







前言
数据库迁移上云是大数据时代的一大趋势,PolarDB MySQL是阿里云自研的云原生数据库,主要处理在线事务负载(OLTP, OnLine Transactional Processing),深受企业用户的青睐。当下,数据分析对于企业的重要性越发显著:企业使用数据驱动决策,利用分析结果精准调配资源,从而降低成本,提升企业效率,推动业务创新,快速适应外部环境的变化。然而,传统数仓架构的滞后性限制了企业的创新步伐。因此,企业对OLTP数据库提出更高的要求,希望能在OLTP数据库同时进行复杂的实时分析(OLAP, OnLine Analytical Processing),及时应对业务环境的高速变化。
为满足混合负载(HTAP, Hybrid Transactional/Analytical Processing)的需求,部分客户选择了MySQL + Clickhouse的方案,但困扰于着两套独立系统的高使用和高维护成本,以及系统间的数据不一致等问题。客户寻求在一套系统上完美地应对HTAP负载的解决方案。对此,PolarDB MySQL 技术团队提出了基于In-Memory Column Index(以下简称IMCI)的HTAP技术方案,在PolarDB MySQL行存支持OLTP的基础上,原生地构建列存索引以及实现列存计算引擎,支持高效地实时分析,在TPC-H测试中获得数百倍于行存的加速效果。关于PolarDB HTAP和IMCI的详细介绍参考《400倍加速, PolarDB HTAP实时数据分析技术解密》[1]。
本文介绍数据的压缩方法以及PolarDB HTAP在列存数据压缩上的工作。PolarDB MySQL作为云原生数据库,具有存储计算分离的特点,计算资源独可以进行按需分配,而存储始终固定存在且持续增长的,需要压缩对存储成本进行控制。IMCI的数据存储是为列存格式,列数据相比于行数据具有更高的相似性,利于数据压缩。通过压缩,IMCI在大部分业务场景将列存存储空间减少到十分之一,大幅减少客户的存储成本。另外IMCI通过数据压缩,减少数据的大小和存储访问开销,并探究将计算下推到压缩数据从而加速分析,进一步为客户提供更好的OLAP查询性能,实现HTAP系统性能和成本的兼得。
后文主要分为4个部分,在“数据压缩概述”部分我们从数据压缩的理论基础——信息论谈起,结合数据库中的数据压缩问题进行讨论。在“压缩算法分类和介绍”中,我们将压缩方法分为通用压缩和轻量压缩,介绍数据库中最常见的通用压缩方法原理,然后逐一介绍轻量压缩,并讨论字符串的轻量字典压缩,为下一个部分铺垫。在“延迟解压加速计算”部分,我们介绍压缩数据上的直接查询的优化技术,又称为延迟解压技术,然后分析基于字符串字典压缩优化的原理和难点。最后,我们进行“总结以及后续工作”的讨论,展望PolarDB HTAP在数据压缩方向的后续工作。
数据压缩概述
压缩算法包括无损压缩和有损压缩,本文我们只讨论无损压缩,即解压后的文本与压缩前的文本完全相同,后文的“压缩”都是指无损压缩。压缩算法由编码和解码两部分构成,编码和解码本质上是将文本映射到另一个更紧凑的文本空间以及逆映射的过程。
压缩与概率是紧密相关的。所有的压缩算法对于输入数据都有一定的预先假设,这种假设可以用概率描述,例如假设某种数据重复的概率或某几种数据一起出现的概率高。香农的论文《通信的数学原理》,被视为现代信息论研究的开端,正是信息论将数据出现的概率和数据所需编码长度联系起来。在论文中,香农从统计物理学中借鉴了熵的概念,定义了信息熵[2]:
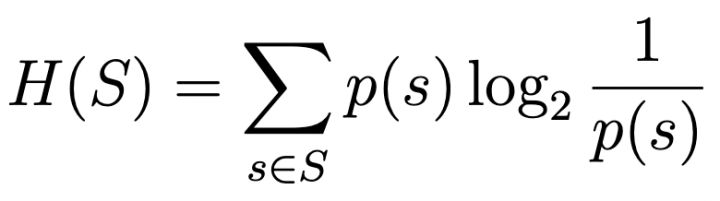
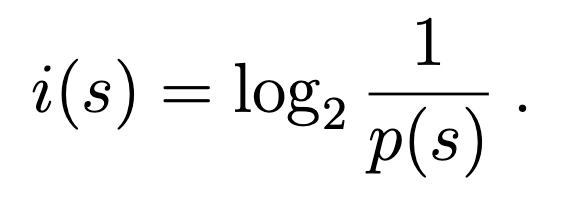
H(S)即信息熵,S是所有信息s构成的集合,p(s) 是信息s出现的概率,s ∈ S。i(s)表示需要编码单个信息所需要的比特数,而信息熵H(S)是i(s)以概率p(s)为权重的加权平均,表示编码信息集合S所需的总比特数。
举个例子简单理解这两个公式。我们假设96个可打印字符出现的概率相同,那么编码每个字符需要的平均比特数,即i(s) = log_2(96) = 6.6 bits/char,显然,至少7 bits才可以表示96(2^7=128)个不同的字符。如果我们基于一个英文文本集(例如Calgary Corpus)进行统计,使用字符的频率近似概率,计算出信息熵的平均值i(s)为4.5 bits/char,具体编码可以通过huffman编码算法得到。这个估算认为字符间是独立的,如果考虑上相邻字符、单词间的关联结合超大文本进行统计,编码字符所需要的比特数是1.3 bits/char,8/1.3 = 6.15近似为任意英文文章的压缩比的上界。
通用压缩算法对输入数据仅做简单的假设,如假设数据存在局部相似性等。GZIP和BOA在Calgary Corpus文本集的压缩效果为2.7 bits/char和2.0 bits/char,如果要更接近英文文本的压缩上界,通用压缩算法需要英文词频和语法等作为输入,这将影响其通用性。我们在下一部分对常见通用压缩算法的原理进行简单介绍。

编码可打印字符所需要的比特数,因此数值越小,说明压缩效果越好,图源自[2]。
了解压缩与概率的关联后,我们看看数据库系统中的数据压缩问题。首先我们关注OLTP数据库和OLAP数据库的数据存储格式,常见的OLTP数据库的存储引擎包括基于B+Tree的innodb和基于LSM-Tree的X-Engine和rocksDB等,它们使用行式存储,表数据按行水平分割,每个记录会包含各个不同的列。而OLAP数据库使用列式存储,表数据按列垂
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3702
3702











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









