






1.数据标准化概述
当数据(x)按均值(μ)中心化后,再按标准差(σ)缩放,数据就会服从为均值为0,方差为1的正态分布(即标准正态分布),而这个过程,就叫做数据标准化(Standardization,又称Z-Score normalization)。
- 公式:

1.代码实现
from sklearn.preprocessing import StandardScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler = StandardScaler()
scaler.fit(data)
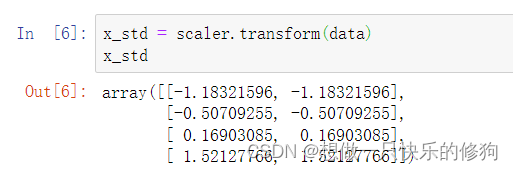
x_std = scaler.transform(data)
print(x_std)
效果:
- 标准化之前的数据:

- 标准化后的数据
【PS】这是我看看sklearn菜菜的视频学习笔记~


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











