









一、项目展示
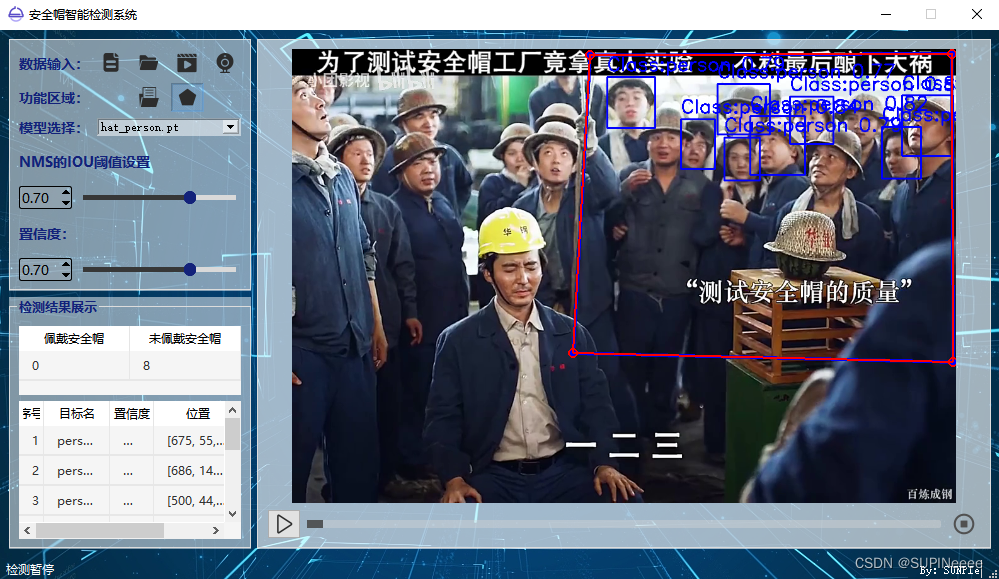
项目基于yolov5和pyqt5开发,以安全帽检测为例,亦可作为通用目标检测系统。适用于计算机相关大学生研究生课程设计、毕业设计以及相关比赛的界面展示。本项目GUI部分使用pyqt5制作,包括数据库、多线程、自定义组件等知识,亦可作为学习深度学习和pyqt5时的练手项目。b站视频展示。
功能以及特色如下:
- 系统带有登陆注册界面
- 输入数据格式:图片、文件夹、视频以及支持摄像头的实时检测,并自动保存最终检测结果。
- 支持选区检测功能,通过鼠标左键绘制多边形来确定检测区域,并且最终生成的结果视频中会保存绘制的多边形。
- 支持后处理过程中交并比(iou)以及置信度(conf)的动态调节。
- 检测视频和摄像头时,支持暂停、恢复、停止等功能,且停止后自动保存检测结果。
- 支持检测结果实时动态显示。
- 提供详细的项目说明以及环境配置教程,即使是深度学习小白也能轻松跑通项目。
- 项目提供项目系统代码,模型训练代码,模型训练结果以及数据集。

二、关键代码展示
# yolov5检测部分代码
import numpy as np
import torch
from models.common import DetectMultiBackend
from utils.general import (non_max_suppression, scale_boxes, xyxy2xywh)
from utils.torch_utils import select_device, time_sync
# 导入letterbox
from utils.augmentations import letterbox
# 参数定义
weights = './yolos.pt' # 权重文件地址 .pt文件
imgsz = (640, 640) # 输入图片的大小 默认640(pixels)
conf_thres = 0.9 # object置信度阈值 默认0.25 用在nms中
iou_thres = 0.9 # 做nms的iou阈值 默认0.45 用在nms中
max_det = 1000 # 每张图片最多的目标数量 用在nms中
device = '0' # 设置代码执行的设备 cuda device, i.e. 0 or 0,1,2,3 or cpu
classes = None # 在nms中是否是只保留某些特定的类 默认是None 就是所有类只要满足条件都可以保留 --class 0, or --class 0 2 3
agnostic_nms = False # 进行nms是否也除去不同类别之间的框 默认False
augment = False # 预测是否也要采用数据增强 TTA 默认False
visualize = False # 特征图可视化 默认FALSE
half = False # 是否使用半精度 Float16 推理 可以缩短推理时间 但是默认是False
dnn = False # 使用OpenCV DNN进行ONNX推理
# 获取设备
device = select_device(device)
def detect_model_load(weights_path):
# 载入模型
model = DetectMultiBackend(weights_path, device=device, dnn=dnn)
return model
@torch.no_grad()
def detect(model,img,conf_thres,iou_thres):
stride, names, pt, jit, onnx, engine = model.stride, model.names, model.pt, model.jit, model.onnx, model.engine
# Run inference
# 开始预测
model.warmup(imgsz=(1, 3, *imgsz)) # warmup
dt, seen = [0.0, 0.0, 0.0], 0
# 对图片进行处理
im0 = img
# Padded resize
im = letterbox(im0, imgsz, stride, auto=pt)[0]
# Convert
im = im.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
im = np.ascontiguousarray(im)
t1 = time_sync()
im = torch.from_numpy(im).to(device)
im = im.half() if half else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
t2 = time_sync()
dt[0] += t2 - t1
# Inference
# 预测
pred = model(im, augment=augment, visualize=visualize)
t3 = time_sync()
dt[1] += t3 - t2
# NMS
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
dt[2] += time_sync() - t3
# 用于存放结果
detections = []
# Process predictions
for i, det in enumerate(pred): # per image 每张图片
seen += 1
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], im0.shape).round()
# Write results
# 写入结果
for *xyxy, conf, cls in reversed(det):
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4))).view(-1).tolist()
xywh = [round(x) for x in xywh]
xywh = [xywh[0] - xywh[2] // 2, xywh[1] - xywh[3] // 2, xywh[2],
xywh[3]] # 检测到目标位置,格式:(left,top,w,h)
cls = names[int(cls)]
conf = float(conf)
detections.append({'class': cls, 'conf': conf, 'position': xywh})
# 推测的时间
# LOGGER.info(f'({(t3 - t2)*1000:.3f}ms)')
return detections
# if __name__ == '__main__':
# img_path = "image/8114.jpg"
# img = cv2.imread(img_path)
# model = detect_model_load()
# print(detect(model,img))
# 使label支持鼠标绘图的自定义组件代码
from PyQt5.QtWidgets import QWidget, QApplication, QLabel
from PyQt5.QtCore import QRect, Qt, QPoint
from PyQt5.QtGui import QImage, QPixmap, QPainter, QPen, QGuiApplication, QPainterPath, QPolygon, QBrush
class DrawBoxLabel(QLabel):
def __init__(self, parent=None):
super(DrawBoxLabel, self).__init__(parent)
self.shapeType = 'polygon' # 默认为矩形,可以是'line', 'rectangle', 'polygon'
self.Line_list = [0, 0, 0, 0]
self.Rectangle_list = [0, 0, 0, 0]
self.Polygon_list = []
self.originalPixmap = None # 保存原始图片的pixmap
self.isEnabledDrawing = False # 控制是否启用画图功能
self.setCursor(Qt.CrossCursor) # 默认设置为十字光标,适用于绘图
def setOriginalPixmap(self, pixmap):
self.originalPixmap = pixmap
self.setPixmap(pixmap)
def mousePressEvent(self, e):
if self.isEnabledDrawing:
# 获取 QLabel 和 pixmap 的尺寸
labelSize = self.size()
if self.pixmap() != None:
pixmapSize = self.originalPixmap.size()
pixmapSize.scale(labelSize, Qt.KeepAspectRatio) # 按比例缩放
# 计算 pixmap 在 QLabel 中的偏移量
xOffset = (labelSize.width() - pixmapSize.width()) // 2
yOffset = (labelSize.height() - pixmapSize.height()) // 2
if e.x()-xOffset > 0 and e.y()-yOffset > 0 and e.x()<pixmapSize.width()+xOffset:
if self.shapeType == "line":
self.Line_list[0] = e.x()-xOffset
self.Line_list[1] = e.y()-yOffset
elif self.shapeType == "rectangle":
self.Rectangle_list[0] = e.x()-xOffset
self.Rectangle_list[1] = e.y()-yOffset
elif self.shapeType == "polygon":
self.Polygon_list.append(e.x()-xOffset)
self.Polygon_list.append(e.y()-yOffset)
self.update()
if e.button() == Qt.RightButton:
self.Line_list = [0, 0, 0, 0]
self.Rectangle_list = [0, 0, 0, 0]
self.Polygon_list.clear()
self.setPixmap(self.originalPixmap) # 更新QLabel的pixmap
self.update()
def mouseReleaseEvent(self, e):
pass
def mouseMoveEvent(self, e):
if self.isEnabledDrawing:
if self.shapeType == "line":
self.Line_list[2] = e.x()
self.Line_list[3] = e.y()
self.update()
elif self.shapeType == "rectangle":
self.Rectangle_list[2] = e.x() - self.Rectangle_list[0]
self.Rectangle_list[3] = e.y() - self.Rectangle_list[1]
self.update()
def paintEvent(self, event):
super().paintEvent(event)
if not self.isEnabledDrawing:
return
if self.pixmap() != None:
pixmap = self.originalPixmap.copy() # 使用原始图片的副本来绘制
painter = QPainter(pixmap)
# painter = QPainter(self)
painter.begin(self)
# 设置绘制形状的边框颜色和宽度
pen = QPen(Qt.red, 2, Qt.SolidLine)
painter.setPen(pen)
if self.shapeType == "line":
painter.drawLine(self.Line_list[0], self.Line_list[1], self.Line_list[2], self.Line_list[3])
elif self.shapeType == "rectangle":
painter.drawRect(self.Rectangle_list[0], self.Rectangle_list[1], self.Rectangle_list[2],
self.Rectangle_list[3])
elif self.shapeType == "polygon":
# 设置绘制点(圆)的填充颜色
painter.setBrush(Qt.blue) # 设置画刷为蓝色用于填充圆
radius = 4 # 圆的半径,用于控制点的大小
# 绘制圆形代替点
for i in range(0, len(self.Polygon_list), 2):
painter.drawEllipse(QPoint(self.Polygon_list[i], self.Polygon_list[i + 1]), radius, radius)
# 绘制线条或多边形时,不填充颜色
painter.setBrush(Qt.NoBrush) # 绘制线条或多边形时不使用填充
# 当点的数量等于4时(即两个点),绘制线条
if len(self.Polygon_list) == 4:
painter.drawLine(self.Polygon_list[0], self.Polygon_list[1], self.Polygon_list[2], self.Polygon_list[3])
# 当点的数量大于等于6时(即至少3个点),绘制多边形
elif len(self.Polygon_list) >= 6:
polygon = QPolygon()
polygon.setPoints(*self.Polygon_list)
painter.drawPolygon(polygon)
painter.end()
self.setPixmap(pixmap) # 更新QLabel的pixmap
def setShapeType(self, shapeType):
self.shapeType = shapeType
self.points = [] # 切换图形类型时重置点列表
self.update()
def enableDrawing(self, enable):
self.isEnabledDrawing = enable
self.updateCursorStyle()
def updateCursorStyle(self):
if self.isEnabledDrawing:
self.setCursor(Qt.CrossCursor)
else:
self.setCursor(Qt.ArrowCursor)
self.update() # Ensure the widget is updated
def enterEvent(self, event):
# When the mouse enters the widget, update the cursor style based on isEnabledDrawing
self.updateCursorStyle()
super().enterEvent(event)
def leaveEvent(self, event):
# Optional: Reset the cursor to the default style when the mouse leaves the widget
# This is optional and can be adjusted based on desired behavior
self.setCursor(Qt.ArrowCursor)
super().leaveEvent(event)
# 视频检测代码
# 检测视频模式
elif mode == 2:
framenum = 0 # 记录帧数
data = {} # 将数据字典的定义移动到这里
# 读入视频
vc = cv2.VideoCapture(file_path) # 读入视频文件
width = int(vc.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(vc.get(cv2.CAP_PROP_FRAME_HEIGHT))
rval, frame = vc.read()
start_time = time.strftime("%Y-%m-%d_%H-%M-%S", time.localtime(time.time()))
fps = vc.get(cv2.CAP_PROP_FPS) # 获取视频原帧率
videoWriter = cv2.VideoWriter(os.path.join(foldername, 'result.mp4'),
cv2.VideoWriter_fourcc('M', 'P', 'E', 'G'), fps, (width, height))
# 设置文字的字体、大小、颜色和粗细
font = cv2.FONT_HERSHEY_SIMPLEX
font_scale = 1.2
font_color = (0, 0, 255)
thickness = 2
text,text_x,text_y = 0,0,0
cycles,drills = 0,0
det_res_after = ""
while rval: # 循环读取视频帧
rval, frame = vc.read()
if rval:
# frame = cv2.resize(frame, (1280,720))
pass
else:
break
# # 开始检测
det_res = detect(model, frame,conf_thres=0.7,iou_thres=0.7) # 检测得到结果
try:
# 根据检测结果画框和中心点
class_name, conf,frame = draw_box(frame, det_res)
except:
logger.error("draw_box NULL")
# 计算戴头盔和不戴头盔的人数
wear = 0
unwear = 0
for index, res in enumerate(det_res):
if res['class'] == 'person':
unwear += 1
elif res['class'] == 'hat':
wear += 1
text = f"wear:{wear} unwear:{unwear}"
text_size, _ = cv2.getTextSize(text, font, font_scale, thickness)
text_x = frame.shape[1] - text_size[0] - 10
text_y = text_size[1] + 20
#
cv2.putText(frame, text, (text_x, text_y), font, font_scale, font_color, thickness)
# 将帧写入视频文件
cv2.imshow("press 'q' to esc",frame)
# 按下q键退出
if cv2.waitKey(1) == ord('q'):
break
videoWriter.write(frame)
framenum += 1
videoWriter.release()
logger.info(f"结果保存在{foldername}文件夹中")
三、结语
该项目为本人原创,以安全帽检测为例进行的展示,亦可通过修改相关图片、图标、以及模型权重文件来自定义目标检测系统。
对该项目有兴趣的同学,或想在此项目基础上进行修改的都可以联系我,会尽我所能为大家提供帮助。
项目地址如下:https://mbd.pub/o/bread/ZZyWk59q















 939
939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









