









很久没有写track相关的博客了,正巧前几天组里的一个师兄找我问track的文章,正常就想起来了mixformer v2,所以顺手写一下总结。
MixFormerV2: Efficient Fully Transformer Tracking
专注efficiency的模型,还是王老师组的工作,track这块follow王老师组就完事了。
contribution:
- 无Conv,纯Transformer Layer + MLP,非常优雅
- 速度很快,通过蒸馏的方法在保持精度的情况下对CPU很友好,edge computing方向可以参考
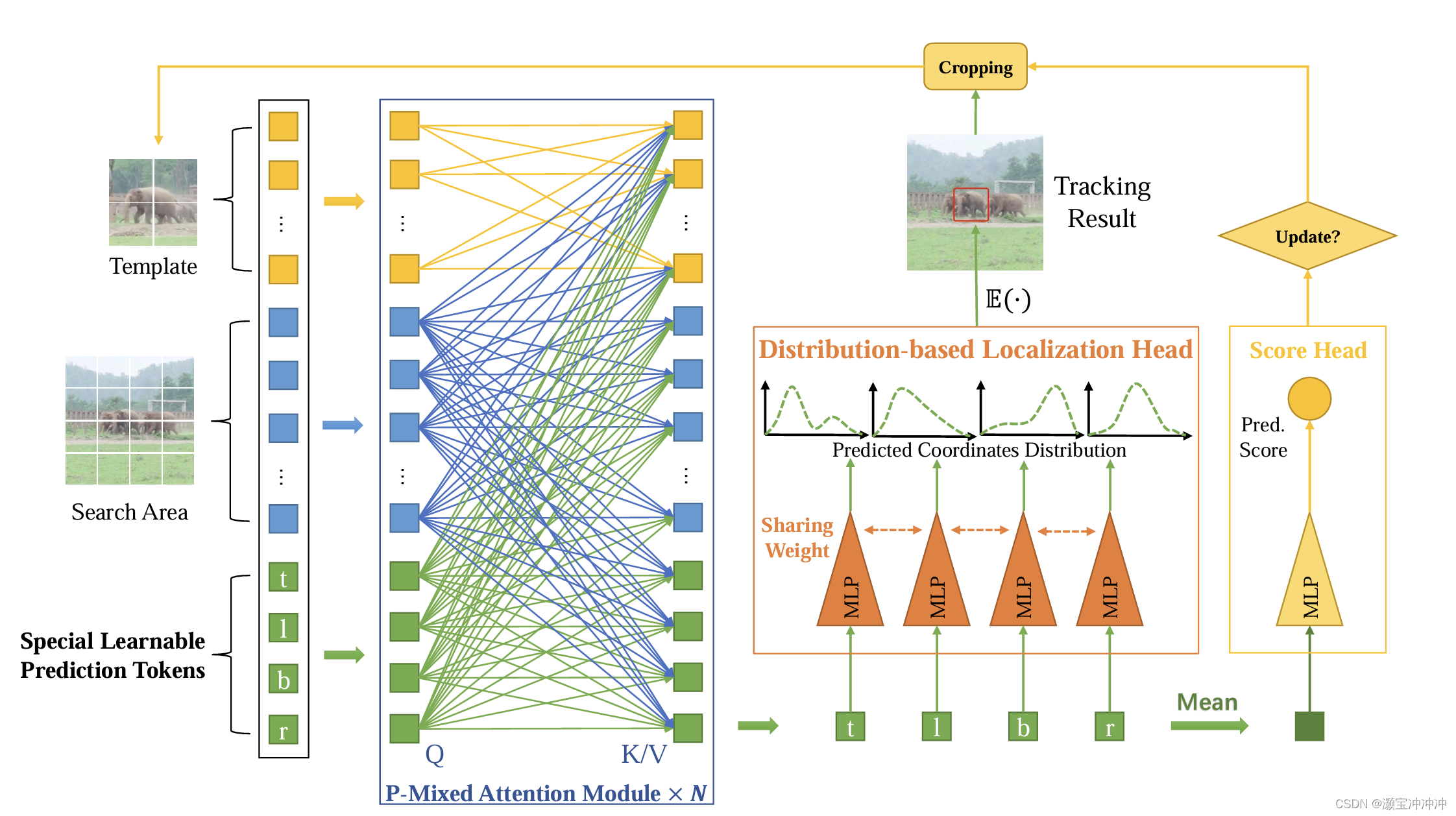
整体架构如图
核心block是中间的Mixed Attention Module,包含三个不同的部分
- template-part的self-attention
- search-part的cross-attention Query来自Search Key和Value是template、search、tokens三个部分concat
- toekns-part的cross-attention 结构和search-part相似
通过这种不对称的attention设计,可以降低计算开销,同时融合特殊tokens信息来提升template和search的交互性。最后的结果输出也是四个tokens通过MLP得到Box的坐标
蒸馏部分
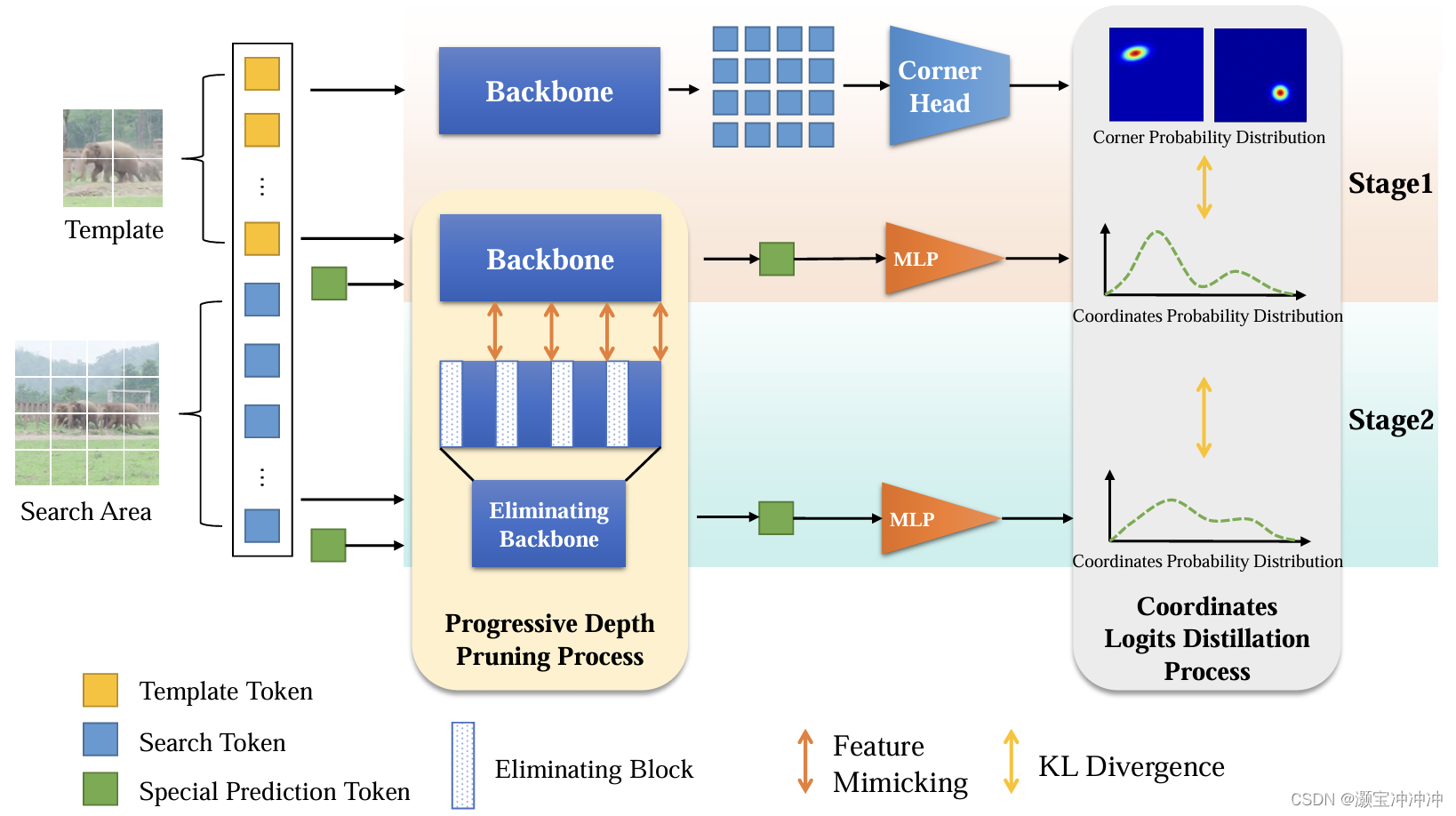
- Stage1 在Head上,原始的backbone输出的feature tokens通过corner head来得到结果,通过对tokens的简化,将原本所有feature tokens压缩为对bounding box的左右上下四个顶点预测,计算两者概率分布的KL散度来尽可能保证性能的不损失。
- Stage2 在Backbone上,将部分block的attention和mlp归零,只保留residual connection
- Stage2 在新的Backbone上,重复第一步的Head操作,计算蒸馏前后Head输出的KL散度,从而保证最小化Backbone简化对预测的影响
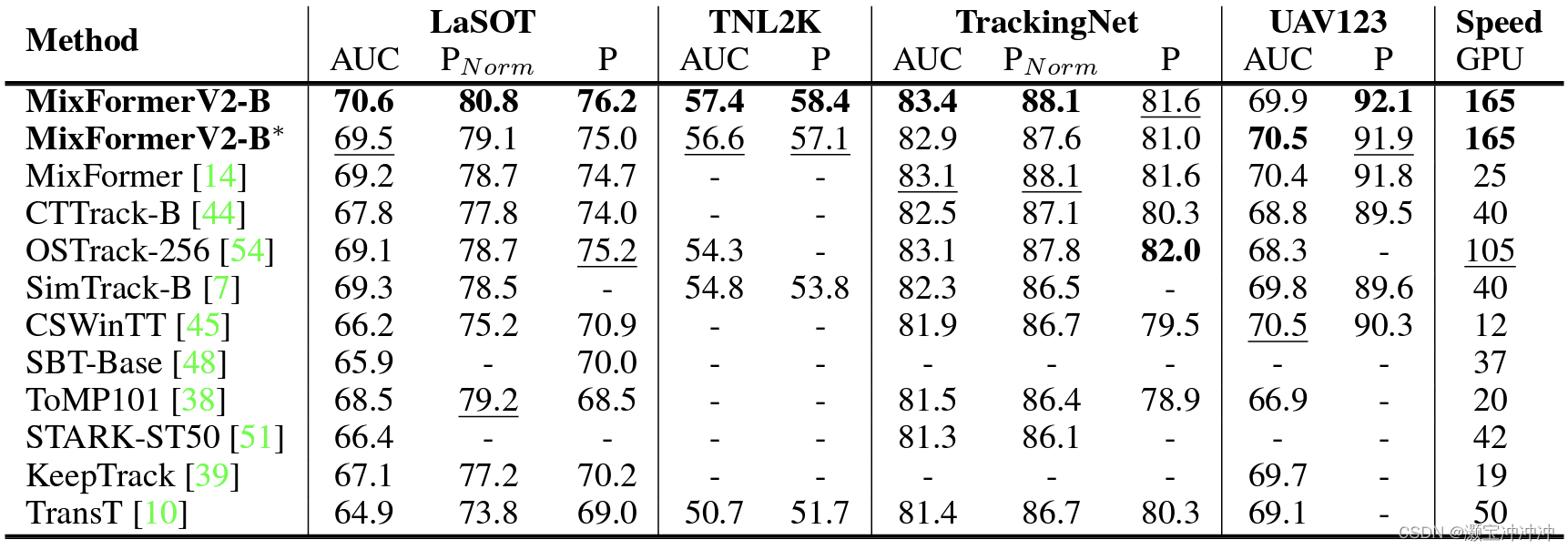
性能
性能没啥问题!
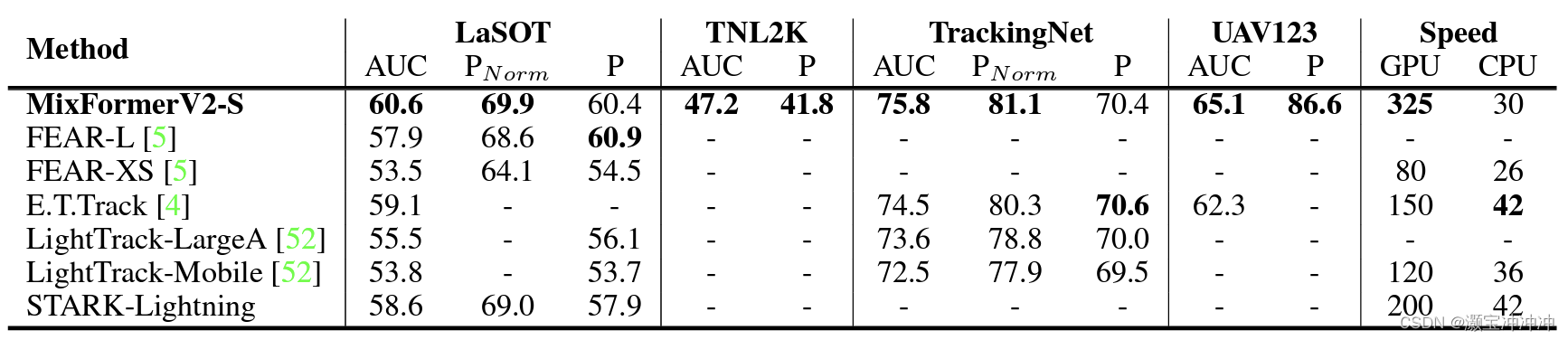
速度也很不错!
总结
个人观点,相比于在limited dataset上的性能提升,track任务其实更应该focus在open-world场景下的robustness和edge computing情况下的efficiency。如何在有限算力情况下做到更简洁更鲁棒的表达才是真实需求。















 4290
4290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









