







PolarDB-X 2.1 新版本发布
让“MySQL 原生分布式”触手可及
——黄贵(曲山)阿里云数据首席架构师
了解更多PolarDB-X 内容:
https://developer.aliyun.com/topic/polardbx_release
PolarDB-X 2.1 是 PolarDB-X 非常重要的版本,也是第一次 PolarDB-X 分布式数据库的产品可以作为企业级的分布式数据库真正部署到客户的生产环境使用。
一、一个好的MySQL分布式数据库应该是什么样的

C++语言设计的概念 Zero Overhead Abstraction ——0负担抽象原则,它有两个重要特性:
- 无须为不用的特性付出代价: C 类用户升级到 C++ 时,如果不使用 C++里的高级特性,则无须为这些特性付出额外的代价。比如在 C 里面是 structure,到 C++ 里可能是class 。对于 C 中的 structure 和 C++ 中的 class ,如果不带 virtual function ,则在内存布局的性能消耗上是等同的,不用付出额外的代价。
- 你所使用的代码,不可能手写得更好:如果想要使用更高级的特性,用 C++ 扩展的能力,一定比手写的代码更好,即C++ 提供的语言特性能够很好地帮助到用户。
C 语言的用户升级到 C++,必然是因为它带来了更新更强的能力,比如封装、抽象的能力,可以做继承、有多态。另外,C++ 提供了多种编程范式,比如面向对象、泛型编程、函数式编程等,这些特性都可以极大地拓展语言的抽象,带来能力的提升。
同理,从单机的 MySQL 数据库升级到分布式 MySQL 数据库,我们期望它能有哪些表现?
首先是完全兼容,可以由单机平滑过渡到分布式系统,无需对应用进行改造;第二,无需对数据库的结构进行改造;第三,不使用分布式能力则无须付出额外的开销。
单机到分布式最重要的变化是数据会分布在多个节点上,对于数据库中很多操作而言,尤其是事务,是需要付出一些额外代价的。如果事务涉及到多个数据的分区,而只是想将分布式系统作为单机数据库来用,同样也可以有单表的特性,无须付出分布式事务的代价。
升级到分布式系统后能够获得自动伸缩的能力,能够天然地利用分布式的特性实现跨地域的高可用,还可以处理混合的负载类型,包括事务的负载以及分析的负载,提供了高性价比的解决方案。
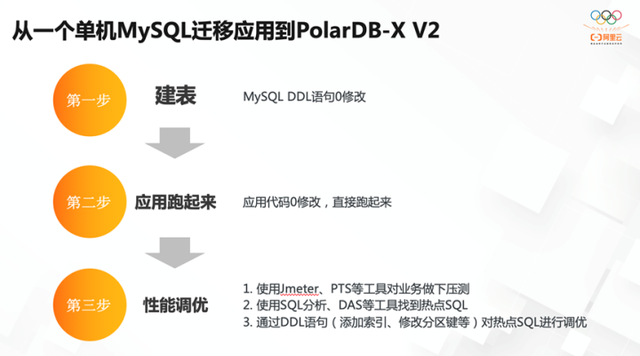
二、让分布式能力透明化
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6587
6587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









