






arXiv: https://arxiv.org/abs/2410.01215
Code & Demo: https://github.com/YerbaPage/MGDebugger
研究背景
1. 研究问题: 大型语言模型(LLMs)在代码生成领域取得了显著进展,但生成的代码常常因为细节错误而无法通过测试,尤其在处理复杂问题时,通常需要人工介入以修正错误。
2. 研究难点: 如何提高由大型语言模型 Debug 代码的准确性,尤其是在面对复杂编程任务和代码时,如何有效定位并修复代码中的错误。
3. 相关工作: 现有基于LLM的代码调试系统如 Self-Debugging, LDB, Reflexion 等, 这些方法通常将生成的程序视为一个整体,导致对于不同层次的 error 的修复性能有限,并且修复时还容易引入其他新 Bug。
研究方法
这篇论文提出了一种名为多粒度调试器(Multi-Granularity Debugger,MGDebugger)的新型代码调试方法,通过对于代码的分解和隔离的 Debug 来提升 LLM 修复代码的能力。具体包括以下几个步骤:
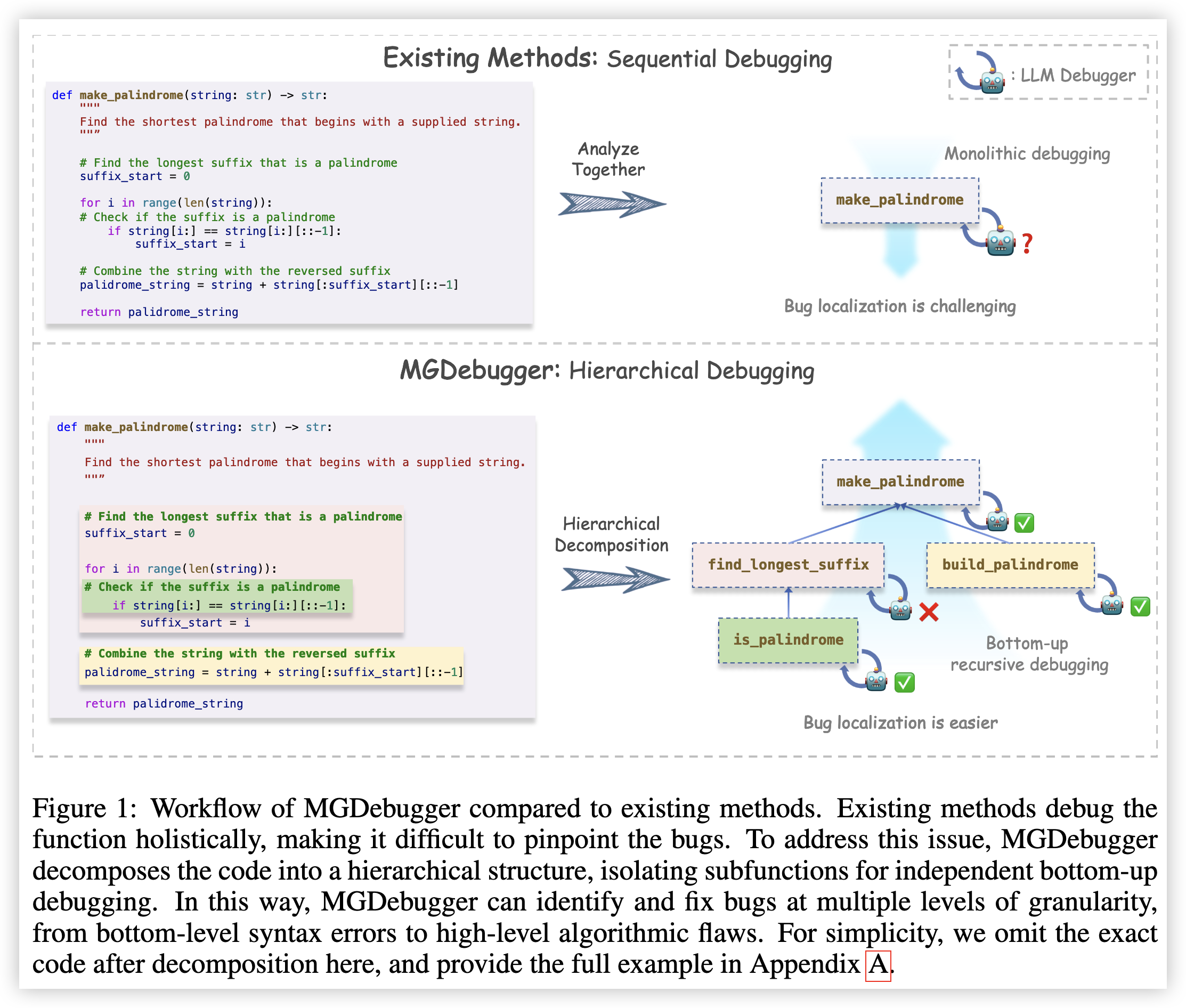
1. 层次化代码分解:将复杂代码分解为具有层次结构的子函数树状结构,每个层级代表代码中不同粒度的错误。
2. 子函数测试用例生成:为每个子函数生成测试用例,以便独立测试和调试。
3. LLM模拟执行:利用基于LLM的执行模拟器来跟踪代码执行过程中关键变量的变化,从而准确识别错误。
4. 自下而上的递归调试:从最细粒度的语法错误开始,逐步向上递归式修复更高层次的逻辑错误。

结果与分析
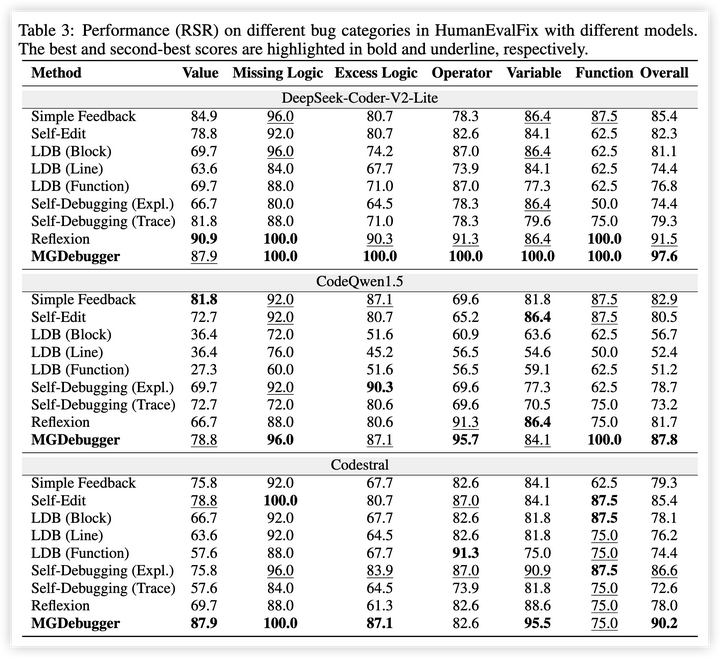
1. 主要结果:MGDebugger在所有测试设置中均优于基线方法,在HumanEval数据集上,准确性比原始代码提高了18.9%,在 HumanEvalFix 数据集上修复成功率达到了97.6%。
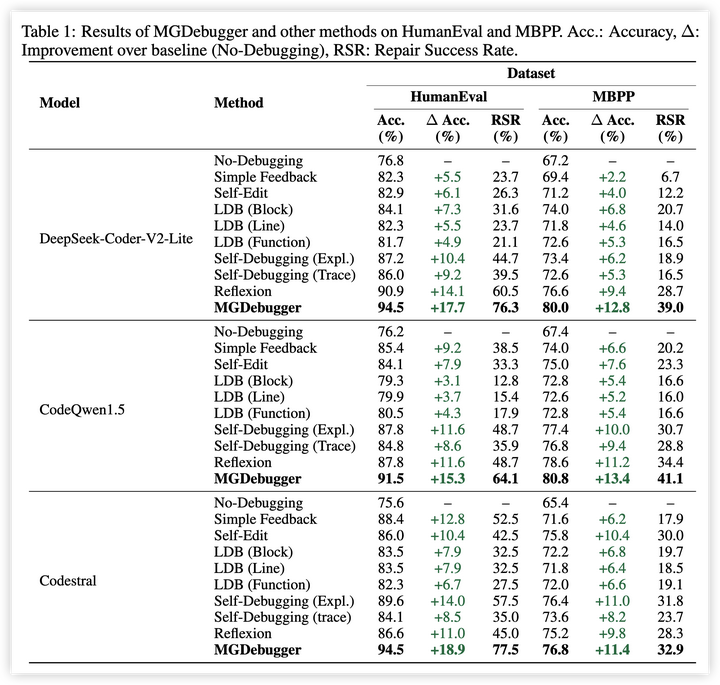
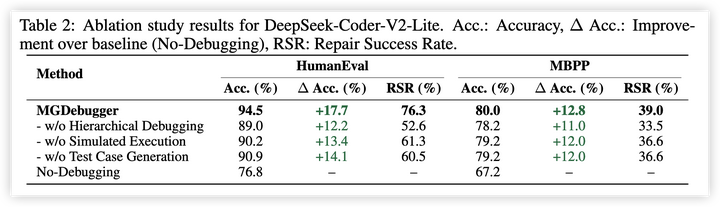
2. 消融研究:通过系统地移除MGDebugger的关键组件,验证了层次化的代码分解策略的关键性。
3. 不同代码长度的调试:分析了MGDebugger在处理不同长度代码时的性能,证明了其在处理更长、更复杂代码时的鲁棒性。

4. 多次调试尝试的影响:研究了多次反复调试尝试对 MGDebugger 性能的影响,发现MGDebugger能够随着调试次数的增加而持续改进,具有比基线方法更强的潜力。
总体结论
MGDebugger 通过层次化的代码分解与 Debug,有效地识别和修复了从语法错误到逻辑缺陷的多种错误。实验结果表明,MGDebugger在各种模型和数据集上均优于现有方法。未来的工作可以进一步探索将层次化的代码生成方法与之结合,并研究在更加复杂的代码生成场景下如何进一步提升 LLM Debug 能力的可能性。















 623
623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









