







一点就分享系列(理解篇3)Cv任务“新世代”之Transformer(下篇)——“cv领域展开”
提示:本篇内容为下篇,如感兴趣可翻阅上和中篇!
理解篇3 上 transformer-导读理解
理解篇3 中 transformer-cv应用
但是由于transformer的进展惊人的快,故此系列还会继续若干篇,虽迟但到,最近压力拉满,心累补更下transformer系列,同时下篇继续我的yolov5改进中篇分享。
关于transformer的论文实在太多了,目前我在学习的方向:
1.CNN和transformer互相结合
2.纯transformer,改进方向是解决计算问题,轻量化。
首先,自我提示下,干这行的初心是因为兴趣! 一些自己的理解,写在篇尾,同时也是感谢耐心阅读的朋友!
本意是分享理解,其实不管什么论文模型,通过该篇阅读的主要目的是获得如下理解:
1.加深CNN检测模型的理解
2.加深transformer的图像领域理解
3.理解transformer和CNN的区别
4.培养动手实现transformer的能力和灵感
文章目录
DETR-2.0:" Deformable!"为什么要提它?
了解行情的朋友应该明白 ,DETR的诟病太多了,但是不积跬步无以至千里,还是要了解下精髓和思想的,丰富我们的理解。 接档理解篇3中,上篇中我们介绍了DETR的原理,接下来主角自然是Deformable DETR(ICLR2021),相信这里很多CV的同学或者同行都知道可形变卷积:因为传统CNN卷积核的固定形状的,总是在固定位置对输入特征特征进行采样,先讲下我自己的理解,首先基于CNN对物体形变的不足,DCN就是为此而来,使得卷积的域始终覆盖在物体形状的周围,为什么?一、“抛砖引玉”——聊到这里分享下我的理解
继续上个问题,这里我讲下自己的理解:在目标检测中存在1个经典问题:
在检测任务中存在特征不对齐,上面说过了CNN的感受野是固定方形区域,检测的形变能力不强,anchor和feature map不对齐,同时也说明了另一个问题,就是我之前在我的另一个yolov5系列里,提到过——分类和回归的低相关性(尤其在One-stage检测器 )也造成了特征冲突的情况。
那么总结下我现在比较熟序的常规改进手段,围绕一下几点改进:
- 添加特征融合层,如FPN,BIFN,PANET等——缓解特征尺度不一致性的问题;
- 增加分支预测Iou,比如在Head上添加一个新分支预测Iou,如Aware-IOU,同时直接更换或者添加关于Iou损失函数,如LOSS函数(CIOU,DIOU,GIOU,EIOU)—— 本质就是为了解决分类和回归的策略问题,提高了回归精度和分类相关性;
- Guided Anchoring利用语义特征来指导anchor,方法会联合预测感兴趣物体中心可能出现的位置和在不同位置的形状大小。也就是先预测anchor的形状大小及位置,再在这些anchor的基础上预测目标,同时添加基于Anchor的定位损失和形状损失——通过学习得到的anchor去解决anchor和特征不对齐问题
- 改变卷积核的感受野,比如DCN——促进特征对齐,同时根据设计去改善分类和回归的问题
基本都是基于以上思路开始延申做的各种改进,以上4点结合改进的网络模型数不胜数,这里总结下,再复杂的我忘记了哈哈。
二、DETR Deformable(DETR部分一定要结合上篇阅读,DETR系列只做思路解读)
1.DCN
看似没什么关系的讲述,其实就是为了讲述下大背景下的动机,大概对DCN有了感觉现在来简单叙述下:
它对感受野上的每一个点加一个偏移量,偏移的大小是通过学习得来的,偏移后感受野不再是个正方形,而是和物体的实际形状相匹配。这么做无论物体怎么形变,卷积的区域始终覆盖在物体形状。
简明扼要:DCN多了一个描述变换的偏移量,是卷积得到的可学习参数。例如,一个featuremap(C x H x W)卷积后得到一个offset(2C x H x W),维度上2倍是因为offset来自X,Y两个方向的维度,所以是2倍。

Deformavke DETR其实主要就是想解决DETE训练时间长不好收敛且计算复杂度很高,因为DETR对小目标检测能力较差,而现在的检测模型都采用多尺度featuremap来计算,这样越大的featuremap尺度造成了过高的计算量,这点是transformer用在图像领域的“究极痛点”了
而DCN的加入其实就是为了变相去降低self-attention的算力开销和训练收敛的代价:
读过前两篇或者对transformer熟悉的朋友都知道传统的 的每个Q矩阵都会和所有的 K 做attention计算,而dcn版本的detr只使用固定的一小部分 Q与 K 去做attention,所以收敛时间会缩短。
2.Deformable DETR 核心

从结构我们可以看出DETR-Deformable的核心除了算子上使用了DCN,在结构上使用了多尺度特征,那么多尺度的自注意力机制就产生了:
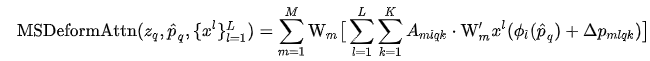
m是heads,L是代表多少个多尺度。Amiqk 代表某一个特征尺度和某个头上的K个采样点的权重,最后则为对应偏移量。
Deformable-多尺度MHSA,所有层均在featureamap上采K个点上(K为每个Q向量的采样点,和上节提到的局部作attention减少计算复杂度对上了),融合不同层的特征,多尺度可变形Self-attention不再需要CNN检测的多尺度级联结构。
故Encoder的输入输出均为多尺度feature map,保持相同的分辨率,输入的多个尺度eaturemap通道数固定为256。
在Decoder的部分:包含两种注意力机制的模块,怎么区分?
它们的Q矩阵向量是来自encoder的输出得到的Object querise,而K矩阵是来自encoder输出得featuremap,记为cross-attention,另一个区别的K矩阵仍旧来自Object querise.这个向量是可学习的,这个还是self-attention模块,在上篇DETR的结构解读中,特意强调过。
对于 cross-attention中使用的正是上面提到的多尺度注意力层。而每一个Object querise通过网络推理后得到的其实是类似于参考点的偏移量,学过检测的不难理解网络的输出吧?
后续DETR又改进了预测不是相对于参考点的差值,而是相对于上一个Decoder Layer的输出的差值;
以及改成two-stage两阶段检测,在一阶段中删除Deocoder简化计算,让Encoder来做ROI的提供,直接预测再给到二阶段来分类;
二阶段中,只用Decoder,应该是为了提高MAP。
DETR到此为止,DETR的结构还是相对复杂,不易工程化,介绍它的原因也是为了让大家了解下其设计思路和一些相关知识,主要原因是有太多优秀的产出了,后续很多都是致力于如何处理transformer的结构,使其计算复杂度降低和更好的迁移结构去适应图像,因此不多赘述了。
三、transformer 时代-经典分类模型VIT(An Image is Worth 16x16 Words:Transformers for Image Recognition at Scale)
上述DETR我个人认为是transformer学习的一个起始点,谷歌出品的视觉transformer,直奔主题,个人认为这篇文章的贡献就是图像的结构处理!将transformer迁移到分类任务上面。作者认为没有必要总是依赖于CNN,只用Transformer也能够在分类任务中表现很好,尤其是在使用大规模训练集的时候。

为什么要讲这个VIT?
对图像的结构处理迁移,对于所有视觉任务以及transformer的设计提供了非常好的基础。
1.图像处理patches-embedding
- 首先对于一个图像(H,W, C)分成固定大小的patchs(这里默认为16),然后通过线性变换得到patch embeddingembedding向量, 这样得到了一个2D的patches(N,16x16xC),每个patches(16x16xC)N=HW / 1616;
- 得到的2D向量,经过一个Linear层变成transformer模块需要的输入(N,D);
- 还没完,VIT这里对patchembedding的向量与定义可学习得class_token进行了concat,后再在代码中也可以看出!
为什么要加Class_token?
个人理解,不负责任:因为VIT的结构简单,从图中我们能发现其结构没有Decoder的部分,那么这个class_token扮演了decoder的Query,去完成分类的预测,即可学习的向量,看过之前的检测transformer的DETR系列我们发现它对应着在检测模型的anchor角色,而同理class_token就是作为寻找分类的角色。
2.positional-embedding
位置编码,老生常谈了。可学习的位置向量,不同的是没用三角函数进行编码,而是直接初始化和patchembedding一样的维度,然后相加得到input tensor。
3.vitTransformer 模块和代码
这里VIT的作者并没有改动原版transformer的模块结构:
ViT做分类任务只用了transformer的encoder来提取特征。对于有transformer基础的人看到这里,其实也明白了VIT的精髓,基本就是这个了,理论上很简单,所以直接上代码注释+理解了!省时间省码字。
class VitTransformer(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):
super().__init__()
assert image_size % patch_size == 0, 'Image dimensions must be divisible by the patch size.'
num_patches = (image_size // patch_size) ** 2 #确定patches数
patch_dim = channels * patch_size ** 2 #计算维度
assert num_patches > MIN_NUM_PATCHES, f'your number of patches ({num_patches}) is way too small for attention to be effective (at least 16). Try decreasing your patch size'
assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
self.patch_size = patch_size
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim)) #直接初始化了位置向量,没有进行三角函数编码
self.patch_to_embedding = nn.Linear(patch_dim, dim) #全连接将patch_dim->dim
self.cls_token = nn.Parameter(torch.randn(1, 1, dim)) #初始化cls——token 一维tensor
self.dropout = nn.Dropout(emb_dropout)
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
self.pool = pool
self.to_latent = nn.Identity()
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, img, mask = None):
p = self.patch_size
x = rearrange(img, 'b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = p, p2 = p)
x = self.patch_to_embedding(x) #完成embdding 改变维度
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b)
#可学习的class tensor,与输入concat在一起
x = torch.cat((cls_tokens, x), dim=1) #(b,n+1,d)
x += self.pos_embedding[:, :(n + 1)] # Positional tensor:(b,n+1,d) 得到transform输入的tensor
x = self.dropout(x)
# transformer的输入维度x的shape是:(b,n+1,d)
x = self.transformer(x, mask)
# (b,1,d)
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
return self.mlp_head(x) # (b,1,num_class)
vit的图像处理方式,为视觉任务下游任务的延伸提供了非常好的基础,在yolov5文章中也有提到图像的transformer修改思路,现在官方git也有个版本,不过那个也并不是最合适的cv transformer版本,我还在自己改造复现中ING,代码还没改好,业务繁忙,最近不少网友私信我,问题我会尽力逐一回应并解决。
看到这里,赠送一些个人理解,可以白嫖!起码点个赞和关注吧!
1.为什么要学transformer?
首先,transformer我是2020年底才接触的,当时吸引我的原因我在第一篇transformer的分享篇中提到过,因为对于我所做的cv下游任务大多都是检测,其实很多业务也都是检测或者检测变体延展的任务,那么我个人觉得anchor或者cnn本事太过僵硬!再上升到人类视觉肯定也不是这么个机制,相比self-attention的机制更符合我们的视觉,说到这里又要提到transformer和cnn的特点以及区别:
cnn:局部感受野,权值共享,下采样;
transformer:全局联系,动态注意力层;
不同点呢?太多了!因为从运算机制和结构来看完全是两个维度的事情!先说些自己的理解:不负责任!
对于图像,在cnn中是由卷积核一层层堆叠,拜cnn上面的特点所赐,可以空间下采样,降低计算量,随着卷积层堆叠,感受野会被放大,那么网络的性能会得到增强(当然不是无限深越好,本质上cnn是需要扩大有效感受野而不是感受野),此时你会发现我们在cv的深度学习领域的很多工作比如残差和bn,激活函数一直在围绕着这个线路,去做一定深度可训练且不容易过饱和的网络模型!
而transformer呢?
1.self-attention是本质内部建立了长期的依赖,其动态的自注意力机制让它可以关注图像全局,而cnn只是局部;
2.transformer核心的注意力机制基于q,k,v的计算 ,本质上是在一个高维度空间做投影建立联系,相比下是否就是对cnn造成了降维打击?cnn本质对于一张图像不考虑时间序列,应该就是一个三维空间,而transform在多个空间建立联系,那么也许cnn只是transform的一种退化?
当然这里要插一下:就是有论文研究说明过:transformer的AS依然离不开残差结构和MLP,这点我也认同,但是相比之下CNN同样离不开残差结构的耦合,所以焦点我们仍可关注于两者,同时也不能忽略残差和MLP的重要性,但说到这里MLP终归也可以认为是一种特殊的1x1卷积,下篇讨论
transformer的问题往往由于self-attention的点积运算造成过大计算量,这也是它设计在cv领域的一大难点,我也多次提到过,现在的很多论文也都是用各种思路和技巧去优化这点!
而不难看出,上述提到cnn和transformer各自特点,隐约觉察到,cnn一直以来的设计和进化是否在致力于达到transformer的特点,cnn在图像领域被发掘的成熟度远远高于transformer,也就是cnn是一个特别努力的选手,但是transformer是个天才选手,还没有被激发出潜能?最近半年的论文产出确定了我需要重新学习transformer的必要!
而transformer也在开始被挖掘中大放异彩,不难看出,现在的研究方向是如何将图像结构更好地迁移到transformer中,同时去设计简化计算量,这两大问题之余,当然还会有很多别的问题等待解决和探索,那么transformer的设计思路也在模仿成熟的cnn设计去进化?比如残差和深度堆积,以及很多大佬们结合cnn图像处理的设计?这是我作为transform初学者的一些学习感悟,欢迎大佬们指点探讨。
最近有部生活类电视剧比较火,五一假期刷了下,确实有点触动,内卷无论是真是假,都给社会行业造成了压力和焦虑,作个不恰当的比喻,但是有助于理解:CNN就像子悠,而transformer就是正在进城路上的米桃~
吐槽
换工程角度说,对于做过模型部署的我可以很负责任的说!确实工程落地永远落后于科研,但是算法模型和工程部署早已经耦合在一起,因为现在还有很多人觉得算法就是算法,工程就是工程,工程考量的概念一定程度上是影响着算法的设计和使用,抠的细致了就是即使上学科研你也得需要数据和算力支持吧?且不说self-attention的计算量,就算是cnn也好,在做网络设计时候普通条件不考虑featuremap大小,那么等待你的不只是算力增加,还有batch降低和爆显存,更别提transformer了,如果把transformer结合进cnn里就知道我为什么这么强调了。对于当今AI算法,抛开数据和算力谈算法完全是纸上谈兵,耍流氓。
针对某些算法同行的质疑!最近遇到了这样一个观念,可能工作履历工程较多,有些纯炼丹选手会质疑你的研究工作,那么我谈一下关于算法模型部署,我说的部署是以我自身工作经历而言,我为什么要提到这个呢?有很多“算法大佬”只是“知道”,这里“知道”和“懂”和“能做”是完全三个概念的事情!我所作的部署除模型转换,还要移植,这里的移植简单来说就是把推理的解码部分+后处理的Python代码换成C++,换成C++就不算是算法了嘛?这是自身工作环境和要求所主导的,况且我作部署是预先训好了模型,我又不是只做部署。。但是从我对这些人的了解,只告诉我这部分专门交给别人作了,那么解析cpp后处理算法自己不实现嘛?在这个行业竞争激烈的阶段,一般的模型炼丹大家都会,扩充自身的技能深度和广度是非常有必要的。都2021年了,还跟我整数据最重要嘛?我不知道数据重要嘛?















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









