







 在PolarDB-X 2.0的AUTO模式下,数据库会按照表的主键自动Hash分区,将数据均匀的分布到各个数据节点中,最理想的情况是各分区间数据和流量都是均衡的,能充分发挥出多节点的分布式处理能力。
在PolarDB-X 2.0的AUTO模式下,数据库会按照表的主键自动Hash分区,将数据均匀的分布到各个数据节点中,最理想的情况是各分区间数据和流量都是均衡的,能充分发挥出多节点的分布式处理能力。
背景
PolarDB-X是一款计算存储分离的分布式数据库,分布式的处理能力是PolarDB-X的核心特性之一,单个数据库实例的多个计算节点会均摊全部的SQL流量,这样就可以通过节点的扩缩容来快速满足不同的流量峰值场景。
在PolarDB-X 1.0时代,用户常常使用分库分表的方式对库表进行拆分从而达到数据和流量在多个节点间均衡,该模式下拆分键的选择对数据库的性能表现起关键性的作用,要选出最佳的拆分键组合就要求用户在建表初就对业务库的库表结构和数据分布非常熟悉。
为了帮助用户降低使用分布式数据库的技术门槛,PolarDB-X 2.0时代引入了透明分布式的理念,用户无需再逐一指定拆分键,使用分布式数据库就像使用单机MySQL一样简单,同样也能享有分布式数据库的优异特性。这既是用户体验上的一次升级,也是技术架构和理念的一次飞跃,从中间件模式进化到云原生架构,数据库不再是需要用户费心维护的高级技术组件,而是一种随用随得的云服务,让用户可以充分享受云架构带来的技术红利。
在PolarDB-X 2.0的AUTO模式下,数据库会按照表的主键自动Hash分区,将数据均匀的分布到各个数据节点中,最理想的情况就是各分区间数据和流量都是均衡的,能充分发挥出多节点的分布式处理能力。为了达到最理想的效果,就要求数据库尽量避免出现热点分区,包括流量的热点和数据量的热点。避免热点的出现,首先就需要能快速便捷地发现热点分区,从而能进行针对性的处理。因此快速准确地找出热点分区就成为PolarDB-X2.0所需的一项重要能力。
效果展示
功能概览
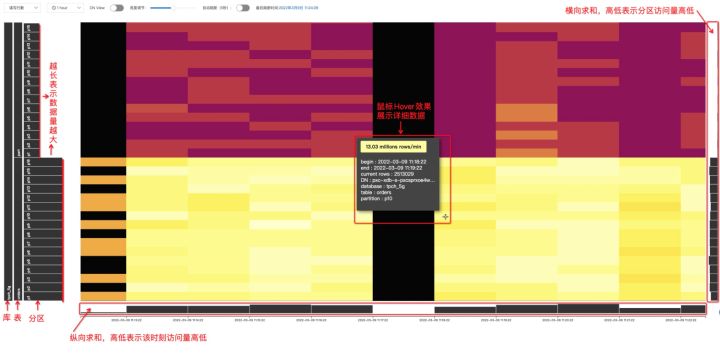
首先选取一个小范围数据做介绍,如下图,纵轴表示了逻辑库、逻辑表、逻辑分区间的关系,并且分区按照逻辑序号进行排序,横轴表示时间,图像下方和右方的柱形图表示了汇总数据,下方柱形图表示纵向的求和,即某时刻所有分区的访问量的求和,右方的柱形图表示横向的求和,即某分区所有时间范围内的访问量求和。
存储节点视角
如何想查看存储节点视角的热
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 677
677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









