







1. 原型聚类
原型聚类也称为“基于原型的聚类” (prototype-based clustering),此类算法假设聚类结构能通过一
组原型刻画。算法过程:通常情况下,算法先对原型进行初始化,再对原型进行迭代更新求解。著
名的原型聚类算法:k均值算法、学习向量量化算法、高斯混合聚类算法。
给定数据集![]() ,k均值算法针对聚类所得簇划分
,k均值算法针对聚类所得簇划分![]() ,最
,最
小化平方误差:![]()
其中,![]() 是簇
是簇![]() 的均值向量。值在一定程度上刻画了簇内样本围绕簇均值向量的紧密程度,值越
的均值向量。值在一定程度上刻画了簇内样本围绕簇均值向量的紧密程度,值越
小,则簇内样本相似度越高。
1.1 K均值
K均值算法:算法流程(迭代优化):初始化每个簇的均值向量,repeat:(更新)簇划分;计算
每个簇的均值向量,until:当前均值向量均未更新。
算法伪代码:

k均值算法实例:
接下来以表9-1的西瓜数据集4.0为例,来演示k均值算法的学习过程。将编号为i的样本称为![]()
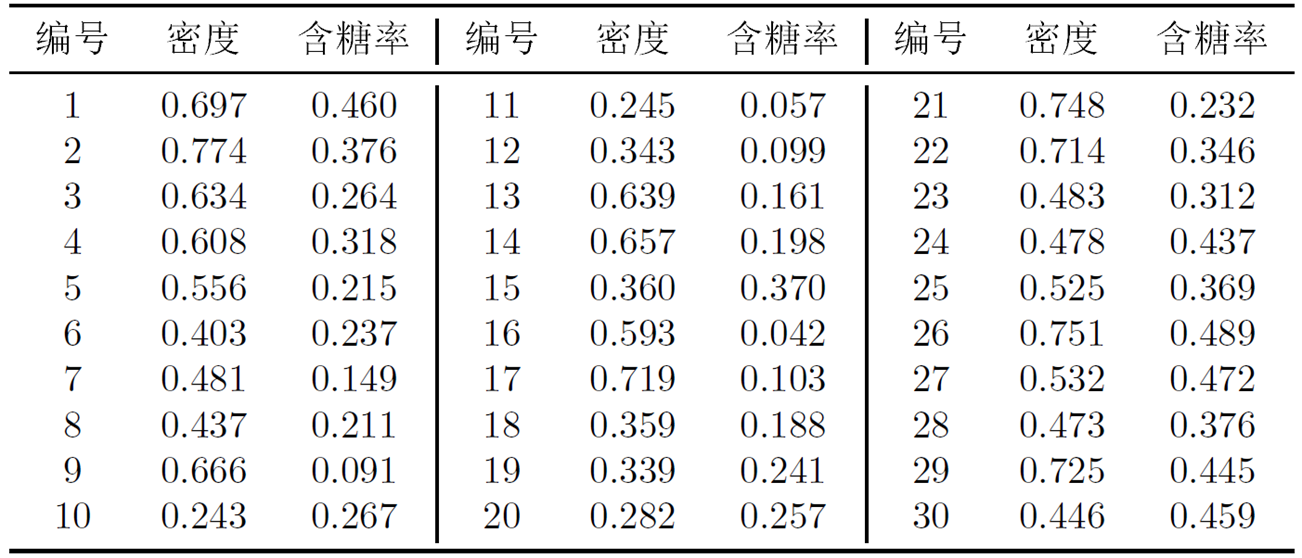
假定聚类簇数k =3,算法开始时,随机选择3个样本![]() 作为初始均值向量,即
作为初始均值向量,即
![]()
考察样本
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











