







数字电路与逻辑设计——加法器的实现
代码仅供参考:
链接:pan.baidu.com/s/1VekND1K50yclOKdkSI-otw
up1k
一、实验目的
- 了解运算器的内部结构。
- 熟悉并行加法器和串行加法器的工作原理。
- 分析模型机的功能,设计 ALU 和移位逻
二、实验内容
- 用 VHDL 语言设计4 位并行加法器;
- 用 VHDL 语言设计 4 位串行加法器;
- 用 VHDL 语言设计模型机运算器 ALU;
- 用 VHDL 语言设计移位逻辑。
三、实验方法
1、 实验方法
采用基于FPGA进行数字逻辑电路设计的方法。
采用的软件工具是Quartus II。
2、 实验步骤
(四个文件过程相似,以4位并行加法器为例)
① 新建三个工程,编写源代码。
(1).选择保存项和芯片类型:【File】-【new project wizard】-【next】(设置文件路径+设置project name为Parallel_adder)-【next】(设置文件名Parallel_adder.vhd—在【add】)-【properties】(type=AHDL)-【next】(family=FLEX10K;name=EPF10K10TI144-4)-【next】-【finish】
(2).新建:【file】-【new】(第二个AHDL File)-【OK】
② 写好源代码,保存文件(Parallel_adder.vhd)。
③ 编译与调试。确定源代码文件为当前工程文件,点击【processing】-【start compilation】进行文件编译,编译成功。
④ 波形仿真及验证。新建一个vector waveform file。按照程序所述插入a,b,c三个节点(a、b为输入节点,c为输出节点)。(操作为:右击 -【insert】-【insert node or bus】-【node finder】(pins=all;【list】)-【>>】-【ok】-【ok】)。任意设置a,b的输入波形…点击保存按钮保存。(操作为:点击name(如:a))-右击-【value】-【Random】(如设置Every grid interval),同理设置name b(Every grid interval),保存)。然后【start simulation】,出name sum和name Cout的输出图。
⑤ 时序仿真或功能仿真。
⑥ 查看RTL Viewer:【Tools】-【netlist viewer】-【RTL viewer】。
四、实验过程
(一)4位并行加法器
1、 编译过程
a. 源代码如图(VHDL设计)

b. 编译、调试过程

无错误信息,编译通过。
c. RTL视图

d. 结果分析及结论
实现4位并行加法器需要四个全加器来同步进行,设计较为简单,速度也较快,但是门输入成本较高。只需定义一个加法器后在四次调用,将前一位的进位输出当作下一位的进位输入,第一位的进位输入为0,最后整个电路的进位输出是最后一位全加器的进位输出。
2、 波形仿真
a. 波形仿真过程(详见实验步骤)
b. 波形仿真波形图

c. 结果分析及结论
0-10ns:a=0110,b=1001,Cin=0,a+b=sum=1111,Cout=0,结果正确;
10-20ns:a=0111,b=1010,Cin=1,a+b=sum=0010,Cout=1,结果正确;
20-30ns:a=1000,b=1011,Cin=0,a+b=sum=0011,Cout=1,结果正确;
30-40ns:a=1001,b=1100,Cin=1,a+b=sum=0110,Cout=1,结果正确;
3、 时序仿真
a. 时序仿真过程
做好上述步骤后,编译【classic timing analysis】-在compilation report中选择【timing analysis】-【tpd】(引脚到引脚的延时)
b. 时序仿真图
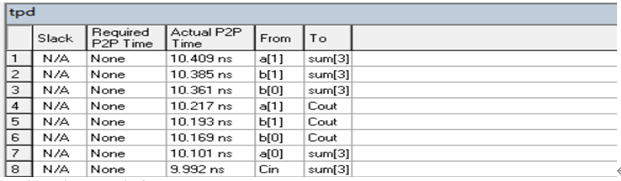
c. 结果分析及结论
由a(1)引脚到sum(3)引脚所需时间最长为10.409ns,由于总体时间由最长时间决定,因此总体时间为10.409ns。
tpd (引脚到引脚的延时)
(二) 四位串行加法器
1、 编译过程
a. 源代码如图(VHDL设计)


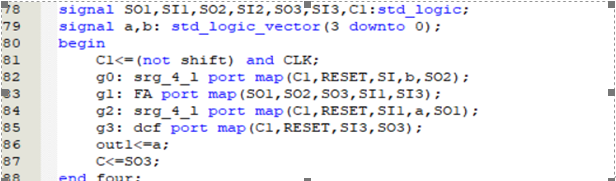
b. 编译、调试过程

无编译错误。
c. RTL视图

d. 结果分析及结论
串行加法器的实现较为困难,只用两个寄存器与一个触发器和一个全加器可完成任意位的加法计算,其中A寄存器用来存放全加器计算得到的结果,但其没有外部输入,因此要在A中存放加数需要先将A寄存器复位,再输入加数与被加数(共8位)到B中,在输入后四位时前四位会经过全加器到达寄存器A,这样在第8个时钟上延完成加数与被加数的存放工作,接着第9到第12个时钟上延将A中与B中的四位二进制数从低向高位依次进入全加器进行运算,最后都回到寄存器A,此时将A中的二进制数作为输出即为运算结果。
2、 波形仿真
a. 波形仿真过程(详见实验步骤)
b. 波形仿真波形图

c. 结果分析及结论
前四个CLK上延为存储第一个加数(在A寄存器中),其值为:1111
后四个CLK上延为存储第二个加数(在B寄存器中),其值为:0011
两个值运算结果应为:10010
第9-12个CLK上延为运算过程,第12个时钟上延结果out1为:0010,进位C为1,结果正确。
3、 时序仿真
a. 时序仿真过程
做好上述步骤后,编译【classic timing analysis】-在compilation report中选择【timing analysis】
b. 时序仿真图

c. 结果分析及结论
由于电路中有时序电路部分,因此没有tpd,全局时钟的建立时间Tsu为1.592ns,在时钟上跳沿后,信号必须保持的最小时间Th为-1.312ns,时钟上升沿与输出端(Q端)数据稳定输出的时间差Tco为8.481ns。
(三)模型机运算器ALU
1、 编译过程
a. 源代码如图(VHDL设计)


b. 编译、调试过程

无错误信息。
c. RTL视图

逻辑符号:

d. 结果分析及结论
由 R2 的编码通过 RAA1、RAA0 从通用寄存器组 A 口读出 R2 的内容,由R1 的编码通过 RWBA1、RWBA0 从通用寄存器组 B 口读出 R1 的内容,在 S3~S0 和 M 的控制下,实现运算,经移位逻辑送入总线 BUS;由/WE 控制和 R1编码选择 RWBA1、RWBA0,将 BUS 上的数据写入通用寄存器 R1。其中 ADD和 SUB 指令影响状态位 Cf和 Zf。
ALU 根据 S3-S1 和 M 控制信号需要实现 ADD、SUB、OR、NOT 运算,并产生状态位 Cf和 Zf。另外,ALU 在 MOVA、MOVB、RSR 和 RSL 四条指令执行时,提供将数据传输至 BUS 总线的通
2、 波形仿真
a. 波形仿真过程(详见实验步骤)
b. 波形仿真波形图

c. 结果分析及结论
50-60ns:选择信号S=0101,进行NOT运算,B=00100011,输出T=11011100,结果正确;
60-70ns:选择信号S=0110,进行SUB运算,B=01000010,A=00011111,输出T=00100011,结果正确;
90-100ns:选择信号S=1001,进行ADD运算,B=01000000,A=10110111,输出T=11110111,结果正确;
110-120ns:选择信号S=1011,进行OR运算,B=01011101,A=10111000,输出T=11111101,结果正确;
3、 时序仿真
a. 时序仿真过程
做好上述步骤后,编译【classic timing analysis】-在compilation report中选择【timing analysis】-【tpd】(引脚到引脚的延时)
b. 时序仿真图

c. 结果分析及结论
S(3)引脚到T(1)引脚的实际p2p时间最长且为12.333ns,故整体为12.333ns。
tpd (引脚到引脚的延时)
(四) 移位逻辑
1、 编译过程
a. 源代码如图(VHDL设计)

b. 编译、调试过程

无错误信息。
c. RTL视图

逻辑符号:
d. 结果分析及结论
由 R1 的编码通过 RWBA1、RWBA0 从通用寄存器组 B 口读出 R1 的内容,在 S3~S0 和 M 的控制下通过 ALU,经移位逻辑循环右移或循环左移后送入总线 BUS;再由/WE 控制和 R1 的编码选择 RWBA1、RWBA0,将 BUS 上的数据写入通用寄存器 R1。
移位逻辑需要实现 RSR、RSL 操作,还需提供 MOVA、MOVB、ADD、SUB、OR、NOT 指令执行时,将数据传输至 BUS 总线的通路。
2、 波形仿真
a. 波形仿真过程(详见实验步骤)
b. 波形仿真波形图

c. 结果分析及结论
15-20ns:F_BUS=1、FL_BUS=0、FR_BUS=0,不进行移位操作,输入a=00111110,输出w=00111110,C=0,结果正确;
20-25ns:F_BUS=0、FL_BUS=1、FR_BUS=0,进行左移操作,输入a=00111111,输出w=01111110,C=0,结果正确;
50-55ns:F_BUS=0、FL_BUS=0、FR_BUS=1,进行右移操作,输入a=01000010,输出w=00100001,C=0,结果正确;
3、 时序仿真
a. 时序仿真过程
做好上述步骤后,编译【classic timing analysis】-在compilation report中选择【timing analysis】-【tpd】(引脚到引脚的延时)
b. 时序仿真图
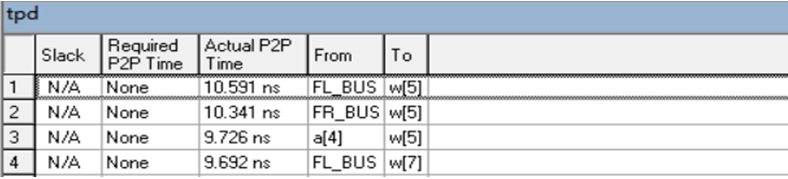
c. 结果分析及结论
FL_BUS引脚到w(5)引脚的实际p2p时间最长且为10.591ns,故整体为10.591ns。
tpd (引脚到引脚的延时)
五、实验结论
做第二个实验的时候遇到了许多困难,包括加数与被加入如何加入到两个寄存器中、如何输出、如何将各个部件连接起来等等,经过两天的学习和与同学们的交流终于还是弄懂了一整个过程并完整的将书上的串行加法器转化为了VHDL程序。第一次接触到这种时序电路真的有一些懵懂,但我相信有了这次实验的基础下次再做时序电路的时候能够更加熟练。第一个并行加法器比较简单,仅需要用四个全加器简单的连接即可完成,运行速度也较快,但是碍于其庞大的门输入成本,这种加法器似乎并不常用于工业生产。第三个跟第四个实验还是CPU设计的一部分,需要考虑各种控制信号的情况,但总体还是比较简单的,只要搞清楚控制指令与它们对应的功能即可。















 5288
5288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









