






介绍
大型语言模型 (LLM) 以其生成人类质量文本、翻译语言、总结内容和回答复杂问题的能力吸引了世界。突出的例子包括 OpenAI 的 GPT-3.5、谷歌的 Gemini、Meta 的 Llama2 等。
随着 LLM 变得越来越强大和复杂,衡量基于 LLM 的应用程序性能的重要性也越来越大。评估 LLM 对于确保它们在各种 NLP 应用程序中的性能、可靠性和公平性至关重要。在本文中,我们将探讨与评估大型语言模型相关的需求、挑战和方法。
学习目标
● 了解LLM评估的必要性
● 探索LLM评估中面临的挑战
● 了解评估 LLM 的各种方法
● 了解使用LangChain进行基于LLM的自动评估
● 探索LangChain中可用的各种类型的字符串赋值器和比较赋值器
本文作为数据科学博客马拉松的一部分发表。
目录
- 需要LLM评估
- 法学硕士评估的挑战
- 评估 LLM 的方法
- 不同评价方法的优缺点
- LangChain中基于LLM的(自动化)评估
○ 字符串赋值器
○ 比较评估员 - 常见问题解答
需要LLM评估
随着语言模型的能力和规模不断提高,研究人员、开发人员和业务用户面临着模型幻觉、有毒、暴力反应、越狱等问题。
下面的二维景观代表了各种此类问题的频率和严重程度。幻觉可能经常出现,但与越狱和及时注射相比,其严重程度较低。相反,有毒和暴力反应的频率和严重程度处于中等水平。
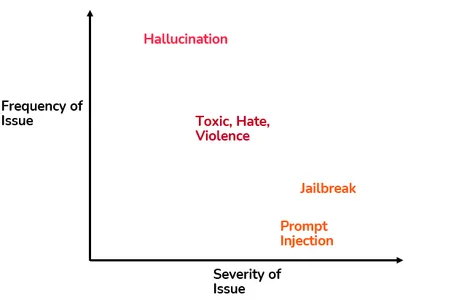
让我们详细讨论这些问题。
幻觉
幻觉是大型语言模型 (LLM) 中发生的一种现象,其中模型生成的文本与输入上下文不符、不连贯或不一致。虽然 LLM 擅长生成看起来连贯且与上下文相关的文本,但它们偶尔也会产生超出输入上下文范围的输出,从而导致幻觉或误导性信息。例如,在摘要任务中,LLM 可能会生成包含原始文本中不存在的信息的摘要。
有毒、仇恨、暴力反应
LLM 产生有毒、充满仇恨和暴力的反应是一个令人担忧的方面,凸显了道德挑战。这种反应可能对个人和群体有害和冒犯。我们应该评估 LLM 以评估其输出质量和适当性。

及时注入和越狱
提示注入是一种技术,它涉及通过使用精心设计的提示来绕过过滤器或操纵 LLM,这些提示会导致模型忽略先前的指令或执行意外操作。这可能会导致意想不到的后果,例如数据泄露、未经授权的访问或其他安全漏洞。

越狱
它通常是指生成涉及规避限制、违反规则或从事未经授权的活动的内容或响应。越狱的一种常见方法是假装。

稳健的 LLM 评估对于缓解此类问题并确保连贯且与上下文一致的响应至关重要。高质量的法学硕士评估有助于:
● 绩效评估:了解模型的优点和缺点。
● 微调和优化:确定可以微调和优化模型的领域。
● 泛化和鲁棒性:评估模型将其知识推广到不同输入/任务的能力。
● 用户体验:评估模型对用户输入的响应程度,并生成上下文相关且连贯的输出,以获得积极的用户体验。
● 道德考量:识别和解决与偏见、错误信息或潜在有害输出相关的道德问题。
● 进一步改进:使用最先进的能力确定需要进一步研究的领域。
评估大语言模型的挑战
● 非确定性输出: 给定相同的输入提示,LLM 可以在不同的重新运行中产生不同的响应。
● 缺乏基本事实:获取高质量的参考/标记数据可能会带来挑战,尤其是在存在多个可接受响应或涉及开放式需求的任务中。
● 实际适用性: 现有的学术基准数据集不能很好地概括企业特定的真实用例。
● 主观性: 评估类型(如人工评估)可能是主观的,容易产生偏见。不同的人类评估者可能持有不同的观点,并且评估标准可能缺乏统一性。
评估 LLM 的方法
有许多评估 LLM 的方法。让我们探讨一些评估 LLM 产出的典型方法。
1. 人工评价
评估 LLM 性能的最直接和最可靠的方法是通过人工评估。人工评估人员可以评估模型性能的各个方面,例如其事实准确性、连贯性、相关性等。这可以通过成对比较、排名或评估生成文本的相关性和连贯性来完成。
以下是一些可以帮助人工评估的工具:Argilla(开源平台)、LabelStudio 和 Prodigy。
2. 最终用户反馈
最终用户反馈(用户评级、调查、平台使用情况等)提供了有关模型在实际场景中的表现和满足用户期望的见解。
3. 基于LLM的评估
利用LLM本身来评估输出的质量。这是一种动态方法,使我们能够创建自主和适应性,而无需外部评估或人工干预。
基于LLM的评估框架:LangChain、RAGAS、LangSmith
4. 学术基准
基准测试数据集(如 GLUE、SuperGLUE、SQuAD 等)涵盖一系列语言任务,例如问答、文本完成、摘要、翻译和情感分析。
5. 标准量化指标
BLEU 分数、ROUGE 分数、困惑度等定量指标衡量生成的文本与特定任务的参考数据之间的表面相似性。但是,它们可能无法捕获 LLM 更广泛的语言理解能力。
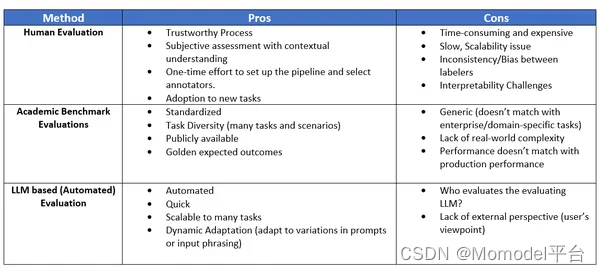
不同评价方法的优缺点
LangChain中基于LLM的(自动化)评估
LangChain是一个开源框架,用于构建LLM驱动的应用程序。LangChain提供
各种类型的评估器来衡量各种数据的性能和完整性。
LangChain中的每种评估器类型都带有现成的实现和可扩展的API,允许根据独特的要求进行定制。这些评估器可以应用于 LangChain 库中的不同链和 LLM 实现。
LangChain中的赋值器类型:
● 字符串赋值器:这些赋值器评估给定输入的预测字符串,通常将其与引用字符串进行比较。
● 比较评估器:这些赋值器旨在比较对公共输入进行两次运行的预测。
● 轨迹评估器:这些用于评估代理操作的整个轨迹。
让我们详细讨论每种赋值器类型。
1. 字符串赋值器
字符串赋值器是LangChain中的一个组件,旨在通过将语言模型生成的输出(预测)与参考字符串(真实值)或输入(例如问题或提示)进行比较来评估语言模型的性能。这些评估器可以定制,以定制评估过程,以满足您应用的特定要求。
LangChain中的字符串赋值器实现:
标准评估
它允许验证 LLM 或 Chain 的输出是否符合一组指定的
标准。Langchain 提供各种标准,例如正确性、相关性、有害性等。以下是 Langchain 中可用标准的完整列表。
from langchain.evaluation import Criteria
print(list(Criteria))

让我们通过使用这些预定义的标准来探索一些示例。
a.简洁
我们通过调用 load_evaluator() 函数并传递标准作为简洁性来实例化标准评估器,以检查输出是否简洁。
from langchain.evaluation import load_evaluator
evaluator = load_evaluator("criteria", criteria="conciseness")
eval_result = evaluator.evaluate_strings(
prediction="""Joe Biden is an American politician
who is the 46th and current president of the United States.
Born in Scranton, Pennsylvania on November 20, 1942,
Biden moved with his family to Delaware in 1953.
He graduated from the University of Delaware
before earning his law degree from Syracuse University.
He was elected to the New Castle County Council in 1970
and to the U.S. Senate in 1972.""",
input="Who is the president of United States?",
)
print(eval_result)
所有字符串赋值器都提供了一个 evaluate_strings() 方法,该方法采用:
● input (str) – 输入提示/查询
● prediction (str) – 模型响应/输出
条件赋值器返回具有以下属性的字典:
● 推理:一个字符串,表示从建立分数之前生成的 LLM 派生的“思维链推理”。
● 价值:与分数相对应的“Y”或“N”。
● 得分:二进制整数(0 或 1),其中 1 表示输出符合标准,0 表示不符合。
b.正确性
正确性标准需要参考标签。在这里,我们初始化labeled_criteria赋值器,并另外指定引用字符串。
evaluator = load_evaluator("labeled_criteria", criteria="correctness")
eval_result = evaluator.evaluate_strings(
input="Is there any river on the moon?",
prediction="There is no evidence of river on the Moon",
reference="""In a hypothetical future, lunar scientists discovered
an astonishing phenomenon—a subterranean river
beneath the Moon's surface""",
)
print(eval_result)
c. 自定义条件
我们还可以通过传递 {“criterion_name”: “criterion_description”} 形式的字典来定义我们自己的自定义标准。
from langchain.evaluation import EvaluatorType
custom_criteria = {
"numeric": "Does the output contain numeric information?",
"mathematical": "Does the output contain mathematical information?"
}
prompt = "Tell me a joke"
output = """
Why did the mathematician break up with his girlfriend?
Because she had too many "irrational" issues!
"""
eval_chain = load_evaluator(
EvaluatorType.CRITERIA,
criteria=custom_criteria,
)
eval_result = eval_chain.evaluate_strings(prediction = output, input = prompt)
print("===================== Multi-criteria evaluation =====================")
print(eval_result)

嵌入距离
嵌入距离测量预测和
参考标签字符串之间的语义相似性(或差异性)。它返回一个距离分数,表示较低的数值表示预测和参考之间的相似性较高,具体取决于它们的嵌入表示形式。
evaluator = load_evaluator("embedding_distance")
evaluator.evaluate_strings(prediction="Total Profit is 04.25 Cr",
reference="Total return is 4.25 Cr")
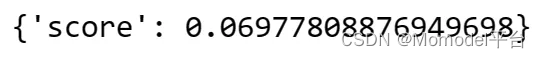
默认情况下,嵌入距离赋值器使用余弦距离。以下是支持的距离的完整列表。
from langchain.evaluation import EmbeddingDistance
list(EmbeddingDistance)

完全匹配
可能是评估 LLM 输出的最简单方法。在比较字符串时,我们也可以放宽精确度。
from langchain.evaluation import ExactMatchStringEvaluator
exact_match_evaluator = ExactMatchStringEvaluator()
exact_match_evaluator = ExactMatchStringEvaluator(ignore_case=True)
exact_match_evaluator.evaluate_strings(
prediction="Data Science",
reference="Data science",
)

评估结构化输出
JSON 赋值器有助于解析 LLM 的字符串输出(特别是 JSON 输出格式)。以下 JSON 赋值器提供检查模型输出一致性的功能。
a. JSValidity评估器
● 检查 JSON 字符串预测的有效性
● 需要输入:否
● 需要参考:否
from langchain.evaluation import JsonValidityEvaluator
evaluator = JsonValidityEvaluator()
prediction = '{"name": "Hari", "Exp": 5, "Location": "Pune"}'
result = evaluator.evaluate_strings(prediction=prediction)
print(result)
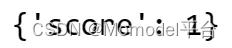
prediction = '{"name": "Hari", "Exp": 5, "Location": "Pune",}'
result = evaluator.evaluate_strings(prediction=prediction)
print(result)

b.JsonEqualityEvaluator
● 评估 JSON 预测是否与给定引用匹配。
● 需要输入:否
● 需要参考?: 是
from langchain.evaluation import JsonEqualityEvaluator
evaluator = JsonEqualityEvaluator()
result = evaluator.evaluate_strings(prediction='{"Exp": 2}', reference='{"Exp": 2.5}')
print(result)
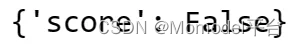
c. JsonEditDistanceEvaluator
● 计算两个规范化 JSON 字符串之间的归一化 Damerau-Levenshtein 距离。
● 需要输入:否
● 需要参考?: 是
● 距离函数:Damerau-Levenshtein(默认)
from langchain.evaluation import JsonEditDistanceEvaluator
evaluator = JsonEditDistanceEvaluator()
result = evaluator.evaluate_strings(
prediction='{"name": "Ram", "Exp": 2}', reference='{"name": "Rama", "Exp": 2}'
)
print(result)
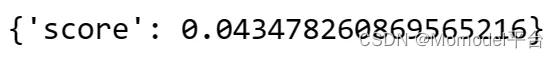
d. JsonSchemaEvaluator
● 根据提供的 JSON 架构验证 JSON 预测
● 需要输入?:是
● 需要参考?:是(JSON 架构)
● 得分:True(无错误)或 False(发生错误)
from langchain.evaluation import JsonSchemaEvaluator
evaluator = JsonSchemaEvaluator()
result = evaluator.evaluate_strings(
prediction='{"name": "Rama", "Exp": 4}',
reference='{"type": "object", "properties": {"name": {"type": "string"},'
'"Exp": {"type": "integer", "minimum": 5}}}',
)
print(result)

正则表达式匹配
使用正则表达式匹配,我们可以根据自定义正则表达式评估模型预测。
例如,下面的正则表达式匹配计算器检查是否存在 YYYY-MM-DD 字符串。
from langchain.evaluation import RegexMatchStringEvaluator
evaluator = RegexMatchStringEvaluator()
evaluator.evaluate_strings(
prediction="Joining date is 2021-04-26",
reference=".*\\b\\d{4}-\\d{2}-\\d{2}\\b.*",
)
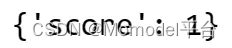
评分评估器
评分评估器有助于根据自定义标准/量规在指定等级(默认值为 1-10)上评估模型的预测。下面是自定义准确性标准的示例,该标准根据指定的参考以 1 到 10 的等级对预测进行评分。
from langchain.chat_models import ChatOpenAI
from langchain.evaluation import load_evaluator
accuracy_criteria = {
"accuracy": """
Score 1: The answer is completely unrelated to the reference.
Score 3: The answer has minor relevance but does not align with the reference.
Score 5: The answer has moderate relevance but contains inaccuracies.
Score 7: The answer aligns with the reference but has minor errors or omissions.
Score 10: The answer is completely accurate and aligns perfectly with the reference."""
}
evaluator = load_evaluator(
"labeled_score_string",
criteria=accuracy_criteria,
llm=ChatOpenAI(model="gpt-4"),
)
让我们根据上面的评分评估器对不同的预测进行评分。
# Correct
eval_result = evaluator.evaluate_strings(
prediction="You can find them in the dresser's third drawer.",
reference="The socks are in the third drawer in the dresser",
input="Where are my socks?",
)
print(eval_result)

# Correct but lacking information
eval_result = evaluator.evaluate_strings(
prediction="You can find them in the dresser.",
reference="The socks are in the third drawer in the dresser",
input="Where are my socks?",
)
print(eval_result)

# Incorrect
eval_result = evaluator.evaluate_strings(
prediction="You can find them in the dog's bed.",
reference="The socks are in the third drawer in the dresser",
input="Where are my socks?",
)
print(eval_result)

字符串距离
将 LLM 或链的字符串输出与参考标签进行比较的最简单方法之一是使用字符串距离测量,例如 Levenshtein 或后缀距离。
from langchain.evaluation import load_evaluator
evaluator = load_evaluator("string_distance")
evaluator.evaluate_strings(
prediction="Senior Data Scientist",
reference="Data Scientist",
)
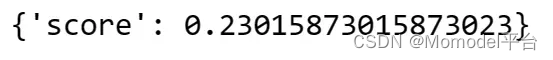
**
2. 比较评估员
**
LangChain中的比较评估器有助于测量两个不同的链或LLM输出。它有助于比较分析,例如两个语言模型之间的 A/B 测试或比较同一模型的两个不同输出。
LangChain中的比较评估器实现:
● 成对字符串比较
● 成对嵌入距离
成对字符串比较
这种比较有助于回答以下问题——
● 哪个 LLM 或提示为给定问题生成首选输出?
● 我应该在小样本选择中包括哪些示例?
● 哪个输出更适合进行微调?
from langchain.evaluation import load_evaluator
evaluator = load_evaluator("labeled_pairwise_string")
evaluator.evaluate_string_pairs(
prediction="there are 5 days",
prediction_b="7",
input="how many days in a week?",
reference="Seven",
)

成对嵌入距离
一种通过嵌入预测并计算两个嵌入之间的向量距离来衡量对公共或相似输入进行的两个预测之间的相似性(或不相似性)的方法。
from langchain.evaluation import load_evaluator
evaluator = load_evaluator(“pairwise_embedding_distance”)
evaluator.evaluate_string_pairs(
prediction=“Rajasthan is hot in June”, prediction_b=“Rajasthan is warm in June.”
)
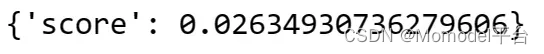
结论
在本文中,我们讨论了 LLM 评估、它的必要性以及评估 LLM 的各种流行方法。我们探索了不同类型的内置自定义评估器和LangChain提供的
不同类型的标准,以评估LLM的输出质量和适当性。
关键要点
● 评估 LLM 对于确认它们在各种 NLP 用途中的有效性、可靠性和公正性至关重要,因为它们变得越来越复杂并面临幻觉、毒性、暴力和安全规避等挑战。
● LangChain通过提供各种类型的即用型和可定制的评估器,促进了LLM的自动评估。
● 除了分数之外,LangChain评估员还提供推理,概括了源自LLM的“思维链推理”。
● LangChain 提供了多种字符串评估器,包括标准评估、嵌入式距离、精确匹配、JSON 评估器、评分评估器和字符串距离。
常见问题解答
问题1.LLM评估的目的是什么?
一个。LLM 评估的目的是确保大型语言模型 (LLM) 的性能、可靠性和公平性。它对于识别和解决模型幻觉、有毒或暴力反应以及及时注射和越狱等漏洞等问题至关重要,这些问题可能导致意外和潜在的有害结果。
问题2.LLM评估的主要挑战?
一个。大型语言模型 (LLM) 评估的主要挑战包括非确定性输出、难以获得明确的基本事实、将学术基准应用于实际用例的局限性以及人类评估中的主观性和潜在偏见。
问题3.评估 LLM 的流行方法有哪些?
一个。评估大型语言模型(LLM)的流行方法包括人工评估,通过评级和调查利用最终用户反馈,采用基于LLM的评估框架,如LangChain和RAGAS,利用学术基准,如GLUE和SQuAD,以及使用标准定量指标,如BLEU和ROUGE分数。
问题4.LangChain为评估LLM提供了哪些各种标准?
A. LangChain提供了一系列评估标准,包括(但不限于)简洁性、相关性、正确性、连贯性、有害性、恶意性、有用性、争议性、厌女症、犯罪性、不敏感性、深度、创造力和细节等。
问题5.LangChain中有哪些类型的比较评估器?
LangChain 中可用的比较评估器类型包括成对字符串比较、成对嵌入距离和自定义成对评估器。这些工具有助于比较分析,例如语言模型之间的 A/B 测试或评估同一模型的不同输出。
本文中显示的媒体不归 Analytics Vidhya 所有,由作者自行决定使用。
文章来源:https://www.analyticsvidhya.com/blog/2024/01/langchain-automating-large-language-model-llm-evaluation/
















 540
540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









