







部署目标
将向量化模型和重排序模型部署在昇腾卡上(800I A2-910b),以接口的形式以供调用。
部署模型
向量化模型:nlp_gte_sentence-embedding_chinese-base
重排序模型:bce-reranker-base_v1
如果想部署其他向量化/重排序/文本分类/系数嵌入模型,请优先参考mis-tei镜像是否支持,其次参考TEI开源项目仓库是否支持。
Github仓库地址:huggingface/text-embeddings-inference at f0e491a290385ef06f0871d188b21c0308ba86d6
step1 获取mis-tei镜像
华为官方提供了基于huggingface的Text Embeddings Inference仓库适配昇腾显卡的镜像。
获取地址:mis-tei
镜像链接中所支持的模型按照链接的方法部署即可,不过也可以使用下面提到的方式进行部署。
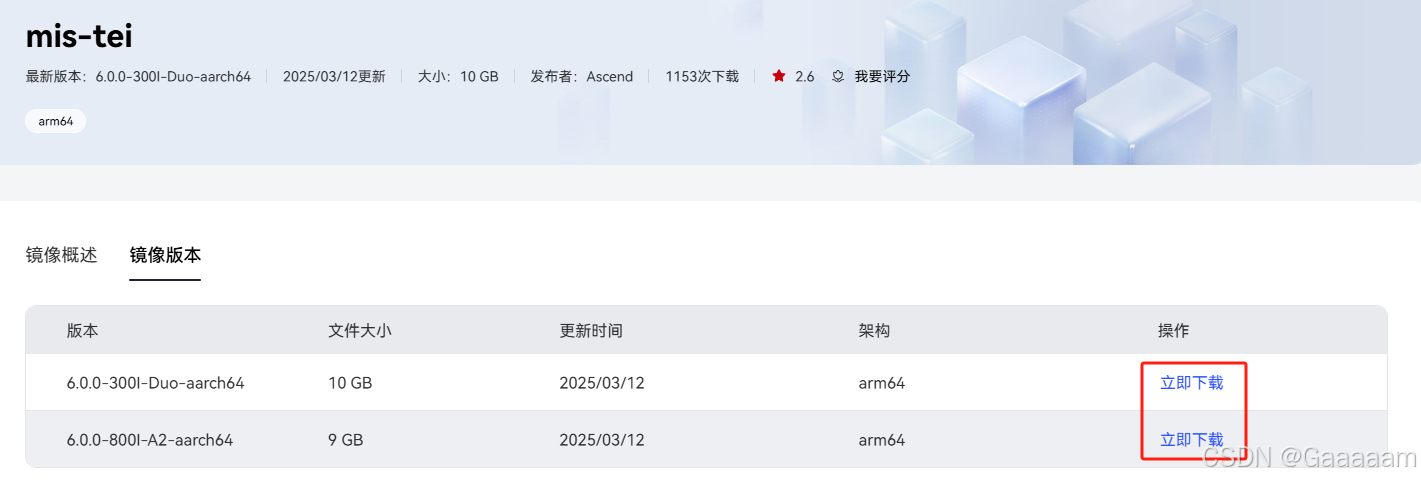
按照图中步骤进行下载即可

step2 启动容器
启动方式说明:镜像地址中说明的启动方法为启动容器的同时也启动容器,这里我选择先启动容器,进入容器后再启动服务,在一个容器中部署上述两个模型。
docker run -it -d --net=host --shm-size=2g \
--privileged \
--name <container-name> \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device=/dev/devmm_svm \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro \
-v /usr/local/sbin:/usr/local/sbin:ro \
-v <path-to-model>:<path-to-model> \
--entrypoint bash \
<image id>注意:
- 指定容器名称<container-name>
- 指定挂载的模型权重所在路径<path-to-model>
- 指定与容器的交互方式:一定要通过指定entrypoint为bash的形式启动容器,否则与容器交互的方式默认为需要输入<model id>、<listen id>和<listen port>三个参数来启动容器并启动容器中的服务
可能出现的问题
如果启动容器时命令中没有指定user为root,那么会默认user为HwHiAiUser,那么后续如果再启动非root用户的容器,可能会出现容器内无法访问显卡设备的情况(输入npu-smi info无法查看到设备信息)。推测的原因在于当前在启动的容器时,docker run命令中的参数device将设备都暴露给当前容器独占了,导致设备对其他非root权限的容器不可见或无法访问?(可能解释的不太专业,有专业的大佬可以评论区解释一下)
step3 进入容器
docker exec -it <container-name> bash复制start.sh启动脚本为两份启动脚本:embed_start.sh和rerank_start.sh。
step4 修改启动脚本
修改两份脚本中第14行和第16行的MODEL_DIR和SUPPORT_MODELS,确保两个参数值拼起来的路径能访问到模型权重。如果觉得启动脚本每次需要输入<model id>、<listen id>和<listen port>三个参数,可以注释掉4-7行代码,将这三个参数写死。
#!/bin/bash
# Copyright © Huawei Technologies Co., Ltd. 2024. All rights reserved.
if [[ "$#" -ne 3 ]]; then
echo "Need param: <model_id> <listen_ip> <listen_port>"
exit 1
fi
MODEL_ID=$1
LISTEN_IP=$2
LISTEN_PORT=$3
MODEL_NAME=$(echo ${MODEL_ID} | cut -d'/' -f2)
MODEL_DIR="/path/to/model"
MODEL_MEMORY_LIMIT=16000
SUPPORT_MODELS=("model name")step5 启动服务
nohup ./embed_start.sh nlp_gte_sentence-embedding_chinese-base 127.0.0.1 8081 > embed.log 2>&1 &
nohup ./rerank_start.sh bce-reranker-base_v1 127.0.0.1 8082 > rerank.log 2>&1 &注意:这里是两个服务启动,暴露出的端口号需要是不一样的。
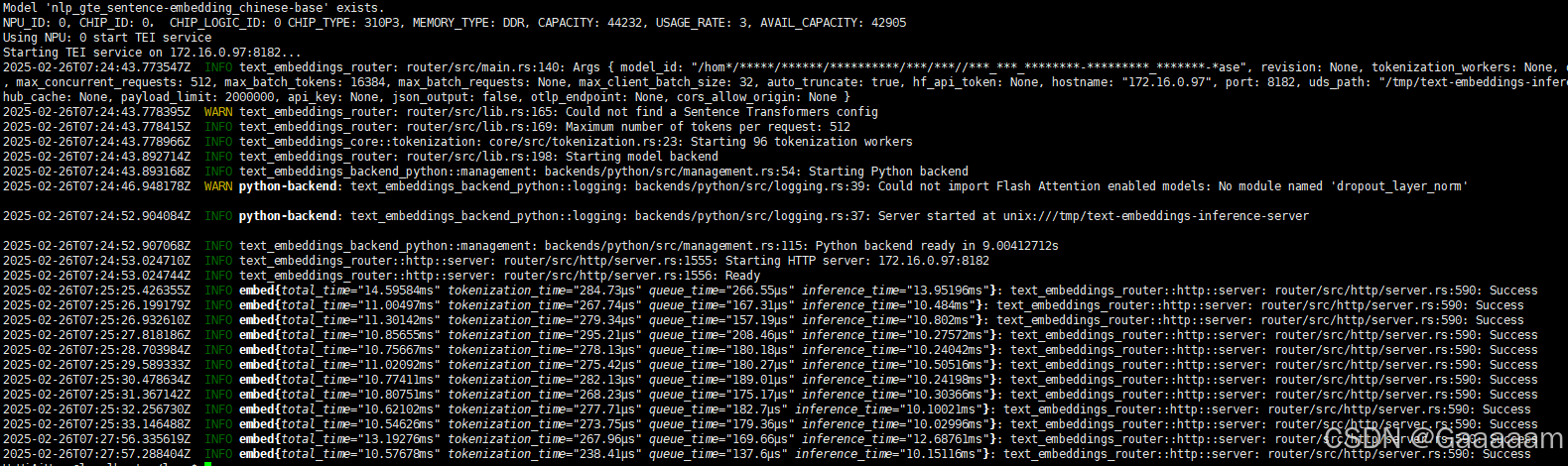
服务正常启动,调用输出
embeddings
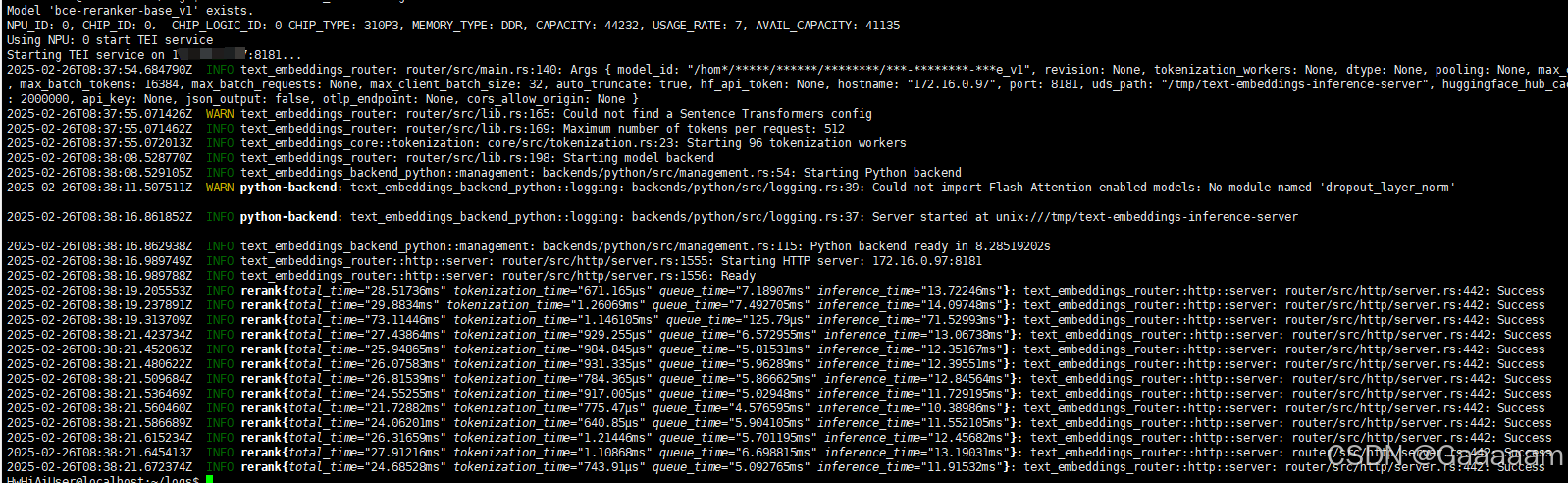
rerank
报错
部署nlp_gte_sentence-embedding_chinese-base向量化模型出现报错
缺少1_Pooling/config.json文件

TEI产生报错源码地址:
text-embeddings-inference/router/src/lib.rs at f0e491a290385ef06f0871d188b21c0308ba86d6 · huggingface/text-embeddings-inference https://github.com/huggingface/text-embeddings-inference/blob/f0e491a290385ef06f0871d188b21c0308ba86d6/router/src/lib.rs#L382
https://github.com/huggingface/text-embeddings-inference/blob/f0e491a290385ef06f0871d188b21c0308ba86d6/router/src/lib.rs#L382
官方源码截图(v1.6.0):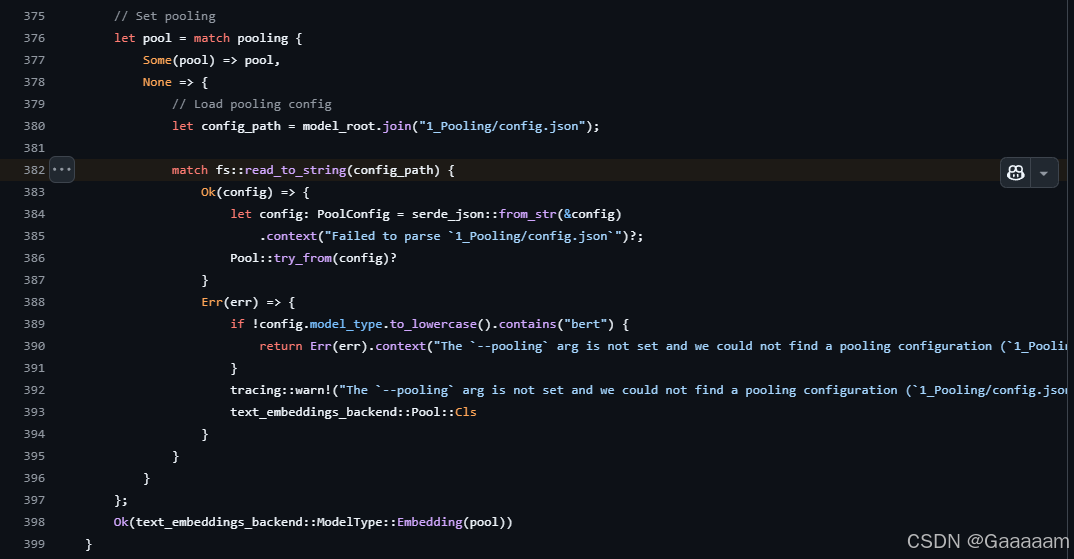
华为昇腾mis-tei镜像中源码截图(v1.2.3):
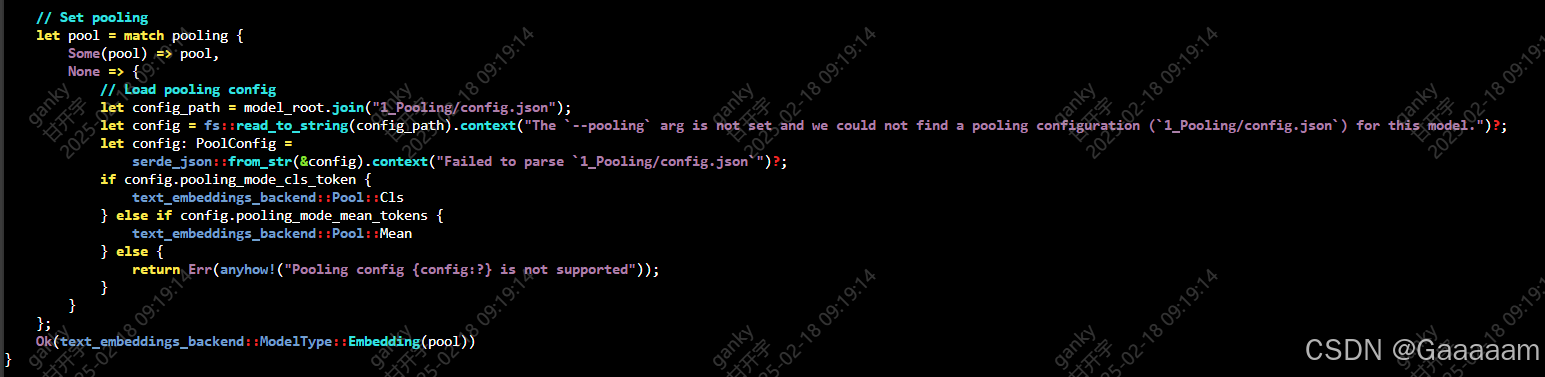
对比两部分的源码发现略有不同,先把1_Pooling文件夹和config.json文件补充到模型权重路径下。
查看nlp_gte_sentence-embedding_chinese-base模型权重下的config.json文件,发现其隐层大小为768维:

此处copy一下huggingface中bce-embedding-base_v1模型的1_Pooling/config.json文件(词嵌入维度一样,保证了输入到池化层的每个 token 的向量长度为 768)。
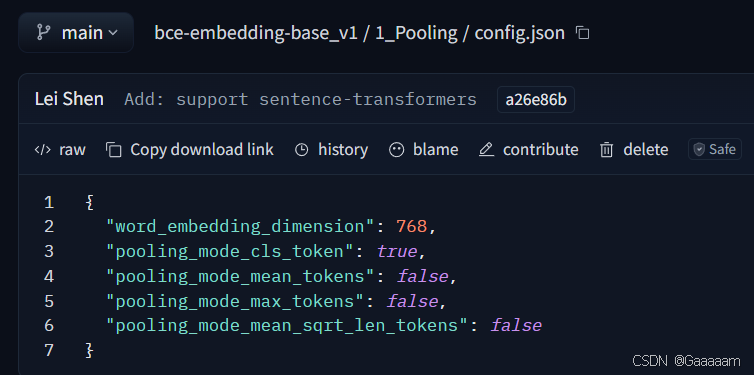
这里选用的池化模式是CLS,即使用输入序列的第一个 token(通常是 [CLS])的向量作为池化层的输出。[CLS] 是 BERT 等模型中用于表示整个序列的向量,而bce-embedding-base_v1和nlp_gte_sentence-embedding_chinese-base同属BERT系列的模型。
{
"word_embedding_dimension": 768,
"pooling_mode_cls_token": true,
"pooling_mode_mean_tokens": false,
"pooling_mode_max_tokens": false,
"pooling_mode_mean_sqrt_len_tokens": false
}创建好文件夹和配置文件后,再以上述的方式启动服务,应该就不会出现报错了。
原因:TEI版本不一致
由于华为官方提供的mis-tei镜像中的tei版本为1.2.3,落后于hf官方版本1.6.0,所以一些模型的部署会出现未适配导致的报错,比如我在该镜像下尝试部署重排序模型:gte-multilingual-reranker-base,也会报错(id2label相关错误),不过GTE系列的模型在TEI官方仓库下显示已经支持。目前除了自己在部署目标的模型时硬皮头修bug之外,只能等华为官方更新镜像了。

















 1486
1486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









