







链式法则
神经网络上的公式:通过使用链式法则就可以把最后一层的误差,一层层的输出到中间层的权值上面去,从而得到中间层的一个梯度信息。通过这个梯度信息就能很好的更新这个权值,从而到达一个最优化的效果。
链式法则表达形式:

链式法则原则
- 基础原则

- 乘积原则

- 除法原则

- 链式法则

对于一个比较简单的线性层直接相加的话,可以直接展开得到关于关于求导数的表达式,但是对于实际的神经网络和激活函数来说,展开求导函数的表达式是比较麻烦的不能一次到位。但是对于链式法则可以一步步展开,对于链式法则会使计算变得非常简单了,而且每一个中间过程可能已经有了中间的结果,故使用链式法则会让神经网络的求解变得简洁和清晰。
例:对于神经网络
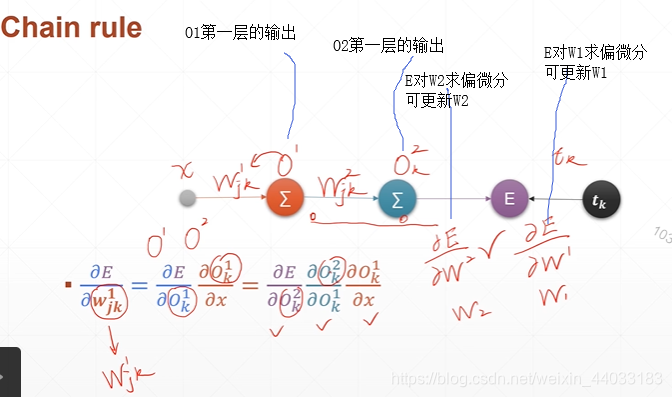
链式法则的直观感受:

import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
x = tf.constant([1.])
w1 = tf.constant([2.])
b1 = tf.constant([1.])
w2 = tf.constant([2.])
b2 = tf.constant([1.])
with tf.GradientTape(persistent = True) as tape: #True可求多次
tape.watch([w1, b1, w2, b2])
y1 = x * w1 + b1
y2 = y1 * w2 + b2
dy2_dy1 = tape.gradient(y2, [y1])[0]
#tf.Tensor([2.], shape=(1,), dtype=float32)
dy2_dw1 = tape.gradient(y2, [w1])[0]
#tf.Tensor([2.], shape=(1,), dtype=float32)
dy1_dw1 = tape.gradient(y1, [w1])[0]
#tf.Tensor([1.], shape=(1,), dtype=float32)

















 2356
2356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









