






Cv算法工程师的LLM日志(5)大模型主流技术及MOE系列——基于Qwen-moe特别串讲篇
动机
- 今年我写的博客文章都不满意,(原谅标题党)原因是不只是时间和精力不够,LLM这块迭代速度极快,LLAMA3也要出了,在此之前必须要做复盘,更主要转到LLM这个领域后对于代码深度层面以及NLP的一些基础掌握的生疏,尽管现在因为工作需要已经有不少的微调经验,但是源码和细节的掌握终究是差了火候,所以这篇算特别篇,期望能够突破并加深我和读者们对LLM基础原理的认知和理解。故以MOE系列的Qwen-moe代码进行细节讲解,同时考虑到MOE相关文章很多了,其结构以及基本思想算是比较简单明确,所以不想过多重述了,想做细节一点,最合适的方式就是上代码和自己的理解,整篇模型源码都会进行解读和逐个原理解析。
- 选择Qwen原因主要是我用qwen各种训练方式的次数比较多,其次作为国内优秀的开源大模型也处于比较快速的迭代中(上周开源32B了),QWEN1.5中也是明着在注释中指出参考了Mistral系列和llama系列,所以本文借此qwen源码直接打通LLM模型基础(事实上市面上9成的开源大模型结构和以及附带的技巧都源于llama2和Mistral系列,所以其实你只要找一个靠谱的开源大模型研究明白,9成的基础原理你也能明白了),其中涉及到的不仅仅是MOE技术,还包含现在开源LLM的主流技术,而且看QWEN-MOE篇,也就是等同于看了所有主流LLM的原理,所以这一篇打通LLM技术并不是胡说,懂的自然懂,全程干货持续更新,内容比较多可能不会一下子全部更出来,会以图文代码三方面去解读分享,读者们的点赞关注收藏是加速更新的动力,感谢阅读。(今天是清明节假记录开更时间2024-4-7)
阅读收获:
理解主流的MOE系列(Done)
理解主流LLM技术技术(TO DO)
具备自己从零构建大模型代码能力(没数据算力和时间别想了,可以自己搜集也不是不行),但是从1做成本小很多,具体不便多说,稍微有实践经验的从业者都明白。
文章目录
前言
去年随着mistral AI 和 deepseek 的MOE架构展现在大众面前,这个架构也开始逐渐普及,今年mask的gork系列和qwen1.5-MoeA2.7B-Chat也随之而来,相信大家都不陌生‘混合专家网络’这个名词,这种架构的研究并不是一蹴而就,最早90年代就有学者提出了这个研究,而随着大模型的热潮,这一架构技术的有效证明又使得其热度飙升,我们首先简单讲一下moe的基本思想:
就是基于现有的LLM模型架构上,其每个deocoder层的“MLP Block”变成稀疏的MOE的多个分支结构,这些分支即为专家Expert,通过其第一层的Gate layer后选择应该激活哪个或哪几个expert计算,因此只在这个部分是独立的多个专家分支(严谨点并不是N个模型,非要这么说也不是不可以,但其实个人觉得只是一个叠加的门控概率稀疏模型),这样对于多任务的推理可能有更好的效果,这种稀疏结构针对于不同领域的学习可能每个experts各有侧重,具备更多可能性把,但是也存在experts一多不好平衡管理的问题,因此要用负载均衡机制去动态管理。
注意:下面开始正文的代码和原理会绑定叙述,最终全部代码注释版我会上传到云盘可自行下载(当前未上传)
一. MOE-BLOCK
1.原理简介
首先补充一点,MOE基于上述的基本原理上,有不同的方法,但主要是基于负载均衡改进的为目前主流方式,所以一通百通。
如下图,最明显的改动是MLP(多个线性linera层和激活函数)Block变成MOE-MLP的稀疏Block,由以下组成(qwen的MLP照搬的Mistral MLP):
- gate layer, 门控线性层
- experts,多个专家路由表,每个专家都是一个MLP
- 加权操作和共享专家线性映射(这里每个开源模型计算细节略有不同,但是差距不会很大,也是很多文章都没有仔细提及的),所以下面的图仅仅只是帮你理解而已,还不够细节,仅作为概念图而已!
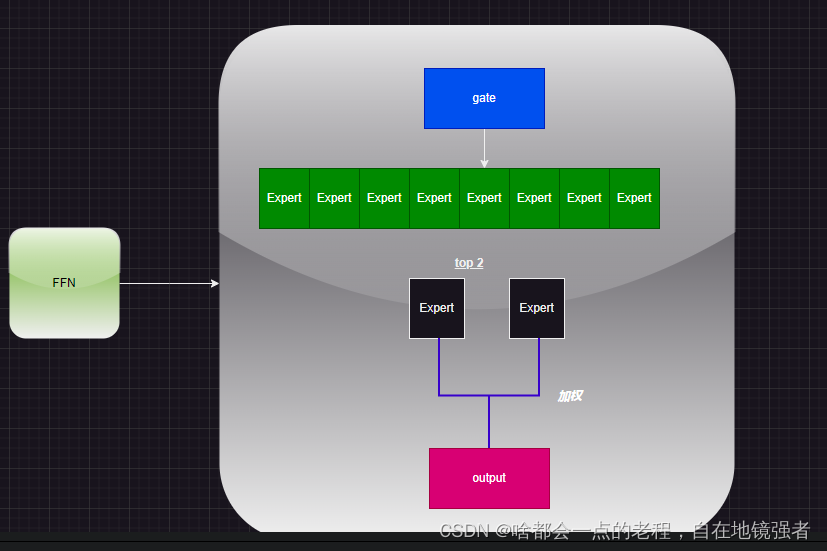
2. “真block结构”解析——图文结合解答你所有疑惑!(千问的MOE和Mistral这块有什么不同)
这里不饶圈子了,QWEN的MOE模块代码是基于Mixtral作的调整再进一步地,其实呢差别主要在最后尾部的处理,说到这里顺便也是等价于把Mixtral的mOE给过一遍,我们放代码之前先放根据代码画的”真结构图“:(注意MOE的MLP都带有gate调节因子的MLP)

上图基于QWEN-MOE的block代码绘制(如有错误,还请指正),那么现在自问自答小标题问题,QWEN和Mixtral的Moe有什么具体不同?(排除专家数和topk等模型配置参数的设定,qwen其实是60,4,这个不影响原理)
答:有,真相就在图中,我特意将上图按照stage划分为了三块区域,如果对Moe代码有过阅读的你,答案已经显而易见了,我先简单卖个关子,因为先展示图文结合,所以基于上述的所有,我们再用文字简述上图的步骤:
-
获取输入 hidden_states 的维度信息:批次大小 batch_size、序列长度 sequence_length 和隐藏层维度hidden_dim。 将 hidden_states 展平为二维张量,形状为 (batch_size *sequence_length, hidden_dim)。
-
通过 self.gate 计算门控分数(router_logits),形状为 (batch_size * sequence_length, num_experts)。 使用softmax 函数计算每个专家的权重,并选择权重最高的 top_k 个专家及其索引。 如果 norm_topk_prob为真,则对选定的专家权重进行归一化处理。
-
创建一个全零张量 final_hidden_states,用于存储最终的隐藏状态。
-
通过one-hot 编码和转置操作创建专家掩码 expert_mask。 对应图中的expertmask,.这是非常重要的操作,决定了有效处理token的分配表。
-
遍历所有专家
通过掩码找到分配给当前专家的token 索引。
如果没有 token 分配给当前专家,则跳过。
从 hidden_states 中索引出相应的 token并reshape形状。
将 token 通过专家层 expert_layer 并乘以权重 routing_weights。
使用index_add_ 方法将计算结果累加到 final_hidden_states 中。 -
计算共享专家层的输出,并使用门控层self.shared_expert_gate 控制其对最终输出的贡献。
-
将共享专家层的输出与专家层的输出相结合,得到最终的隐藏状态。
-
将最终的隐藏状态改为原始输入的维度并返回,同时返回路由分数 router_logits。
解析点一:Qwen moe"不同之处":
仅个人理解:其实,接着上面没回答完的问题继续,上图中分为了Stage1\2\3并和上述8个步骤相对应,那么很容易看出Stage1+Stage2(前5个步骤)=Mixtral MOE, 那么QWEN MOE其实只是多了图中的stage3(步骤6,7,8),目的是将专家处理后的信息与共享专家处理后的信息结合起来,以获得更丰富和更全面的表示,你说结构有什么创新吗?你说你能想到并实现吗?这其实就是添加了一个“共享专家”的MLP和Linear层作类似resnet的shortcut,(首先我并没有看任何关于QWEN的解读比如知乎文章,单纯从自己和代码角度去理解构思的,不然我会被文章又带入那种所谓的”学者模式“!就是(“XXX"对Mixtral的moe进行了"xxx创新性改进”,实验证明我们很成功,对你真正理解东西和思考其实没什么帮助),可以告诉你95%的LLM基础技术都有llama和mistral系列的产物,但是呢,你没在人家的平台也没人家的业务和算力数据支持,干看着就好了(说到这里突然很好奇Kimi对注意力机制有什么特殊的技术),你可以不干,但是不能不知道!因此学QWEN-MOE和跟你看Mixtral moe本质没任何区别,这篇文章不仅针对QWEN,再次强调!
额外的,千问的模型配置不同,比如qwen的moe-A2.7B-chat默认60个专家且每个token由4个专家处理,有24层。
解析点二:moe"易混淆问题":
1.什么多个模型和参数量这种问题,就不解释了,2024年了还有人分不清这是几个模型。 2.重点来了!先铺垫一下,上述图和文都有关键步骤专家分配这个问题,这是MOE设计的一个难题,多个专家分支的分配问题,避免某些专家过载而其他专家闲置的情况。因此做出了几个设计:
门控gate计算:通过 self.gate 线性层计算每个 token 对所有专家的门控分数。这个分数反映了每个专家处理特定 token
的能力或适合度。权重归一化:使用 softmax 函数对门控分数进行归一化,得到每个专家对每个 token
的处理权重。这一步骤确保了所有专家的权重之和为 1,从而使得每个 token 的处理可以均匀地分配给不同的专家。选择 Top-K 专家:通过 torch.topk 函数选择每个 token 对应的权重最高的 top_k
个专家。这个操作有助于集中计算资源处理最重要的专家,同时保持了专家之间的负载均衡。权重应用:对于每个选定的专家,只有分配给它的 token 才会被送入对应的专家层进行处理。这样,每个专家只需要处理一部分
token,从而实现了负载均衡。共享专家层(qwen-moe 的):除了专门的专家层之外,还有一个共享专家层对所有 token
进行处理。这一层可以捕捉通用的特征,并且其输出与专家层的输出相结合。共享专家层的存在减轻了单个专家层的负担,进一步促进了
这些都已经体现在MOE的代码块中,除此外还有一个MOE专用的负载均衡loss,深度学习设计自古就是你有新的head必有其新loss!改了YOLO几十个版本的我深谙此道!
铺垫足够了,这里有一些喜欢阅读代码的读者会在看代码后有些疑惑,(注释代码块我放在了下节,这里我直接说问题),在实际过程中,’‘MOE是否所有专家分支都参与计算了吗?“,如果你直接看代码For循环遍历专家,可能有一部分人会陷入误区,就是看起来所有专家都参与了运行?这和说的只有TOP_K的不是矛盾吗?看了代码的人有的人就会觉得是MOE所有部分其实都参与运算了,但是和其稀疏结构理论叙述是有区别的,这点我为什么会提呢?无意在某站一个程序员UP的分享上看到了这个争论,觉得有意思,话不多说,如果有此疑问,那就来,我们掰扯清楚!
小插曲----简单打印下:
随便写个脚本:
在这里插入代码片
# 假设的配置
class Config:
def __init__(self):
self.num_experts = 8
self.num_experts_per_tok = 2
self.norm_topk_prob = True
self.hidden_size = 2
self.moe_intermediate_size = 209
self.shared_expert_intermediate_size = 20
# 检查是否有可用的GPU
if torch.cuda.is_available():
device = torch.device("cuda")
else:
device = torch.device("cpu")
# 创建模型实例
config = Config()
model = Qwen2MoeSparseMoeBlock(config).to(device)
#print(no_work_experts)
## 创建一个输入张量并移动到GPU
input_tensor = torch.randn(1,3,2).to(device)
# 前向传播
output = model(input_tensor)
print(output)
打印一下:
Expert 0: 分配的 Tokens [0, 2]
Expert 1: 分配的 Tokens []
没有分配:no work expert
Expert 2: 分配的 Tokens []
没有分配:no work expert
Expert 3: 分配的 Tokens []
没有分配:no work expert
Expert 4: 分配的 Tokens [1]
Expert 5: 分配的 Tokens []
没有分配:no work expert
Expert 6: 分配的 Tokens []
没有分配:no work expert
Expert 7: 分配的 Tokens [0, 1, 2]
tensor([[[-0.1388, -0.2245],
[-0.1956, -0.2786],
[ 0.1771, -0.0042]]], device='cuda:0', grad_fn=<ViewBackward0>)
可以看到8个专家,有5个专家分配到了,3个专家没有参与后续计算,所以你在实际运行中,出现全部参与和未全部参与都是随机的,随着batch和length长度增加,这个全部参与的概率其实会增加(不严谨)。
答:严格来说,每一个token是会分配top—k 个专家,所以对于当前的一个token只会存在至多top_k个专家!这是稀疏结构的核心,减少了运算量,但是为什么有人会说”moe所有的分支都参与了运算“,那是在实际运算中,一个Batch或者多个Batch内的多个token都会参与,届时代码中是按专家遍历的,为什么,因为以专家为基数效率高且并行处理了所有专家的分配token情况,针对每个专家看看是否有分配好的token处理,这时候对应关系是:一个专家对应的token数并不是一个明确范围的,因为每个token都有可能”有自己的top k"个专家,所以token对应k个专家,而专家则对应0或者更多的token,你跑代码时候因为是长token所以很容易出现所有专家都参与计算的“情况”,这也对应了负载均衡的核心,就是希望所有专家都能够参与!因此这个说法只能说不严谨,你要非分对错,那就要加个条件,考虑一个token单位级别情况下确实是不准确。
3. 详细注释的代码块
代码注释写的很详细了,看了上面内容,代码不可能看不明白的!
这块代码除了Moe的不同之处基本就是Mistral的代码块了
ACT2CLS = {
"gelu": GELUActivation,
"gelu_10": (ClippedGELUActivation, {"min": -10, "max": 10}), #输出值的范围被限制在 -10 到 10 之间。
"gelu_fast": FastGELUActivation, #性能更好的GELU
"gelu_new": NewGELUActivation,
"gelu_python": (GELUActivation, {"use_gelu_python": True}),
"gelu_pytorch_tanh": PytorchGELUTanh,
"gelu_accurate": AccurateGELUActivation,
"laplace": LaplaceActivation,
"leaky_relu": nn.LeakyReLU,
"linear": LinearActivation,
"mish": MishActivation,
"quick_gelu": QuickGELUActivation,
"relu": nn.ReLU,
"relu2": ReLUSquaredActivation,
"relu6": nn.ReLU6,
"sigmoid": nn.Sigmoid,
"silu": nn.SiLU,
"swish": nn.SiLU,
"tanh": nn.Tanh,
}
ACT2FN = ClassInstantier(ACT2CLS)
# Modified from transformers.models.mistral.modeling_mistral.MistralMLP with Mistral->Qwen2Moe
class Qwen2MoeMLP(nn.Module):
def __init__(self, config, intermediate_size=None):
super().__init__()
self.config = config
self.hidden_size = config.hidden_size # 原始出入维度
self.intermediate_size = intermediate_size #中间层学习特征
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False) #从 hidden_size 到 intermediate_size 的投影层
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False) #从 hidden_size 到 intermediate_size 的投影层,用于将输入数据映射到中间维度。
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False) #从 intermediate_size 回到 hidden_size 的投影层,用于将中间维度的数据映射回原始维度。
self.act_fn = ACT2FN[config.hidden_act] #这是一个激活函数字典,里面一堆激活函数,这里默认用silu,贴上面了
def forward(self, x):
return self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x)) #门控激活后作为调节因子 *上投影后的特征输出后,再经过压缩映射回原始维度,就是MLP没什么好说的
class Qwen2MoeSparseMoeBlock(nn.Module):
def __init__(self, config):
super().__init__()
self.num_experts = config.num_experts #根据配置不同 官方默认60个
self.top_k = config.num_experts_per_tok # 4
self.norm_topk_prob = config.norm_topk_prob #bool
# gating
self.gate = nn.Linear(config.hidden_size, config.num_experts, bias=False) #门控线性层
self.experts = nn.ModuleList( #N个NLP专家层
[Qwen2MoeMLP(config, intermediate_size=config.moe_intermediate_size) for _ in range(self.num_experts)]
)
self.shared_expert = Qwen2MoeMLP(config, intermediate_size=config.shared_expert_intermediate_size) #共享专家MLP
self.shared_expert_gate = torch.nn.Linear(config.hidden_size, 1, bias=False) #用来计算门控权重
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
""" """
batch_size, sequence_length, hidden_dim = hidden_states.shape # 取维度属性
hidden_states = hidden_states.view(-1, hidden_dim) # 展平
# router_logits: (batch * sequence_length, n_experts)
router_logits = self.gate(hidden_states) # 拿到N个专家输出
routing_weights = F.softmax(router_logits, dim=1, dtype=torch.float) #得到8个专家的输出概率,即权重
routing_weights, selected_experts = torch.topk(routing_weights, self.top_k, dim=-1) #选K个专家,包含所选专家的索引的tensor
if self.norm_topk_prob:
routing_weights /= routing_weights.sum(dim=-1, keepdim=True) #归一化
# we cast back to the input dtype
routing_weights = routing_weights.to(hidden_states.dtype) #对齐数据类型
# 定义输出层
final_hidden_states = torch.zeros(
(batch_size * sequence_length, hidden_dim), dtype=hidden_states.dtype, device=hidden_states.device
)
# One hot encode the selected experts to create an expert mask
# this will be used to easily index which expert is going to be sollicitated
expert_mask = torch.nn.functional.one_hot(selected_experts, num_classes=self.num_experts).permute(2, 1, 0)#每行代表一个token,每列代表一个专家,作为分配token的查询表
# Loop over all available experts in the model and perform the computation on each expert
for expert_idx in range(self.num_experts): #遍历每个专家
expert_layer = self.experts[expert_idx] #取N个专家层中的一个
idx, top_x = torch.where(expert_mask[expert_idx]) #通过专家掩码找到TOP X,分配给当前专家的token索引位置
if top_x.shape[0] == 0: #表示没有token分配,调到下一个专家
continue
# Index the correct hidden states and compute the expert hidden state for
# the current expert. We need to make sure to multiply the output hidden
# states by `routing_weights` on the corresponding tokens (top-1 and top-2)
current_state = hidden_states[None, top_x].reshape(-1, hidden_dim) #取topx索引并改变形状
current_hidden_states = expert_layer(current_state) * routing_weights[top_x, idx, None] #经过MLP和专家权重相乘
# However `index_add_` only support torch tensors for indexing so we'll use
# the `top_x` tensor here. top_x 张量指定了 final_hidden_states 中应该进行加法操作的位置,
# 而current_hidden_states 张量包含了要加的值。因此,index_add_ 方法会将 current_hidden_states 张量的值加到 final_hidden_states 张量的指定位置上。
final_hidden_states.index_add_(0, top_x, current_hidden_states.to(hidden_states.dtype)) #添加到专家处理的输出上
shared_expert_output = self.shared_expert(hidden_states) #共享专家计算:再对原始输入进行MLP
shared_expert_output = F.sigmoid(self.shared_expert_gate(hidden_states)) * shared_expert_output #是控制共享专家的输出对最终结果的贡献度 x共享专家输出
final_hidden_states = final_hidden_states + shared_expert_output #享专家处理后的信息与多个专家处理后的信息相结合,更丰富和更全面的表示
final_hidden_states = final_hidden_states.reshape(batch_size, sequence_length, hidden_dim) #reshape成原始输入的维度
return final_hidden_states, router_logits
通过图+文+代码和解释,相信你已经彻底明白了MOE的设计,还请点赞关注收藏,后面只会越来越精彩。
二、Moe的负载均衡LOSS(4月8号更新完成)
接力第一章我们所讲,自然而然有了新的结构,那就有基于MOE的辅助损失函数,来为负载均衡提供梯度更新的参数学习,为什么实现呢?可以概括:不让概率高的专家通吃,所以需要作一个量化指标LOSS,该函数就是如何设计和计算这个目标函数,去使得专家之间的路由分配到的处理token更加均匀,正所谓“不患寡而患不均”。可以看下面的代码注释写的比较详细了,这里我们再梳理下这个代码的实现步骤,帮助读者加深记忆:
# Copied from transformers.models.mixtral.modeling_mixtral.load_balancing_loss_func
# 基于MOE的辅助损失函数,目的是实现负载均衡,参考了switch transformer,避免出现概率高的专家在一直作为被选中的路由专家,而忽略其他专家分支。
def load_balancing_loss_func(
gate_logits: torch.Tensor, num_experts: torch.Tensor = None, top_k=2, attention_mask: Optional[torch.Tensor] = None
) -> float:
r"""
Computes auxiliary load balancing loss as in Switch Transformer - implemented in Pytorch.
See Switch Transformer (https://arxiv.org/abs/2101.03961) for more details. This function implements the loss
function presented in equations (4) - (6) of the paper. It aims at penalizing cases where the routing between
experts is too unbalanced.
Args:
gate_logits (Union[`torch.Tensor`, Tuple[torch.Tensor]):
Logits from the `gate`, should be a tuple of model.config.num_hidden_layers tensors of
shape [batch_size X sequence_length, num_experts].
attention_mask (`torch.Tensor`, None):
The attention_mask used in forward function
shape [batch_size X sequence_length] if not None.
num_experts (`int`, *optional*):
Number of experts
Returns:
The auxiliary loss.
"""
if gate_logits is None or not isinstance(gate_logits, tuple):
return 0
r"""输入的门控逻辑tensor是24x[batch_size X sequence_length, num_experts] 的元组"""
if isinstance(gate_logits, tuple): #一般多组专家时候,通常是元组形式
compute_device = gate_logits[0].device #分配上层的计算设备
concatenated_gate_logits = torch.cat([layer_gate.to(compute_device) for layer_gate in gate_logits], dim=0) #拼接所有的门控逻辑层tensor
routing_weights = torch.nn.functional.softmax(concatenated_gate_logits, dim=-1) #softmax得到每个token对应每个专家的概率,dim=-1 最后一维表示专家数量维度上
_, selected_experts = torch.topk(routing_weights, top_k, dim=-1) #排序取前K=4个概率最大的索引
expert_mask = torch.nn.functional.one_hot(selected_experts, num_experts) #对选择的专家作one-hot编码,离散化成概率矩阵,每一行代表一个token的K个专家路由选择,维度(K,专家数量(60))
if attention_mask is None: #推理阶段
# Compute the percentage of tokens routed to each experts
tokens_per_expert = torch.mean(expert_mask.float(), dim=0) # 计算每个专家分配的token的比例
# Compute the average probability of routing to these experts
router_prob_per_expert = torch.mean(routing_weights, dim=0) # 计算将这些专家作为选中路由的平均概率
else: #训练阶段
batch_size, sequence_length = attention_mask.shape #[batch_size X sequence_length]
num_hidden_layers = concatenated_gate_logits.shape[0] // (batch_size * sequence_length) #根据注意力掩码 计算隐藏层数量,也就是每层门控逻辑的tensor的形状都是[batch_size X sequence_length]
# 计算所有专家路由掩码:与注意力掩码具有相同形状的掩码,将所有填充令牌掩码为0,计算时候去忽略填充的位置
# Compute the mask that masks all padding tokens as 0 with the same shape of expert_mask
expert_attention_mask = (
attention_mask[None, :, :, None, None]
.expand((num_hidden_layers, batch_size, sequence_length, top_k, num_experts))
.reshape(-1, top_k, num_experts)
.to(compute_device)
)
# Compute the percentage of tokens routed to each experts 计算每个专家路由分配token数的比例
tokens_per_expert = torch.sum(expert_mask.float() * expert_attention_mask, dim=0) / torch.sum(
expert_attention_mask, dim=0
)
"""
Compute the mask that masks all padding tokens as 0 with the same shape of tokens_per_expert
计算每个专家的路由掩码"""
router_per_expert_attention_mask = (
attention_mask[None, :, :, None]
.expand((num_hidden_layers, batch_size, sequence_length, num_experts))
.reshape(-1, num_experts)
.to(compute_device)
)
"""
表示每个专家的路由概率:根据上述的每个token对应的所有专家的概率 x每个专家的平均路由概率的掩码后,结果累加和
得到后每个专家的有效token路由权重,再除以每个专家(平均路由)的掩码和,得到每个专家的路由概率
Compute the average probability of routing to these experts """
router_prob_per_expert = torch.sum(routing_weights * router_per_expert_attention_mask, dim=0) / torch.sum(
router_per_expert_attention_mask, dim=0
)
r"""
1.每个专家的分配的token比例与每个专家路由抽到的概率 (逐元素相乘在求和),作为负载平衡损失
2.相乘——这样高概率但低分配或低概率但高分配的情况都会被放大,从而在求和时对不平衡的路由分配给予更高的惩罚。这种放大效应有助于模型学习更均匀地分配 token 到每个专家,避免某些专家过载而其他专家闲置。
求和——为了让所有专家的不平程度加权合并,变成一个整体度量。
3.总之,该loss值可以量化专家之间的不平衡程度,希望均匀分配token每个专家而不是忽略其他专家分支,缩小该值才能保证均匀分配。
4.num_experts作为一个缩放因子,确保损失值与专家的数量成比例,使得它对于不同数量的专家配置都是有效的"""
overall_loss = torch.sum(tokens_per_expert * router_prob_per_expert.unsqueeze(0))
return overall_loss * num_experts
到这里其实MOE的核心模块(门控设计——动态平衡的实现)就讲完了,但是这只是‘冰山一角’,剩下的其实是QWEN结合主流LLM技术的代码部分了。
三、模型主干部分串讲(因为llama3炒作热度暂停几天更新,在作一些有趣的实验)
1. 模型pipeline
待更待修订,点赞收藏评论 ,更新速度++有错误和问题欢迎指正和交流 (画图解析和整理代码太费时间)
例如:其余的代码部分,包含主流的GQA.SWA\RMS技术和QWEN代码主干和总LOSS。
















 1875
1875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









