







无监督学习
1. 导学部分

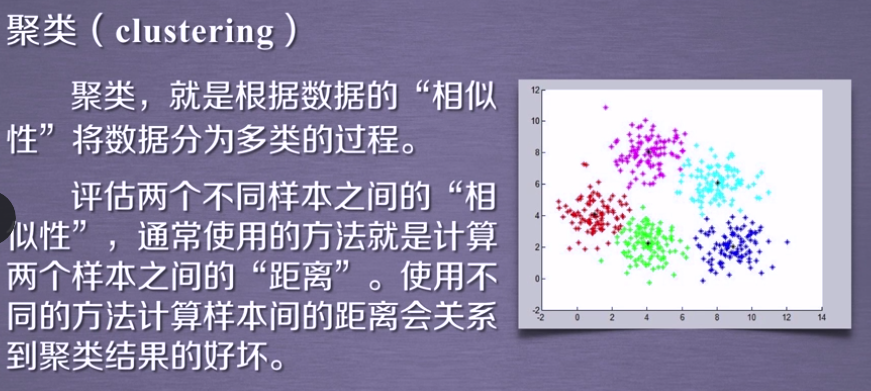 **tips:**使用聚类要计算距离
**tips:**使用聚类要计算距离



tips:使用马氏距离,中心到红点的距离大于中心到绿点的距离(这里不太明白)



**tips:**使用了三种算法:dbscan函数(最快);近邻传播算法(最慢);谱聚类算法


常用聚类算法

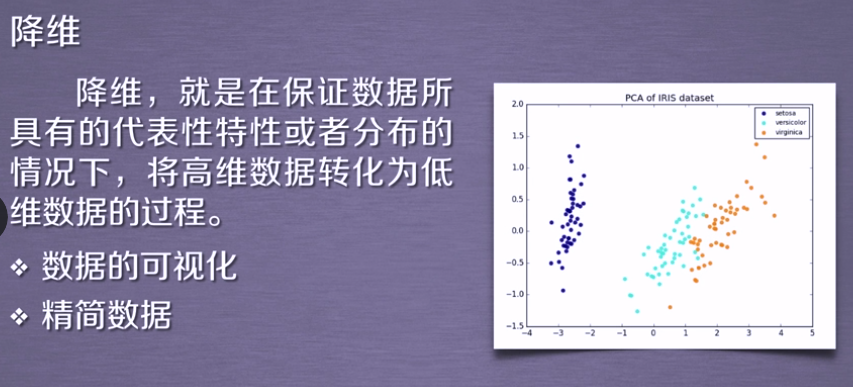
降维
用于提高运算性能


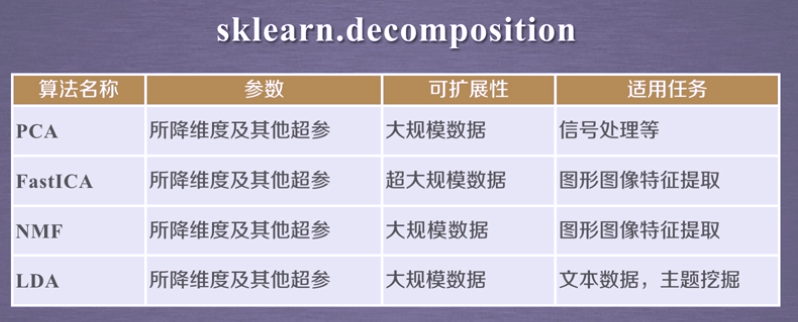
常用降维算法

**思考:**上述问题哪些是聚类,哪些是降维问题?
降维:4
聚类:123
2. 聚类算法
2.1 K-means算法

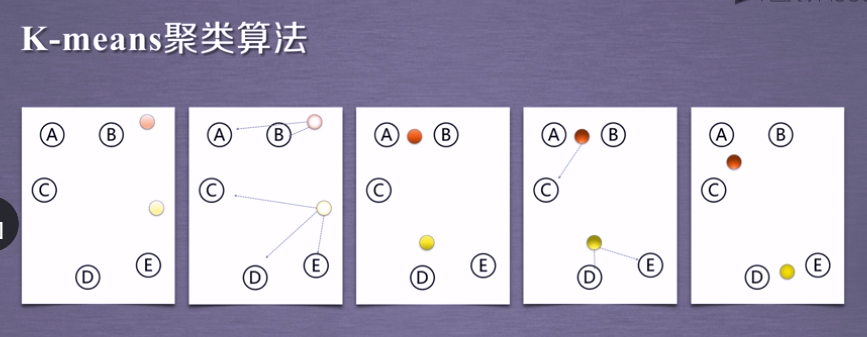
**Tips:**选取距离各点最近的中心点,由此分为两组,反复评估中心距离各点的距离












聚成4类时明显可以看到消费层级分得比较好了



自己练习的代码
#了解1999年各个省份的消费水平在国内的情况
#Kmeans算法-具体可以通过help(Kmeans)手册查询
import numpy as np
from sklearn.cluster import KMeans
#一个获取数据的函数
def loadData(filePath):
#r+读写模式
fr = open(filePath,'r+')
#一次读取全文
lines = fr.readlines()
retData = []
retCityName = []
#for循环内部用于处理单行数据,循环次数lines(31)次
for line in lines:
#删除作为间隔的逗号
items = line.strip().split(",")
#用于储存城市名称,位于第一列
retCityName.append(items[0])
#用于储存城市的各项消费信息
#for循环单行内的每个元素
#[float(items[i])这是什么意思?
retData.append([float(items[i]) for i in range(1,len(items))])
return retData,retCityName
if __name__ == '__main__':
#载入数据
#loadData是上面创建的函数
#因为是二维列表,所以赋值符前需要有两个变 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 443
443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









