







StarRocks 是一个强大的数据分析系统,主要宗旨是为用户提供极速、统一并且易用的数据分析能力,以帮助用户通过更小的使用成本来更快的洞察数据的价值。通过精简的架构、高效的向量化引擎以及全新设计的基于成本的优化器(CBO),StarRocks 的分析性能(尤其是多表 JOIN 查询)得以远超同类产品。
为了能够满足更多用户对于极速分析数据的需求,同时让 StarRocks 强大的分析能力应用在更加广泛的数据集上,阿里云开源大数据 OLAP 团队联合社区一起增强 StarRocks的数据湖分析能力。使其不仅能够分析存储在 StarRocks 本地的数据,还能够以同样出色的表现分析存储在 Apache Hive、Apache Iceberg 和 Apache Hudi 等开源数据湖或数据仓库的数据。
本文将重点介绍 StarRocks 极速数据湖分析能力背后的技术内幕,性能表现以及未来的规划。
一、整体架构

在数据湖分析的场景中,StarRocks 主要负责数据的计算分析,而数据湖则主要负责数据的存储、组织和维护。上图描绘了由 StarRocks 和数据湖所构成的完成的技术栈。
StarRocks 的架构非常简洁,整个系统的核心只有 FE(Frontend)、BE(Backend)两类进程,不依赖任何外部组件,方便部署与维护。其中 FE 主要负责解析查询语句(SQL),优化查询以及查询的调度,而 BE 则主要负责从数据湖中读取数据,并完成一系列的 Filter 和 Aggregate 等操作。
数据湖本身是一类技术概念的集合,常见的数据湖通常包含 Table Format、File Format 和 Storage 三大模块。其中 Table Format 是数据湖的“UI”,其主要作用是组织结构化、半结构化,甚至是非结构化的数据,使其得以存储在像 HDFS 这样的分布式文件系统或者像 OSS 和 S3 这样的对象存储中,并且对外暴露表结构的相关语义。Table Format 包含两大流派,一种是将元数据组织成一系列文件,并同实际数据一同存储在分布式文件系统或对象存储中,例如 Apache Iceberg、Apache Hudi 和 Delta Lake 都属于这种方式;还有一种是使用定制的 metadata service 来单独存放元数据,例如 StarRocks 本地表,Snowflake 和 Apache Hive 都是这种方式。
File Format 的主要作用是给数据单元提供一种便于高效检索和高效压缩的表达方式,目前常见的开源文件格式有列式的 Apache Parquet 和 Apache ORC,行式的 Apache Avro 等。
Storage 是数据湖存储数据的模块,目前数据湖最常使用的 Storage 主要是分布式文件系统 HDFS,对象存储 OSS 和 S3 等。
FE
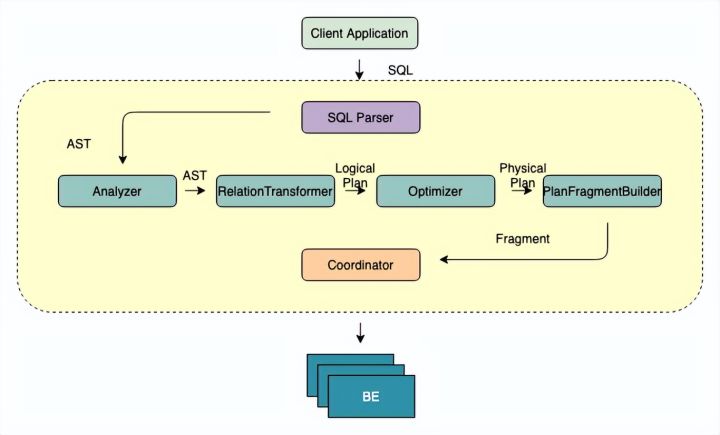
FE 的主要作用将 SQL 语句转换成 BE 能够认识的 Fragment,如果把 BE 集群当成一个分布式的线程池的话,那么 Fragment 就是线程池中的 Task。从 SQL 文本到分布式物理执行计划,FE 的主要工作需要经过以下几个步骤:
- SQL Parse: 将 SQL 文本转换成一个 AST(抽象语法树)
- SQL Analyze:基于 AST 进行语法和语义分析
- SQL Logical Plan: 将 AST 转换成逻辑计划
- SQL Optimize:基于关系代数,统计信息,Cost 模型对 逻辑计划进行重写,转换,选择出 Cost “最低” 的物理执行计划
- 生成 Plan Fragment:将 Optimizer 选择的物理执行计划转换为 BE 可以直接执行的 Plan Fragment。
- 执行计划的调度
BE
Backend 是 StarRocks 的后端节点,负责数据存储以及 SQL 计算执行等工作。
StarRocks 的 BE 节点都是完全对等的,FE 按照一定策略将数据分配到对应的 BE 节点。在数据导入时,数据会直接写入到 BE 节点,不会通过FE中转,BE 负责将导入数据写成对应的格式以及生成相关索引。在执行 SQL 计算时,一条 SQL 语句首先会按照具体的语义规划成逻辑执行单元,然后再按照数据的分布情况拆分成具体的物理执行单元。物理执行单元会在数据存储的节点上进行执行,这样可以避免数据的传输与拷贝,从而能够得到极致的查询性能。
二、技术细节
StarRocks 为什么这么快
CBO 优化器

一般 SQL 越复杂,Join 的表越多,数据量越大,查询优化器的意义就越大,因为不同执行方式的性能差别可能有成百上千倍。StarRocks 优化器主要基于 Cascades 和 ORCA 论文实现,并结合 StarRocks 执行器和调度器进行了深度定制,优化和创新。完整支持了 TPC-DS 99 条 SQL,实现了公共表达式复用,相关子查询重写,Lateral Join, CTE 复用,Join Rorder,Join 分布式执行策略选择,Runtime Filter 下推,低基数字典优化 等重要功能和优化。
CBO 优化器好坏的关键之一是 Cost 估计是否准确,而 Cost 估计是否准确的关键点之一是统计信息是否收集及时,准确。 StarRocks 目前支持表级别和列级别的统计信息,支持自动收集和手动收集两种方式,无论自动还是手动,都支持全量和抽样收集两种方式。
MPP 执行
MPP (massively parallel processing) 是大规模并行计算的简称,核心做法是将查询 Plan 拆分成很多可以在单个节点上执行的计算实例,然后多个节点并行执行。 每个节点不共享 CPU,内存, 磁盘资源。MPP 数据库的查询性能可以随着集群的水平扩展而不断提升。
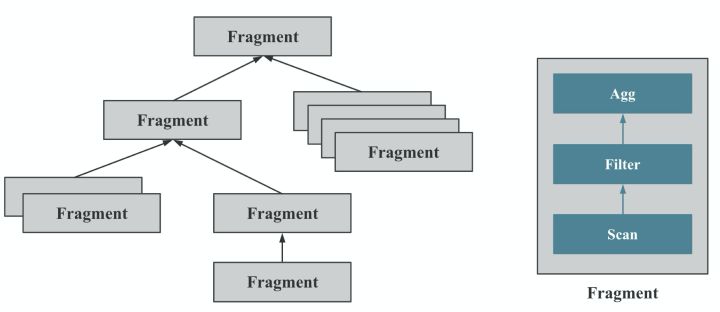
如上图所示,StarRocks 会将一个查询在逻辑上切分为多个 Query Fragment(查询片段),每个 Query Fragment 可以有一个或者多个 Fragment 执行实例,每个Fragment 执行实例 会被调度到集群某个 BE 上执行。 如上图所示,一个 Fragment 可以包括 一个 或者多个 Operator(执行算子),图中的 Fragment 包括了 Scan, Filter, Aggregate。如上图所示,每个 Fragment 可以有不同的并行度。

如上图所示,多个 Fragment 之间会以 Pipeline 的方式在内存中并行执行,而不是像批处理引擎那样 Stage By Stage 执行。
如上图所示,Shuffle (数据重分布)操作是 MPP 数据库查询性能可以随着集群的水平扩展而不断提升的关键,也是实现高基数聚合和大表 Join 的关键。
向量化执行引擎
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 577
577











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









