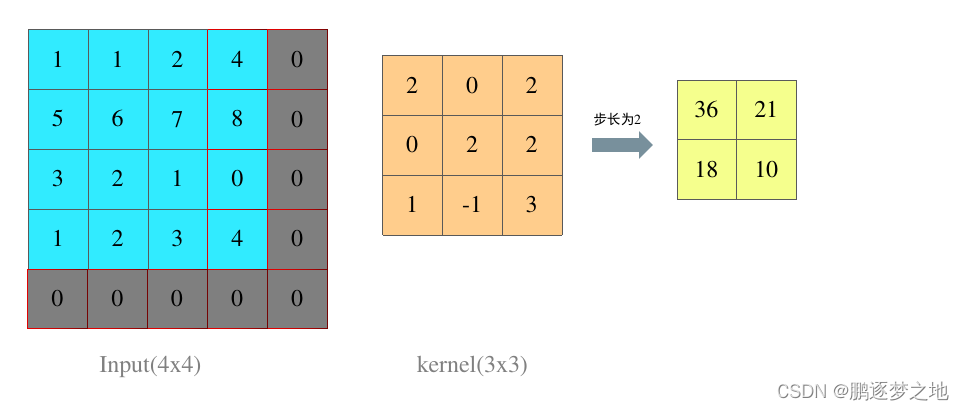
针对于这种情况,可以在边界进行填充,填充数字可以设定,默认为0,当在边缘填充适当行列后,边缘信息就不会丢失。同时用这种方法可以在任意大小卷积核情况下使输出的特征图的尺寸与输入图像的尺寸一致。
4.池化运算
池化运算主要用于减少数据量,降低计算复杂度,以及增加特征的不变性。常见池化运算包括最大池化(Max Pooling)、平均池化(Average Pooling)、全局池化(Global Pooling)、自适应池化(Adaptive Pooling)。
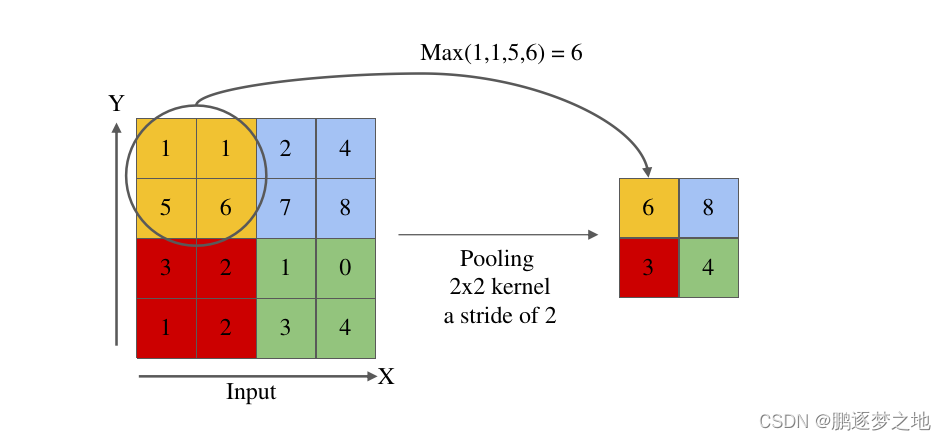
最大池化运算如上图所示,卷积核大小为2 x 2,步长为2,采用最大池化能够提取出输入特征图中的最重要特征,并保持特征的不变性。
三、用卷积神经网络实现MNIST手写数字分类
# This is a sample Python script pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
# Press Shift+F10 to execute it or replace it with your code.
# Press Double Shift to search everywhere for classes, files, tool windows, actions, and settings.
import numpy as np
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
from tqdm import tqdm
n_epochs = 3
batch_size_train = 64 #训练模型时,一个批次的数据(当前代表64个MNIST图片),
# 意味着在每次权重更新时,你会从训练集中选择64个样本(也称为一个“批次”)来计算梯度,并使用这些梯度来更新模型的权重。
batch_size_eval = 200 #测试模型时,一次批次的数据(当前代表200个MNIST图片)
batch_size_test = 200 #测试模型时,一次批次的数据(当前代表200个MNIST图片)
learning_rate = 0.01 #学习率
momentum = 0.5 #使用optim.SGD(随机梯度下降)优化器时,momentum是一个重要的参数。它代表了动量(Momentum)的大小,是动量优化算法中的一个关键概念。
log_interval = 10
random_seed = 1
torch.manual_seed(random_seed) #用于设置随机数生成器种子(seed)的函数。设置种子可以确保在每次运行代码时,与随机数生成相关的操作(如权重初始化、数据打乱等)都会生成相同的随机数序列,从而使结果具有可复现性。
trainset =torchvision.datasets.MNIST('./data/', train=True, download=True, #训练集下载
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(), #转换数据类型为Tensor
torchvision.transforms.Normalize(
(0.1307,), (0.3081,)) #数据标准化
]))
#------------------------------------------------------------------#
# 将训练集再划分为训练集和测试集(训练集:测试集=4:1) #
#------------------------------------------------------------------#
train_size = len(trainset)
indices = list(range(train_size))
# 划分索引
split = int(0.8 * train_size)
train_indices, val_indices = indices[:split], indices[split:]
# 创建训练集和验证集的子集
trainset_subset = torch.utils.data.Subset(trainset, train_indices)
valset_subset = torch.utils.data.Subset(trainset, val_indices)
# 创建数据加载器
train_loader = torch.utils.data.DataLoader(trainset_subset, batch_size=64, shuffle=True)
eval_loader = torch.utils.data.DataLoader(valset_subset, batch_size=64, shuffle=False)
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./data/', train=False, download=True, #测试集下载
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size_test, shuffle=True)
def show_MNIST():
#展示MNIST图片
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
fig = plt.figure()
for i in range(6):
plt.subplot(2, 3, i + 1)
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title("Ground Truth: {}".format(example_targets[i]))
plt.xticks([])
plt.yticks([])
plt.show()
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1,8,3,padding=1)
self.maxpool=nn.MaxPool2d(2,2) #(28,28,8)->(14,14,8)
self.conv2=nn.Conv2d(8,32,3,padding=1)
self.fc1 = nn.Linear(1568, 49)
self.fc2 = nn.Linear(49, 10)
def forward(self, x):
x=F.relu(self.conv1(x)) #(28,28,1)->(28,28,8)
x=self.maxpool(x) #(28,28,8)->(14,14,8)
x=F.relu(self.conv2(x)) #(14,14,8)->(14,14,32)
x=self.maxpool(x) #(14,14,32)->(7,7,32)
x = x.view(-1, 1568) # 降维 (7,7,32)->7*7*32=1568
x = F.relu(self.fc1(x)) # 激活函数relu
x = F.dropout(x, training=self.training) #dropout正则化,降低过拟合
x = self.fc2(x)
return F.log_softmax(x,dim=1)
network = Net()
optimizer = optim.SGD(network.parameters(), lr=learning_rate, momentum=momentum) #优化器
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") #检测电脑是否能使用cuda训练,不行则使用cpu
network=network.to(device)
def train(epoch,epochs):
#训练模型
train_loss=0
network.train()
pbar = tqdm(total=len(train_loader), desc=f'Epoch {epoch + 1}/{epochs}', mininterval=0.3)
for batch_idx, (data, target) in enumerate(train_loader): #批次,输入数据,标签
data = data.to(device)
target=target.to(device)
optimizer.zero_grad() #清空优化器中的梯度
output = network(data) #前向传播,获得当前模型的预测值
loss = F.nll_loss(output, target) #真实值和预测值之前的损失
loss.backward() #反向传播,计算损失函数关于模型中参数梯度
optimizer.step() #更新模型中参数
#输出当前训练轮次,批次,损失等
train_loss +=loss.item()
'''torch.save(network.state_dict(), './model.pth')
torch.save(optimizer.state_dict(), './optimizer.pth')'''
pbar.set_postfix(**{'train loss' : train_loss/(batch_idx+1)})
pbar.update(1)
return train_loss/(batch_idx+1)
def eval(epoch,epochs):
#测试模型
network.eval()
pbar = tqdm(total=len(eval_loader), desc=f'Epoch {epoch + 1}/{epochs}', mininterval=0.3)
eval_loss = 0
with torch.no_grad(): #仅测试模型,禁用梯度计算
for batch_idx, (data, target) in enumerate(eval_loader):
data=data.to(device)
target=target.to(device)
output = network(data)
eval_loss += F.nll_loss(output, target).item()
pbar.set_postfix(**{'eval loss': eval_loss / (batch_idx + 1)})
pbar.update(1)
return eval_loss/(batch_idx + 1)
def model_fit(epochs):
best_loss=1e7
for epoch in range(epochs):
train_loss=train(epoch,epochs)
eval_loss=eval(epoch,epochs)
print('\nEpoch: {}\tTrain Loss: {:.6f}\tEval Loss: {:.6f}'.format(epoch+1,train_loss,eval_loss))
if eval_loss<best_loss:
best_loss=eval_loss
torch.save(network.state_dict(), 'model.pth')
def test():
#如果已经训练好了权重,模型直接加载权重文件进行测试#
model_test=Net()
model_test.load_state_dict(torch.load('model.pth'))
model_test.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
output = model_test(data)
test_loss += F.nll_loss(output, target, size_average=False).item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).sum()
test_loss /= len(test_loader.dataset)
print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
#----------------------------------------#
# 展示一些测试样本 #
# ----------------------------------------#
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
with torch.no_grad():
output = model_test(example_data)
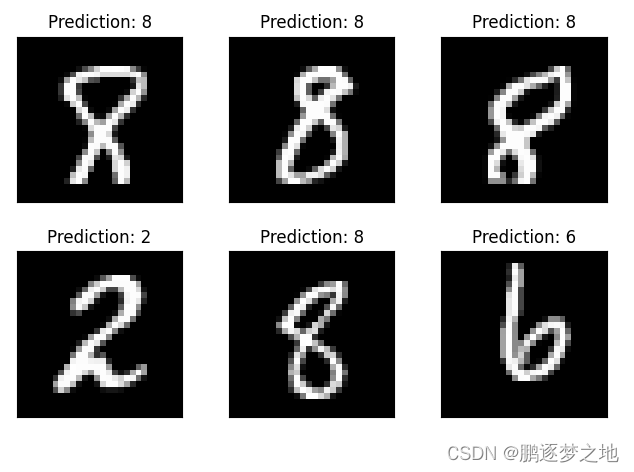
for i in range(6):
plt.subplot(2, 3, i + 1)
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title("Prediction: {}".format(output.data.max(1, keepdim=True)[1][i].item()))
plt.xticks([])
plt.yticks([])
plt.show()
if __name__=="__main__":
model_fit(100)
#test()
以上代码在模型网络中加入了卷积神经网络,最后测试结果如下

















 785
785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









