







在前面文章里面,我们介绍了单链路的筛选与轨迹回溯,是从单次请求的视角来分析问题,类似查询某个快递订单的物流轨迹。但单次请求无法直观反映应用或接口整体服务状态,经常会由于网络抖动、宿主机 GC 等原因出现偶发性、不可控的随机离群点。当一个问题发生时,应用负责人或稳定性负责人需要首先判断问题的实际影响面,从而决定下一步应急处理动作。因此,我们需要综合一段时间内所有链路进行统计分析,这就好比我们评估某个物流中转站点效率是否合理,不能只看某一个订单,而要看一段时间内所有订单平均中转时间与出错率。
统计分析是我们观察、应用分布式链路追踪技术的重要手段。我们既可以根据不同场景要求进行实时的后聚合分析,也可以将常用的分析语句固化成规则生成预聚合指标,实现常态化监控与告警。相对于链路多维筛选,统计分析需要明确分析对象与聚合维度。其中,分析对象决定了我们对哪些指标进行聚合操作,比如请求量、耗时或错误率。而聚合维度决定了我们对哪些特征进行统计对比,比如不同应用、接口、IP、用户类型的统计量对比。接下来,我们先了解下分析对象和聚合维度的具体概念,再介绍实时分析与监控告警的具体用法。
01 分析对象
分析对象,又称为度量值(Measure),决定了我们对哪些指标进行聚合操作。常见的度量值包括“黄金三指标”——请求量、错误和耗时。除此之外,消息延迟、缓存命中率或自定义度量值也是高频应用的分析对象,我们来逐一了解下。
(一)请求量
请求量可以说是我们最熟悉的度量值之一。这个接口被调用了多少次?这一分钟的请求量与上一分钟相比有什么变化,与前一天相比有什么变化?这些问题都是我们在日常运维过程中最熟悉的对话。
请求量通常按照一个固定的时间间隔进行统计,比如按秒统计的请求量通常称之为 QPS(Queries Per Second),有些场景也会称之为 TPS(Transactions Per Second)。两者有一些细微差别,但含义基本相同,经常被混用。我们可以使用 QPS 来衡量系统的单位时间吞吐能力,用以指导系统资源的分配调度;或者观测用户行为的变化,判断系统是否出现异常。
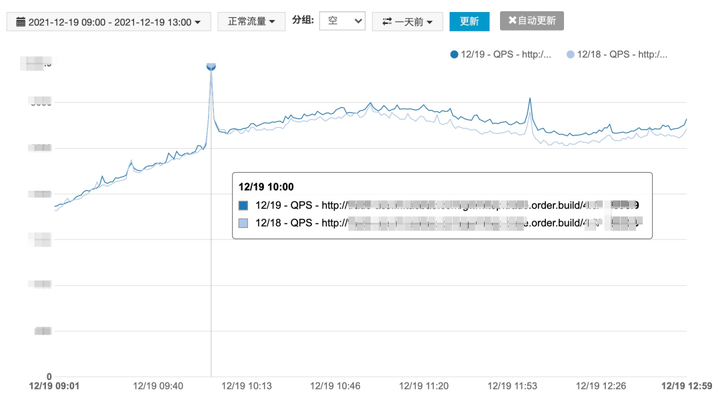
如下图所示,创建订单接口每天上午 10 点和 12 点的请求量都会有一个周期性的突增,这种情况大概率是整点促销活动的正常表现,我们在做资源容量评估时需要参考整点的峰值请求量,而不是系统平均请求量,否则每当流量突增时系统可用性就可能大幅下降,影响用户体验。
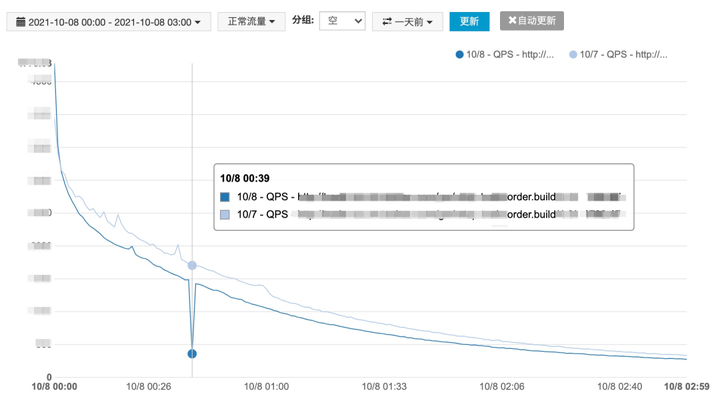
下面第二张图的创建订单接口在 10 月 8 号凌晨 00:39 分有一个非常明显的下跌,并且前一天的曲线是比较平滑的,这种现象大概率是接口异常导致的,已经影响了用户的下单体验,需要深入排查定位原因。
请求 QPS 的变化趋势反映了系统吞吐能力的变化,是请求量最常用的一种方式。但在某些离线计算场景,对短时间内的吞吐变化不敏感,更需要一个比较大的时间间隔内的吞吐总量统计,比如一天或一周的请求处理总量。以便灵活分配离线计算资源。
错误
每一次链路请求都会对应着一个状态:成功,或失败。一次失败的请求通常称之为错误请求。单条错误请求可能由于各种各样的偶发性原因不予关注。但是当错误数累积到一定程度,超过一定阈值时,就必须要进行处理,否则会引发大面积的系统故障。
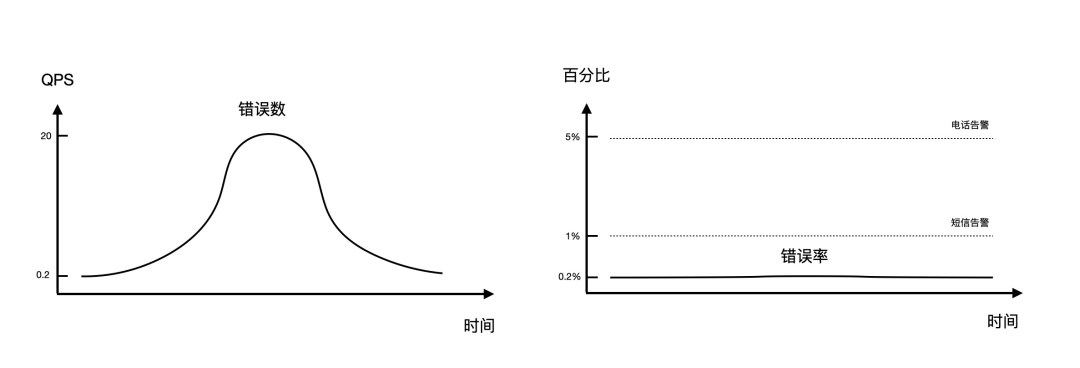
错误指标除了像请求量一样,分为错误 QPS 和错误总量之外,还有一种比较特殊的统计方式,就是错误率。错误率是指在单位时间间隔内错误数占请求总数的比例。比如 A 接口一分钟内被调用了 10000 次,其中有 120 次是错误调用,那么 A 接口这一分钟的错误比率就是 120 / 10000 = 0.012,也就是 1.2%。
错误率是衡量系统健康程度的关键指标,针对它的健康阈值设置不会受请求量的周期性变化影响。比如下单接口的请求量在白天达到峰值的 10000 QPS,在夜间的谷值只有 100 QPS,全天的请求量变化范围在 100 ~ 10000 QPS 之间。相应的错误量变化范围在 0.2 ~ 20 QPS 之间,而错误率基本固定在 0.2% 左右。无论是使用固定阈值或同环比的方式,错误数都很难精确反映系统实际的健康程度,而错误率使用起来就简单、有效的多。比如设置错误率超过 1% 时就发送告警短信,超过 5% 就电话通知稳定性负责人立即排查。
(二)耗时
耗时也是我们非常熟悉的度量值之一,简单地说就是这次请求的处理花费了多长时间。但是不同于请求量。对耗时次数或总量的统计不具备实用价值,最常用的耗时统计方式是平均耗时。比如 10000次调用的耗时可能各不相同,将这些耗时相加再除以 10000 就得到了单次请求的平均耗时,它可以直观的反应当前系统的响应速度或用户体验。
不过,平均耗时有一个致命的缺陷,就是容易被异常请求的离散值干扰,比如 100 次请求里有 99 次请求耗时都是 10ms,但是有一次异常请求的耗时长达1分钟,最终平均下来的耗时就变成(60000 + 10*99)/100 = 609.9ms。这显然无法反应系统的真实表现。因此,除了平均耗时,我们还经常使用耗时分位数和耗时分桶这两种统计方式来表达系统的响应情况。
耗时分位数
分位数,也叫做分位点,是指将一个随机变量的概率分布范围划分为几个等份的数值点,例如中位数(即二分位数)可以将样本数据分为两个部分,一部分的数值都大于中位数,另一部分都小于中位数。相对于平均值,中位数可以有效的排除样本值的随机扰动。
举个例子,你们公司每个同事的薪资收入可能各不相同,如果财务负责人要统计公司的中间薪资水平有两种方式,一种就是把所有人的薪资加在一起再除以人数,这样就得到了平均薪资;还有一种是将薪资从高到低排序,选取排在中间的那个人的薪资作为参考值,也就是薪资中位数。这两种做法的效
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 770
770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









