







记录一次在华为显卡上部署DS 32B蒸馏模型的过程,主要是一些注意事项和报错处理。报错处理是咨询DS老师(DeepSeek)得知怎么处理的。
部署参考文章
部署主要是参考了昇腾社区和魔乐社区大佬的教程,两篇文章内容是一致的,链接如下:
昇腾社区:DeepSeek-R1-Distill-Qwen-32B-模型库-ModelZoo-昇腾社区
魔乐社区:MindIE/DeepSeek-R1-Distill-Qwen-32B | 魔乐社区
注意事项及报错整理(按文章顺序,没提到的就按文章进行操作)
1 权重无需转换
由于蒸馏版本的模型本质上还是Qwen2.5模型,模型权重文件格式为.safetensor格式,所以无需转换。
那么如果是部署的DeepSeek-R1或V3模型,则需要进行权重转换,具体请参考下面这篇文章。或者在昇腾社区的Modelzoo中搜索ds系列模型参考。
DeepSeek-R1部署:DeepSeek-R1-模型库-ModelZoo-昇腾社区
2 获取镜像
通过文章链接去下载对应的镜像,需要根据你所实际部署时的机器来决定,我这里是在一台Atlas 300I DUO服务器上进行部署的,镜像选的是1.0.0-300I-Duo-py311-openeuler24.03-lts。需要先申请权限,得到权限后可以直接进行docker pull操作。直接pull下来的镜像就无需像文章中先docker load了,直接创建容器即可。(一定要pull正确的镜像)
3 新建容器
REPOSITORY和TAG通过docker images查看后,复制贴到下面命令对应位置。<container-name>给容器取个名。权重文件路径记得替换。
注:以下bash命令是在root权限下创建的容器,如果不是root,请参考文章中非root权限对应命令。
docker run -it -d --net=host --shm-size=1g \
--privileged \
--name <container-name> \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device=/dev/devmm_svm \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro \
-v /usr/local/sbin:/usr/local/sbin:ro \
-v ${path-to-weights}:${path-to-weights}:ro \
${REPOSITORY}:${TAG} bash4 服务化部署
认证文件缺失错误
需要特别注意的是,在修改config.json文件时,httpsEnabled参数一定要记得改成false,关闭tls https认证。
"httpsEnabled" : false
如果没有修改的话,在拉起服务的时候会有tls https认证,然后会出现一系列认证文件缺失的错误,如下。
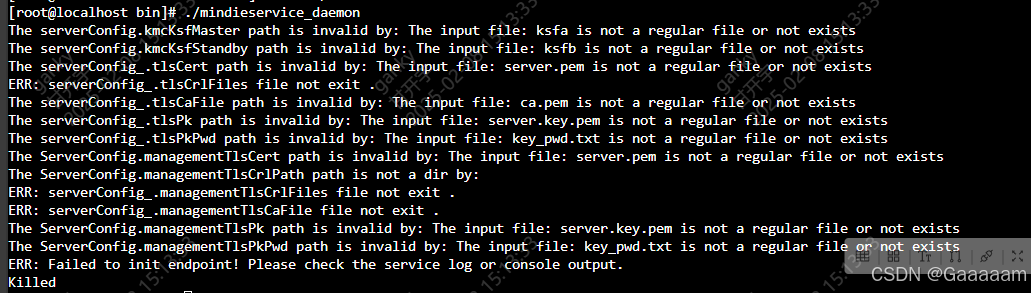
当然了,也可以补全这些认证文件(主要是一些密钥),会花费一些时间,且需要根据实际的认证需求来考虑。
错误日志不打印-不会自动生成mindservice.log文件错误
在服务拉起过程中,命令行输出的日志中可能会出现关于日志记录的错误,如下。显示Unicode编码错误。不解决的话也不会影响服务的正常启动和模型的推理,但是会无法查看到生成的错误日志!
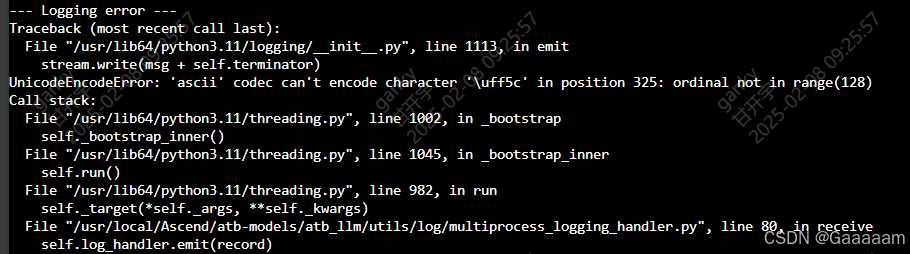
这里咨询了DS老师,按照接下来的操作对日志记录路径下的两个py文件进行小改即可解决。
/usr/local/Ascend/atb-models/atb_llm/utils/log
第一步:修改日志流的编码 StreamHandler
1.修改SafeRotatingFileHandler的编码:
在logging.py中,修改SafeRotatingFileHandler的_open方法,显式指定编码为utf-8:
def _open(self):
"""
Override:
Open the current base file with the (original) mode and encoding.
Modify the permissions of current files.
Return the resulting stream.
"""
if os.path.exists(self.baseFilename):
file_utils.safe_chmod(self.baseFilename, MAX_OPEN_LOG_FILE_PERM)
ret = self._builtin_open(self.baseFilename, self.mode, encoding='utf-8', errors='replace')
file_utils.safe_chmod(self.baseFilename, MAX_OPEN_LOG_FILE_PERM)
return ret2.修改StreamHandler的编码:
在logging.py中,修改init_logger函数中的StreamHandler初始化代码,显式指定编码为utf-8:
if str(log_to_stdout).upper() in ["1", TRUE]:
# 添加控制台输出日志
console_formatter = ErrorCodeFormatter()
console_handle = logging.StreamHandler(stream)
console_handle.setFormatter(console_formatter)
console_handle.encoding = 'utf-8' # 显式设置编码
logger_ins.addHandler(console_handle)第二步:过滤非ASCII字符
1.在日志记录前过滤非ASCII字符:
在logging.py中,修改message_filter函数,增加对非ASCII字符的过滤:
def message_filter(msg: str):
"""
Truncate message exceeding the limit and filter special characters.
"""
if len(msg) > MAX_MSG_LEN:
msg = msg[:MAX_MSG_LEN] + '...'
for item in SPECIAL_CHARS:
msg = msg.replace(item, ' ')
msg = re.sub(r' {5,}', ' ', msg)
# 过滤非ASCII字符
msg = msg.encode('ascii', errors='ignore').decode('ascii')
return msg2.在日志记录时调用过滤函数:
在logging.py中,确保所有日志记录都经过message_filter处理:
def print_log(rank_id, logger_fn, msg, need_filter=True): # 默认启用过滤
if rank_id != 0:
return
if need_filter:
msg = message_filter(str(msg))
logger_fn(msg)第三步:修改MultiLoggingHandler的编码处理
在MultiLoggingHandler中显式设置编码:
在multiprocess_logging_handler.py中,修改MultiLoggingHandler的emit方法,确保日志记录的编码为utf-8:
def emit(self, record):
"""
Emit a record.
"""
try:
sd_record = self._format_record(record)
if isinstance(sd_record, str):
sd_record = sd_record.encode('utf-8', errors='replace').decode('utf-8')
self.send(sd_record)
except KeyboardInterrupt as err:
raise err
except ValueError:
self.handleError(record)经过以上修改后,再次启动服务,在路径下应该就有mindservice.log日志文件了。
5 测试服务
服务启动后,可以通过文章的调用方式进行测试,也可以参考昇腾社区的文档多测试一下(TGI/vLLM/OpenAI/Triton/MindIE原生接口)。请在容器外/退出容器/另起一个命令行窗口进行测试。
文档链接:使用兼容OpenAI接口-接口调用-快速开始-MindIE Service开发指南-服务化集成部署-MindIE1.0.0开发文档-昇腾社区
注意:如果使用昇腾社区提供的推理接口命令测试,由于关闭了tls https认证,那么需要去除命令中的下述部分(用于认证的参数),并将最后的https请求改为http。
--cacert ca.pem --cert client.pem --key client.key.pem
OpenAI请求样例:
curl -H "Accept: application/json" -H "Content-type: application/json" -X POST -d '{
"model": <your-model-name, same as modelName in config.json>,
"messages": [{
"role": "system",
"content": "You are a helpful assistant."
}],
"max_tokens": 20,
"presence_penalty": 1.03,
"frequency_penalty": 1.0,
"seed": null,
"temperature": 0.5,
"top_p": 0.95,
"stream": false
}' http://${host}:${port}/v1/chat/completions6 待解决:可能是NPU间的通信问题?(已解决)
我部署的服务器中一共是两张NPU,4个Device,在部署过程中,我将config.json文件中调整npuDeviceIds为[[0,1,2,3]],worldSize为4;服务化部署正常拉起,但是发起请求则会报错,如下图。但是如果调整npuDeviceIds为[[0,1]],worldSize为2,即在同一张NPU上启动服务,再请求推理是ok的。没有能达到文章中的同样的效果("npuDeviceIds" : [[0,1,2,3]],"worldSize" : 4)。感觉可能是NPU通信的问题,或者哪里配置错了。
目前还在寻找解决方案。
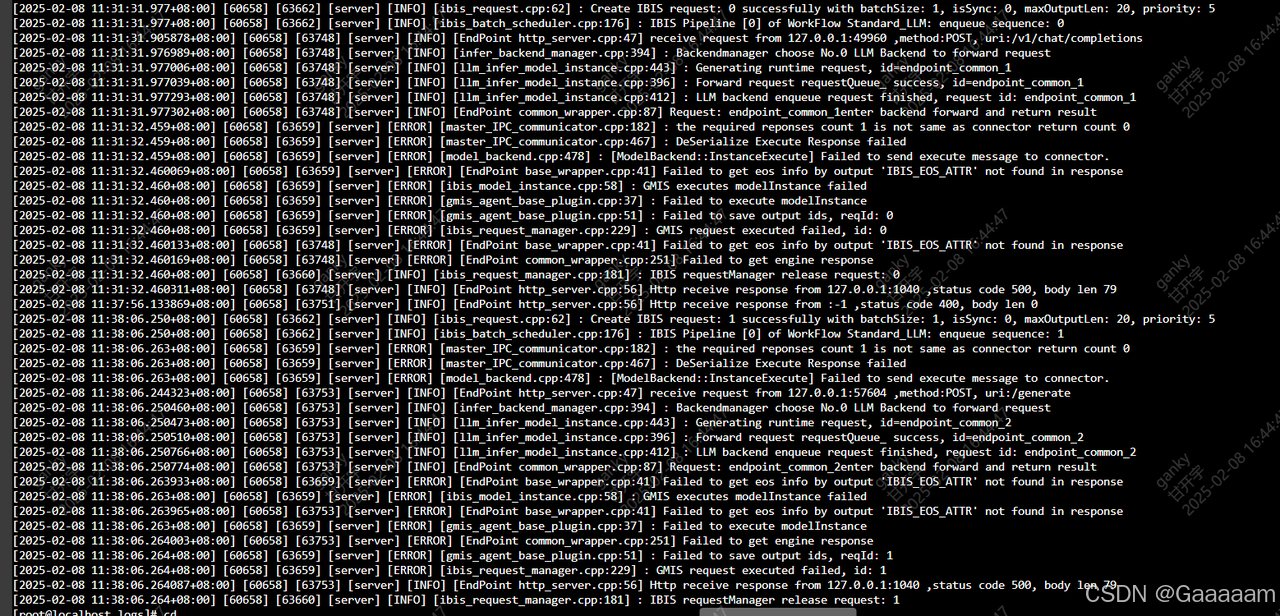
-------------------------------------------------更新线-------------------------------------------------
解决方案
咨询了华为的技术人员后,问题原因可能在于机器安装的驱动版本太老了,这里机器上原本安装的是23.0.1版本的驱动。在卸载了旧版的驱动和固件后,再安装新驱动和固件就可以在多卡部署服务之后进行服务调用了。这里新驱动版本:24.1.0.1。
注意:商用的安装包的下载是需要具备有下载权限的华为账号的,包下载请联系具有权限账户的人员或咨询华为的技术人员获得支持。
下载地址:华为 Ascend HDK 软件下载和补丁升级-华为
选择对应的驱动版本,下载driver、firmware和mcu三个包。
新安装的驱动和固件包名:
Ascend-hdk-310p-npu-driver_24.1.0.1_linux-aarch64.run
Ascend-hdk-310p-npu-firmware_7.5.0.5.220.run
其中需要确定的是驱动/固件对应的显卡型号、安装包版本、适配的系统架构,否则下载下后安装也会报错。
驱动和固件安装指导:物理机安装与卸载 - Atlas 中心推理卡 24.1.0 NPU驱动和固件安装指南 02 - 华为
安装新驱动后成功部署:

发起请求可以成功调用:
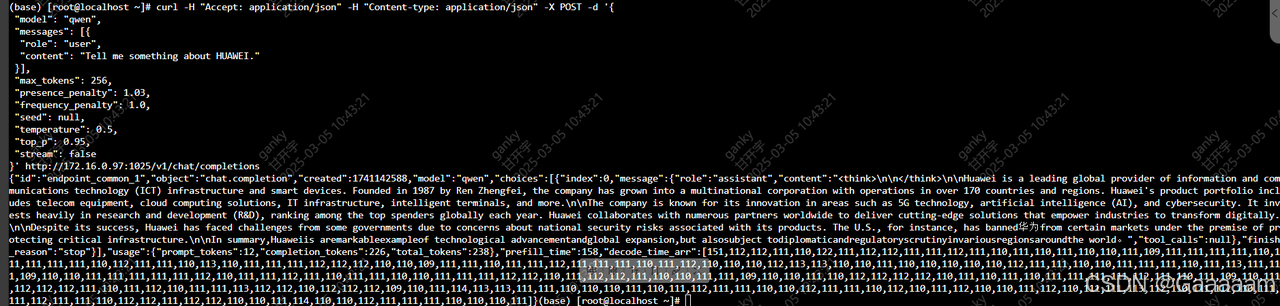

















 954
954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









