






文章目录
1、Xinference介绍
Xinference是一个性能强大且功能全面的分布式推理框架,专为大规模模型推理任务设计。它支持大语言模型(LLM)、多模态模型、语音识别模型等多种模型的推理,极大地简化了大模型部署和推理过程。
主要特点
- 一键部署:Xinference极大简化了大语言模型、多模态模型和语音识别模型的部署过程,用户只需一个命令即可设置和部署模型。
- 内置前沿模型:支持一键下载并部署大量前沿开源模型,如Qwen2、chatglm2等。
- 异构硬件支持:可以利用CPU、GPU和FPGA进行推理,提升集群吞吐量和降低延迟。
- 灵活的API:提供包括RPC和RESTful API在内的多种接口,兼容OpenAI协议,方便与现有系统集成。
- 分布式架构:支持跨设备和跨服务器的分布式部署,允许高并发推理,并简化扩容和缩容操作。
- 第三方集成:与LangChain等流行库无缝对接,快速构建基于AI的应用程序。
2、Xinference安装
本篇文章安装环境:
- Linux Ubuntu16.04
- CUDA11.2
- Driver Version: 450.142.00
2.1 Xinference Docker安装
Nvidia GPU 用户可以使用 Xinference Docker Image 安装和启动 Xinference 服务。在执行安装命令之前,请确保您的系统上已经安装了 Docker 和 CUDA。
docker run --name xinference -d -p 9997:9997 -e XINFERENCE_HOME=/data -v </on/your/host>:/data --gpus all xprobe/xinference:latest xinference-local -H 0.0.0.0
其中</on/your/host>填写服务器中的目录,-v表示将服务器上的目录挂载到容器中,实现数据的共享和持久化。
2.2 pip安装
首先使用以下命令来创建 3.11 的 Python 环境:
conda create --name xinference python=3.11
conda activate xinference
以下两条命令在安装 Xinference 时,将安装 Transformers 和 vLLM 作为 Xinference 的推理引擎后端:
pip install "xinference[transformers]"
pip install "xinference[vllm]"
pip install "xinference[transformers,vllm]" # 同时安装
PyPi 在 安装 Transformers 和 vLLM 时会自动安装 PyTorch,但自动安装的 CUDA 版本可能与你的环境不匹配,此时你可以先安装指定版本的torch+cuda:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
只需要输入如下命令,就可以在服务上启动 Xinference 服务:
xinference-local -H 0.0.0.0
Xinference 默认会在本地启动服务,端口默认为 9997。因为这里配置了-H 0.0.0.0参数,其他电脑可以通过服务器的 IP 地址来访问 Xinference 服务。
接着访问服务器公网地址加上9997端口,即可进入Xinference服务界面。
2.3 设置开启自启动(仅针对pip安装用户)
1、创建xinference.sh文件
sudo vim /etc/systemd/system/xinference.service
2、在文件中添加以下内容
[Unit]
Description=Xinference Service
After=network.target
[Service]
Type=simple
ExecStart=/bin/bash -c 'source activate && conda activate xinference && xinference-local --host 0.0.0.0 --port 9997'
Restart=always
[Install]
WantedBy=multi-user.target
注意:其中source activate用于激活base环境,如果设置了开机自动激活base环境则不需要这条命令。
3、启用并启动服务
sudo systemctl daemon-reload
sudo systemctl enable xinference.service
sudo systemctl start xinference.service
尽管设置了Xinference开机自启动,但是下载的模型仍然要进入服务界面重新启动。
3、部署Embedding和Rerank模型
进入Xinference服务界面,依次点击Launch Model->EMBEDDING MODELS->搜索模型或在下方选择。
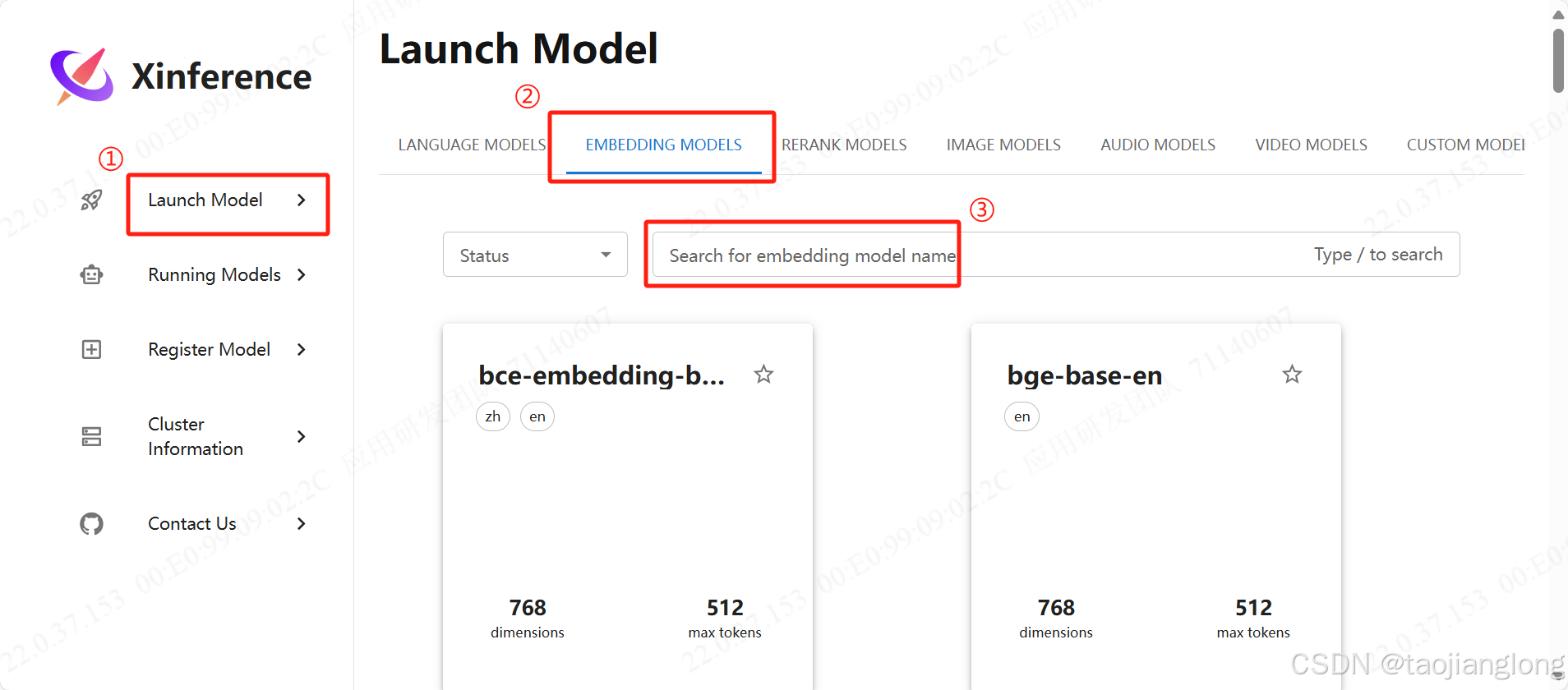
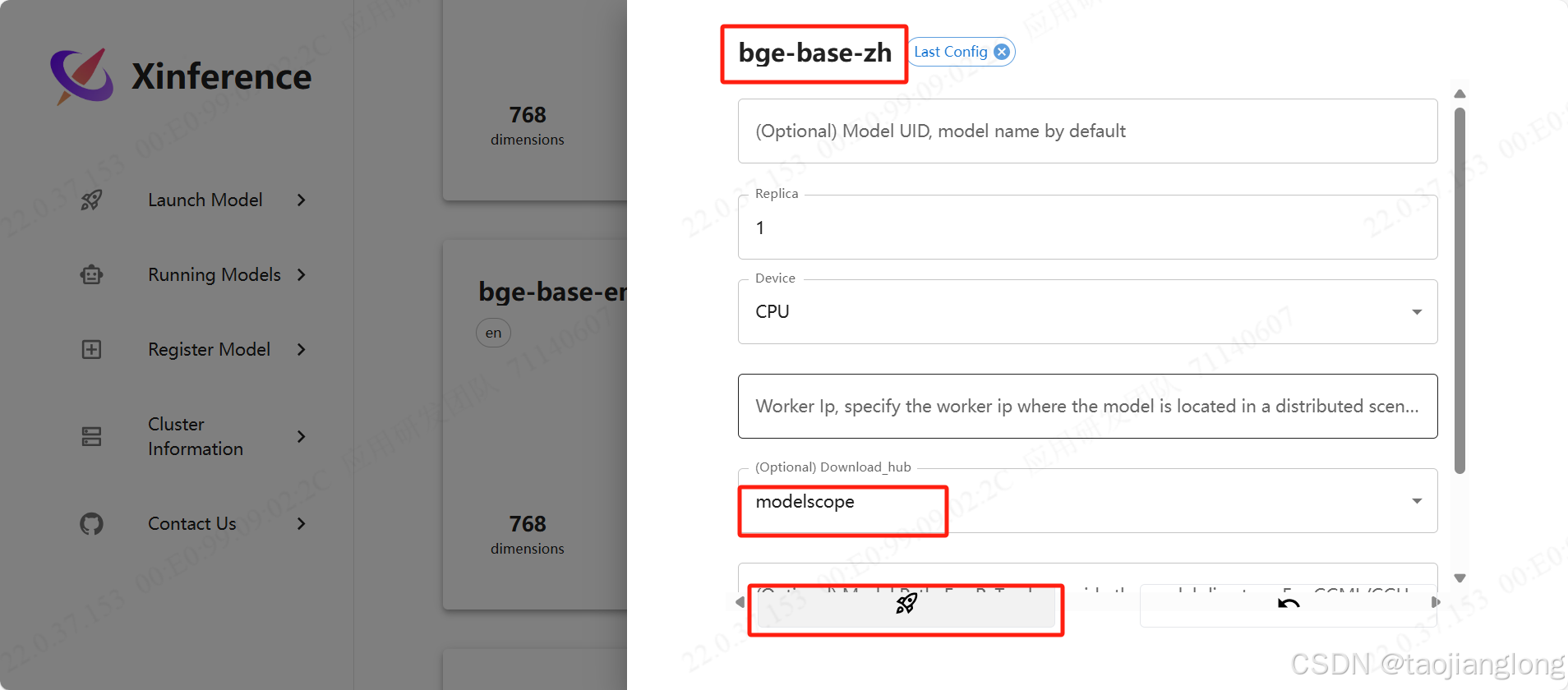
此处以bge-base-zh为例,填写模型名称->选择下载源(国内用户建议选择modelscope)->点击火箭按钮进行下载和启动模型。下载进度可以在服务器Shell终端查看。
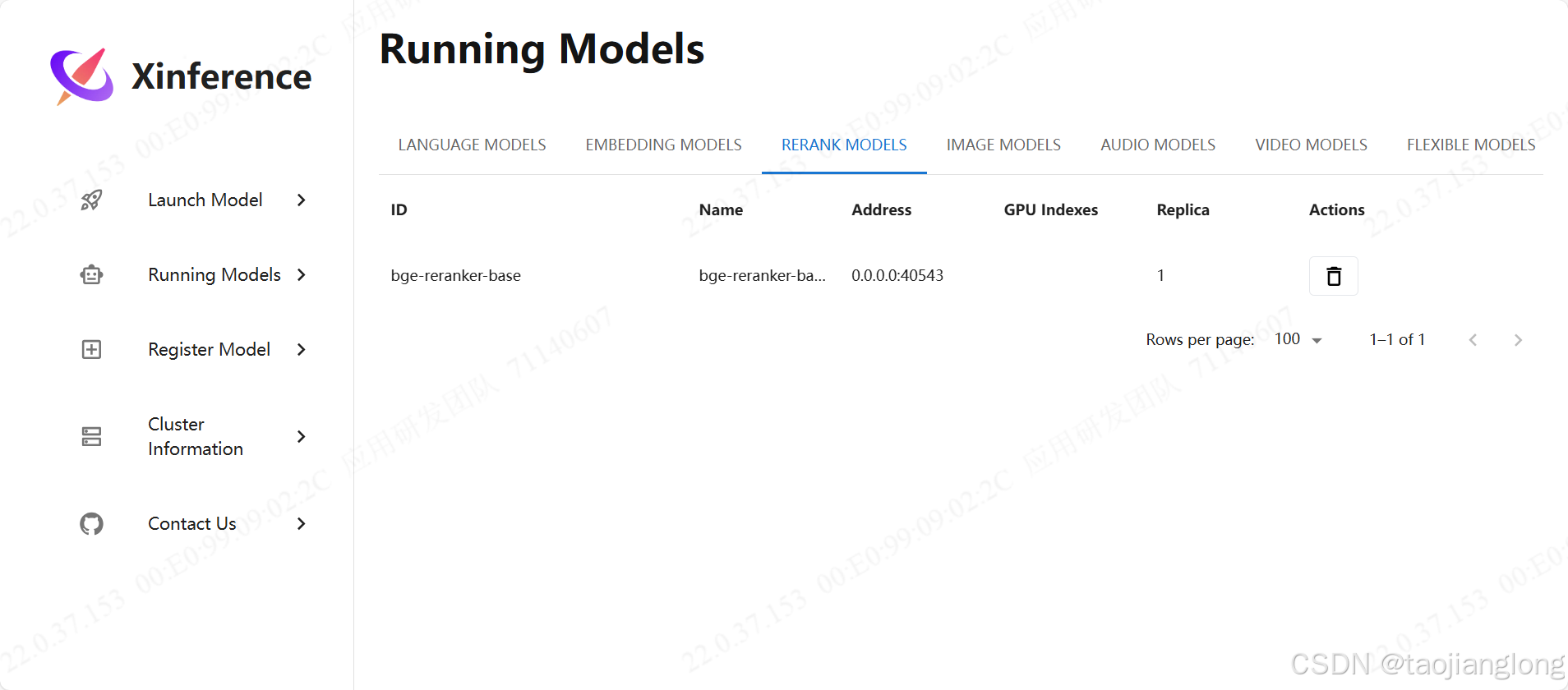
模型成功启动后可以点击Running Models->EMBEDDING MODELS查看。
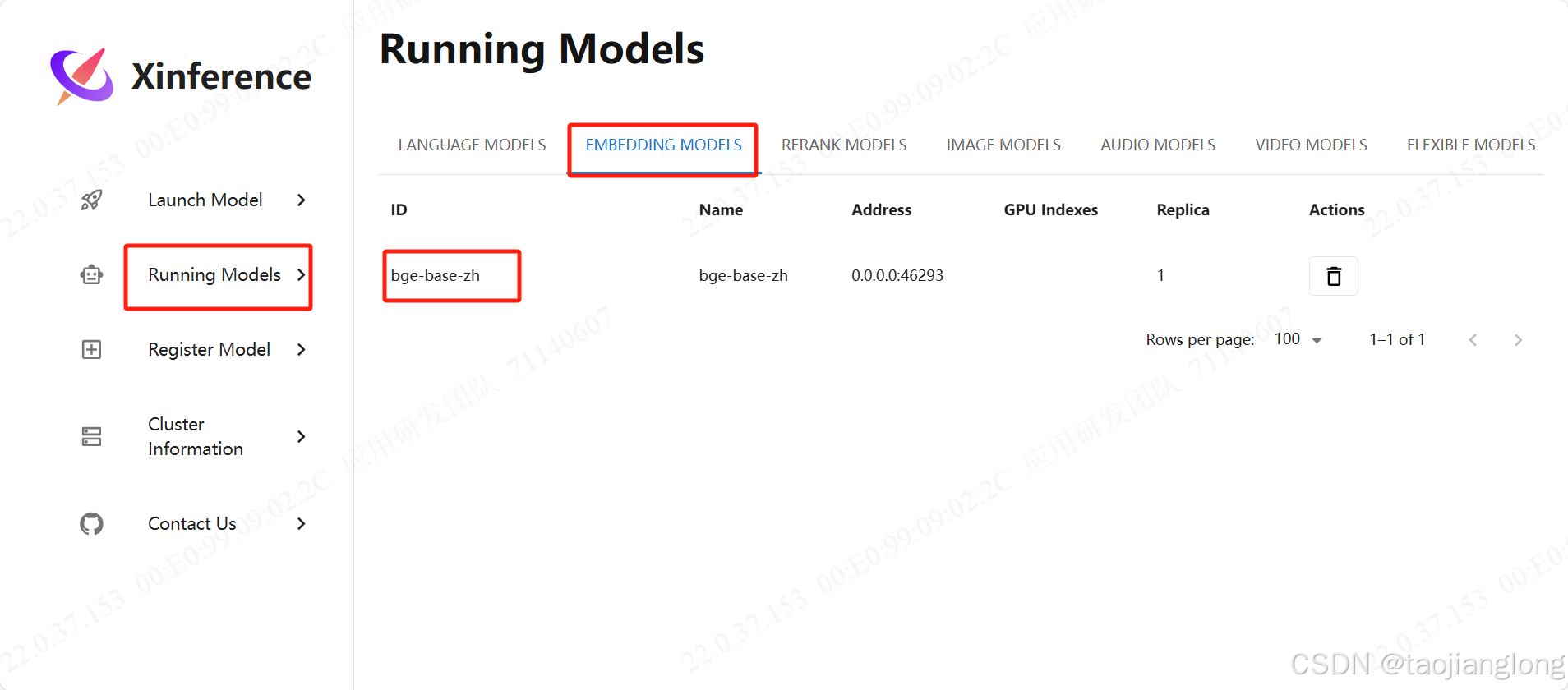
Xinference下载的模型默认保存位置为/home/user_name/.cache/modelscope/hub/Xorbits/。
Rerank模型的下载和启动方式与Embedding模型一直,此处不再赘述。
注意:Xinference只能同时启动一个语音模型、图片模型、语音模型,但是可以同时启动多个嵌入模型、重排模型。
4、Dify调用Xinference模型
进入Dify服务界面,依次点击右上角用户->设置->模型供应商,选择Xorbits inference->选择Text Embedding-> 填写模型名称、服务器URL、模型UID,点击保存即可。
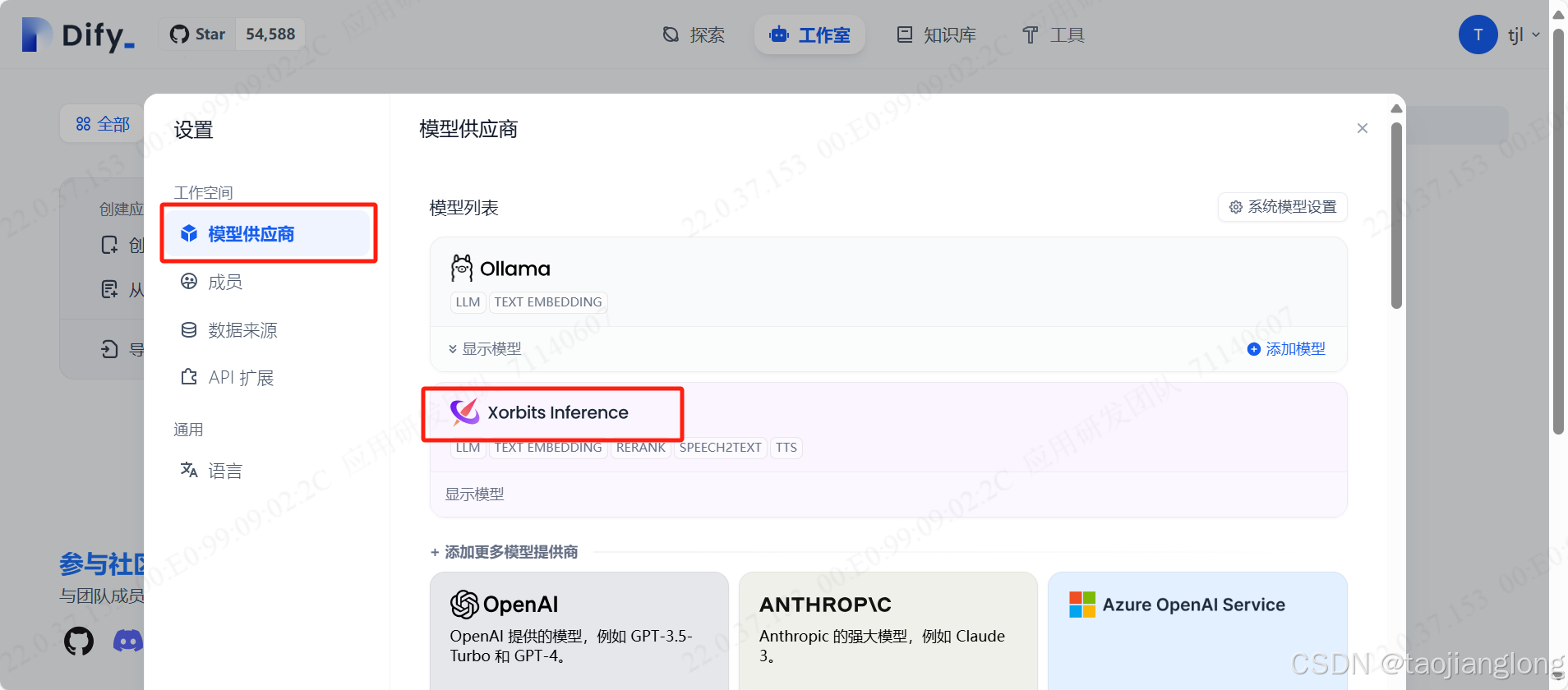
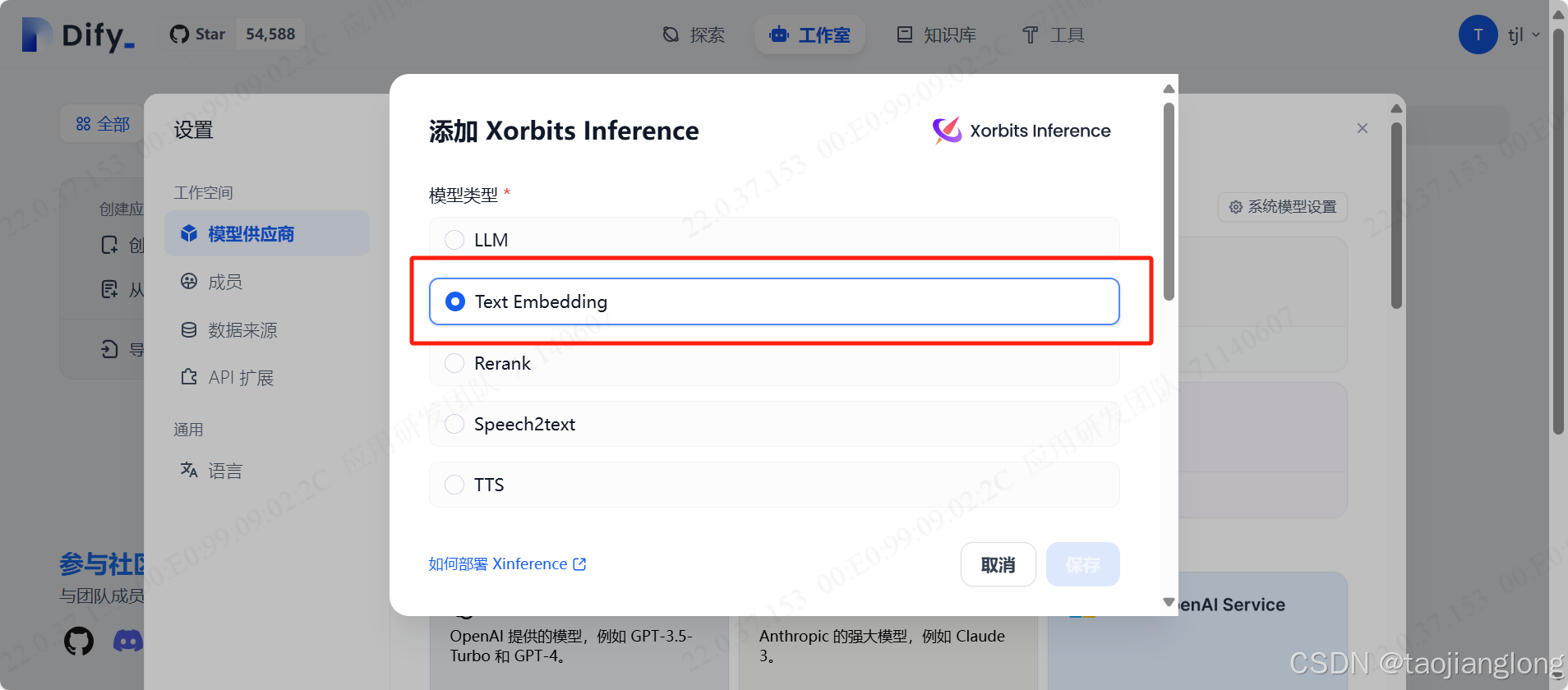
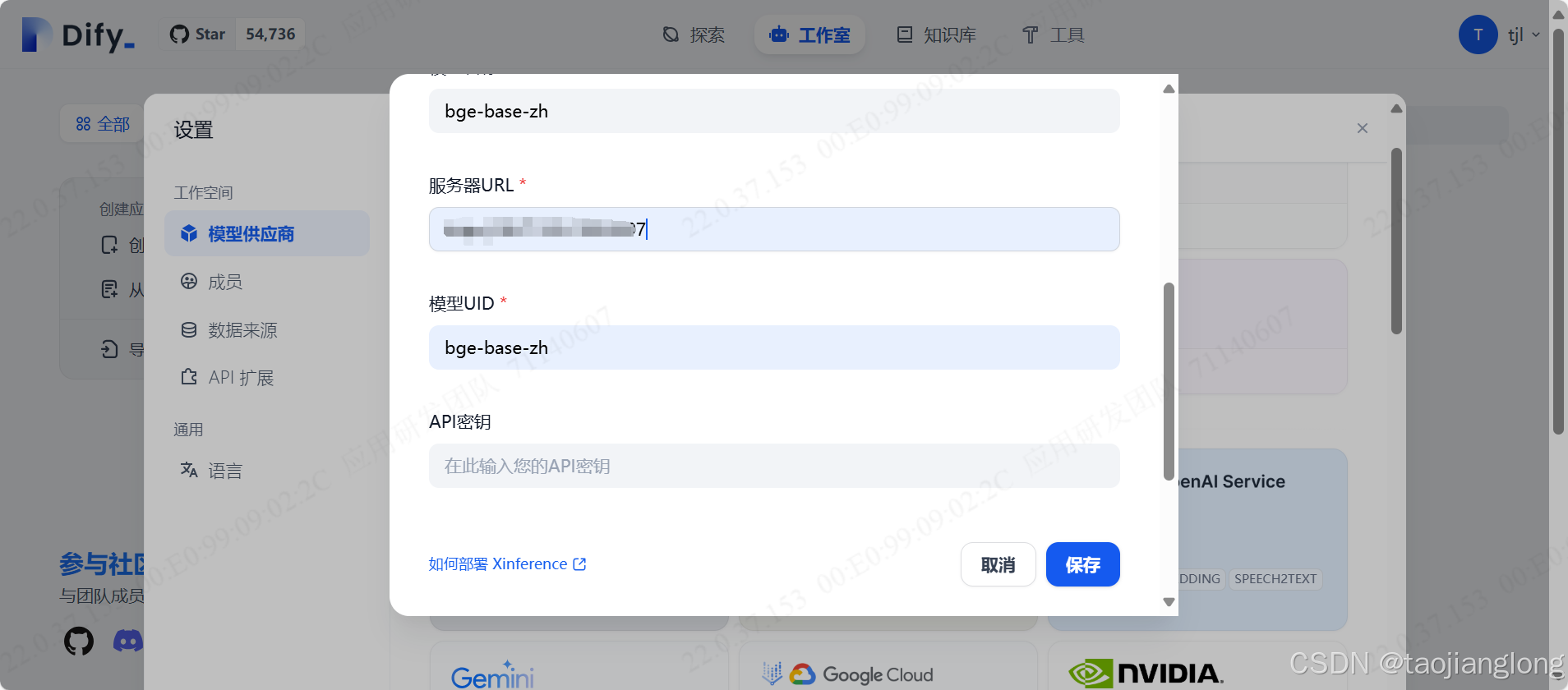
注意:模型名称要和Xinference里的保持一致。
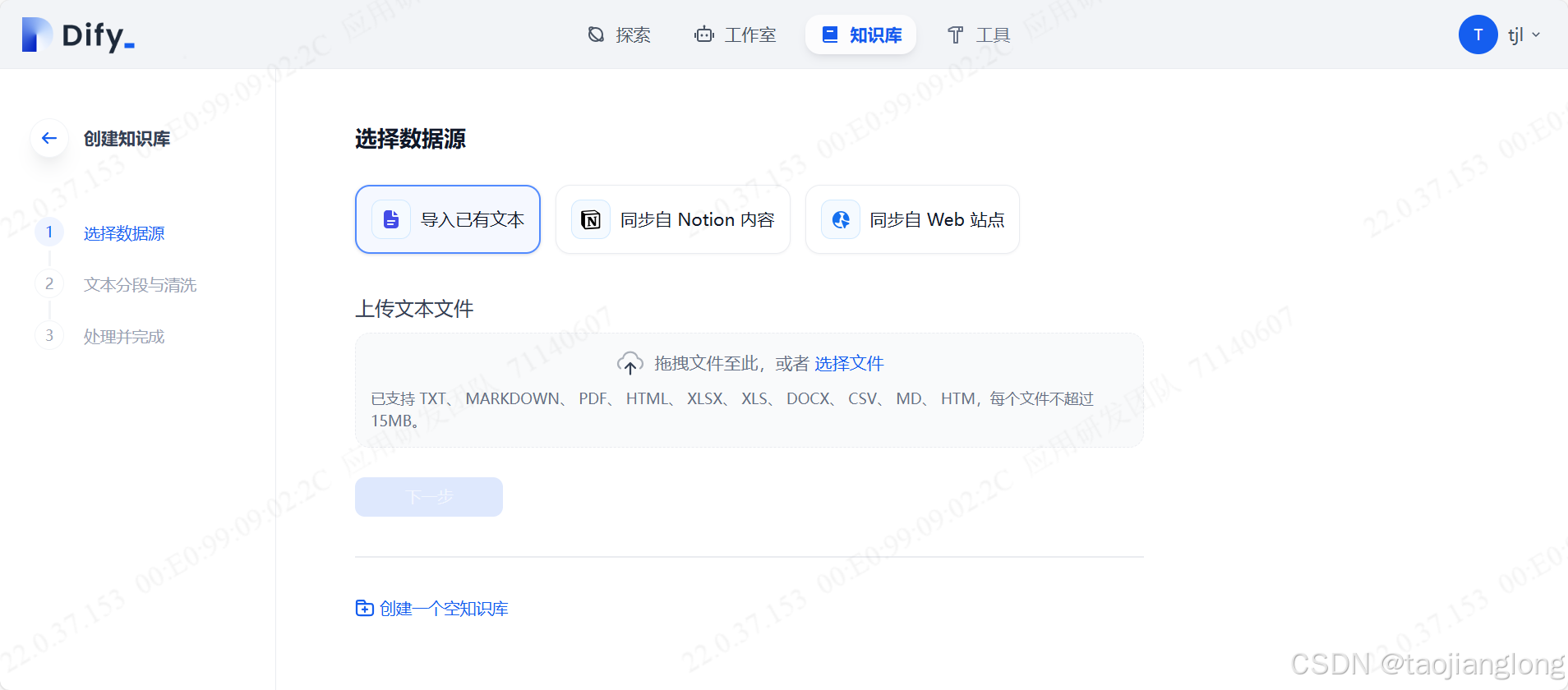
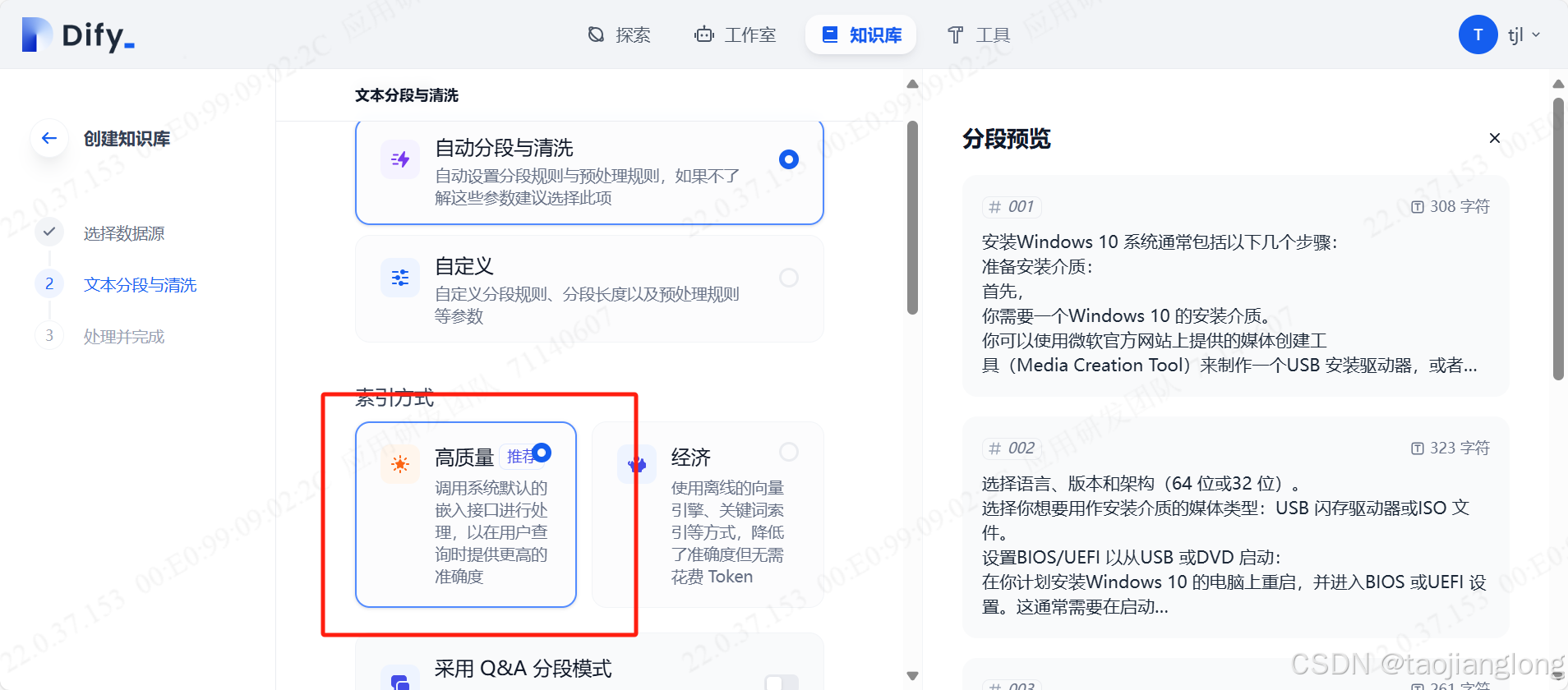
接下来可以在Dify知识库中使用Embedding和Rerank模型,点击知识库、创建知识库、选择数据源、选择高质量索引方式、选择Embedding模型和开启Rerank模型,保存并处理。
注意:只有选择高质量索引方式,才能使用Embedding和Rerank模型。
之后在聊天助手界面即可选择刚刚创建的知识库,实现RAG对话。



















 6886
6886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









