






一、前言
论文:http://arxiv.org/abs/2103.02907论文:http://arxiv.org/abs/2103.02907
论文:源码:https://github.com/Andrew-Qibin/CoordAttention
在本文中提出了一种新颖且高效的注意力机制,通过嵌入位置信息到通道注意力,从而使移动网络获取更大区域的信息而避免引入大的开销。为了避免2D全局池化引入位置信息损失,本文提出分解通道注意为两个并行的1D特征编码来高效地整合空间坐标信息到生成的attention maps中。
具体而言,利用两个1D全局池化操作将沿垂直和水平方向的input features分别聚合为两个单独的direction-aware feature maps。 然后将具有嵌入的特定方向信息的这两个特征图分别编码为两个attention map,每个attention map都沿一个空间方向捕获输入特征图的远距离依存关系。 位置信息因此可以被保存在所生成的attention map中。 然后通过乘法将两个attention map都应用于input feature maps,以强调注意区域的表示。
考虑到其操作可以区分空间方向(W,H即坐标)并生成coordinate-aware attention maps,因此论文将提出的注意力方法称为“coordinate attention”。
二、图解
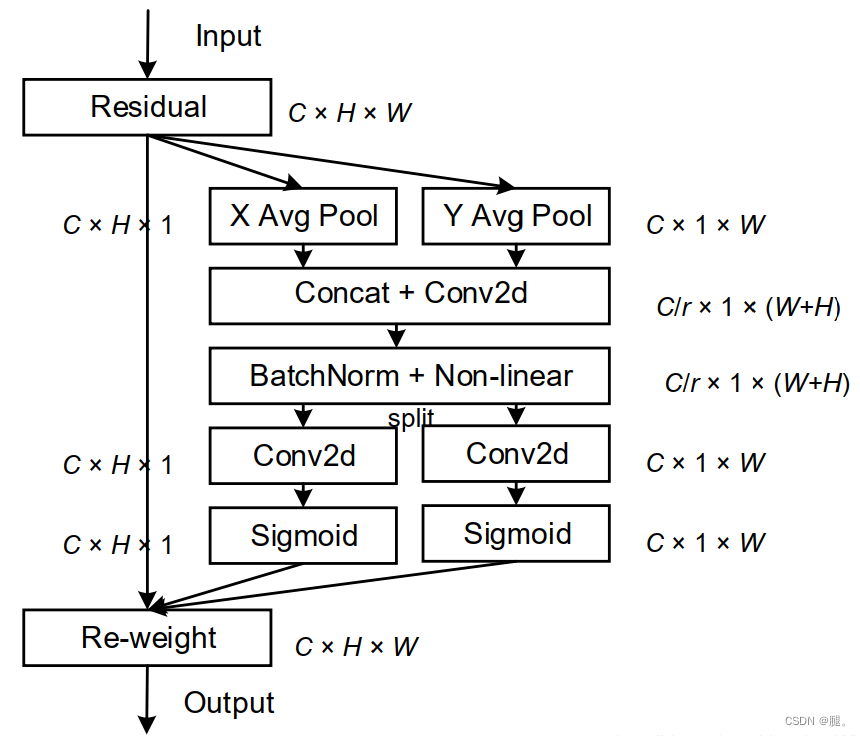
1、得到input后,获取input的W和H,然后对W和H分别进行平均池化。XAvgPoo是对W方向做平均池化,得到C × H × 1;同样 YAvgPool是对H方向做平均池化,得到C × 1 × W
2、对平均池化后的结果做空间维度(dim=2)的concat,然后做卷积(kernel_size=1, stride=1)压缩通道
3、然后再通过BN和Non-linear(激活函数)
4、再进行split分离(就是将完整的特征向量重新分为两个方向的向量),然后做卷积(kernel_size=1, stride=1)重新调整两个方向特征向量的通道数,然后经过Sigmoid函数
5、最后在与原输入信息进行两个方向的加权
三、pytorch代码
import torch
import torch.nn as nn
import math
import torch.nn.functional as F
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n,c,h,w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









