









一点就分享系列(实践篇5-补更篇)[迟到补发]—Yolo系列算法开源项目融入V8旨在研究和兼容使用[持续更新]
题外话
[最近一直在研究开放多模态泛化模型的应用事情,所以这部分内容会更新慢一些,文章和GITGUB更新并不同步,git基本都是第一时间更新,感兴趣可以跟进研究和PR]去年我一直复读机式强调High_level在工业界已经饱和的情况,目的是呼吁更多人看准自己,不管是数字孪生交叉领域,还是chatGPT等大模型热点,大家都应该去延申自己研究方向和工程技能栈,事实证明这判断完全符合趋势,但也并不是说基础的检测、分割等任务没有研究和学习的意义。言归正传,之所以才更博主要原因是去年开始我就接触了一些交叉方向以及快速工程落地任务,导致个人时间完全没有,所以没有做到春节把代码上传。
在yolov8刚出时候我就加进了项目github,实不相瞒,甚至第一时间并没有仔细看V8的Readme和创新点,下意识觉得无非就是这些,事实上确实也是,出乎我意料的就是anchor-free和新的代码结构,于是打算沿用V5代码风格融进去并完全兼容,而且一直跟检测的同学也会觉得V5代码风格很亲切。一番修改后确实差不多了,但唯独训练的时候发生了问题,后大致定位到是用V5的数据处理结构存在问题,可同时我身兼多个业务的项目指标,压力拉满,毕竟要以工作业务为主,同时考虑作者习惯不停更新代码,所以我只完全把V8的anchor-free结构和V5的anchor-base代码风格程序上兼容通用,其余所有的训练和推理部分都是使用的V8代码,命名为yolo文件夹,可分离使用,这种做法看来是临时的,同时发现官方参数文件中标注V5数据读取处理是标识debug状态的,大概和我估计的问题一致就收手了,且不确定是否全部整理成V5风格还是V8风格,先暂定同步V8仓库做代码相关的整合适配,这些和算法创新无关,已经上传到了项目地址:https://github.com/positive666/yolo_research上,如有使用问题也属正常!可以提出来最好挂iussue上我会尽快解决和回复,那么今天开始更文章补补欠的债并持续更新优化代码,不过由于工作节奏太快更新会较慢,还望各位读者见谅【开始不定时文字补更,一是因为拖延卖课的”剽窃“,虽然没什么用了,二是因为这边工作方向较多,感兴趣的可以关注,还是那句话当今不论科研还是工业,只做检测对自己其实没什么太多收益,本人也并非靠这个盈利,从20年迭代至今,没有获取过一分钱的利益,暂定断档不定时更新】
项目跟进近期实时版块[同步GIT更新情况(目前以代码更新维护为主,文章内容更新会比较慢)】
⭐近期实时更新板块【实时更新版块】
- 2023/5/15 更新来自ultralytics的rt-detr模型和数据增强mosica9,工程还存在不少问题和优化工作,不影响使用前提下,会业余花时间会慢慢更新。
- 2023/4/27 添加一键批量自动生成标注的工具You Only click Once ,[Prompt-Can-Anything:Auto label tools](https://github.com/positive666/Prompt-Can-Anything)
- 2023/4/6 从2021年到2023年,即使不做检测,依然坚持更新,搬砖不易,后续会有更多更新,但是目前先集成稳定各个功能为主:更新v8的pose模块,支持v8代码训练自定义的网络结构并加载权重训练;之前的问题作个简单解释:就是在安装源码环境后其实只是支持你解析官方的预训练权重,如果你用本项目的代码训练后,可以卸载掉源码环境,继续更新中
- 2023/3/28 同步兼容最新的V8代码更新:目前V8依赖于pip install ultralytics,我在代码更新中也发现了该问题,虽然本项目做了分离,但是使用官方权重作为预训练权重去加载的前提下:仍然需要依赖中的ultralytics.nn文件夹,不然可能会报错,因为是这样的本项目改了模型层的参数名字,因为V8每层的名字是带“ultralytics.nn ”的,如果不安装这个部分代码,你torch打不开V8官方的权重,故目前两种解决办法:1.scratch 2.pip安装后打开将权重名字重构 3.代码目录修改 后续我会优化解决,不过目前项目中的工作太多了,故如果出现报错还是使用临时解决方案:pip install ultralytics,这样比较简单直接兼容,然后可以运行 python train_v8.py ,未解决的就是如果自定义机构可能无法直接加载官方的权重,汇后续解决!
- 2023/3/1 add v8 core:春节期间看V8,由于近半年项目比较多也是耽误了好久(原版本是将V8的所有功能全部融合到了V5的代码中,和V8命令一样,但是训练的时候发生了问题,排查发现问题发生在V5的数据读取处理,所以暂时使用V8的训练结构代码,也便于区分),然后抓紧时间不停更新;
- 2022/11/23 修复已知BUG,V7.0版本更新兼容,年底比较忙后续忙完业务会大更新
- 2022/10/20 修复适配V7结构和额外任务引起的一些代码问题,实时更新V5的代码优化部分,添加了工具grad_cam在tools目录。
- 2022/9/19 修复已知BUG,更新了实时的V5BUG修复和代码优化融合验证,核心检测、分类、分割的部分CI验证,关键点检测实测训练正常,基本功能整理完毕。
- 2022/9/15 分类、检测、分割、关键点检测基本整合完毕,工程结构精简化中,关键点检测训练正常已经验证,分割待调试,火速迭代中
- 分割代码结合V5和V7的代码进行了合并DEBUG调试,训练部分待验证,另外注意力层训练过程中,没法收敛或者NAN的情况,排除代码问题,需要在超参数YAML里,先对学习衰减率从改为0.2 ,比如GAM的注意力头部问题,训练周期加到400epoch+ 就可以。
- 去年的decoupled结构虽然能提点,不过FLOPS增加的太多,目前用V5作者分支的解耦头替换,效果待验证。
- 融合了代码做了部分的优化,这里看了下V7的代码优化较差,后续会集成精简版本的分类、分割、检测、POSE检测的结构,目前已经完成了一部分工作,更新频繁有问题欢迎反馈和提供实验结果。
文章目录
工程结构目录和总结
本项目于2021年年初发布:工作之余的“乐趣”,旨在研究学习为主。目前包含检测、分割、分类、关键点检测等主流的经典视觉任务,以yolov5代码风格为主,兼顾anchor-free和anchor-base检测器,加入YOLOV7\YOLOV8的核心,同时保留所有的改动:提供多个算子结构,CNN系列注意力插件、transformer注意力模块、网络的Neck、Head、Loss等供研究者自由组建实验探索,额外提供修改框架的思路在往期文章中查询,“授人与鱼不如授人与渔”,平时比较繁忙但会坚持定期同步更新所有官方的工程优化,目前以稳定性和代码优化为主,后续会抽空逐步进行补充说明和优化。
项目地址:https://github.com/positive666/yolo_research
同步更新V8的代码优化工作,目前V8依赖于pip install ultralytics,我在代码更新中也发现了该问题,虽然本项目做了分离,但是仍然需要依赖中的ultralytics.nn 文件夹,不然可能会报错,这点官方的代码中的Warning也给出了说明后期会优化,我也会想办法解决,不过目前项目中需要的工作太多了,故如果出现报错还是使用临时解决方案:pip install ultralytics,安装包后再使用命令运行。
代码风格是以model.py为共同定义和解析网络结构为基础,支持自由定义所有注册的网络结构模型,组件;拓展yolov8 文件夹作为V8部分可独立使用。因为目前支持了anchor-free,工程稍显复杂,可以关注前些年的往期文章,之前介绍过了几次通用修改思路,后面的章节我会以项目的yolov8加入GhostnetV2作为补充案例说明.
往期文章
一点就分享系列(实践篇5-上篇)
一点就分享系列(实践篇5-下篇)
项目地址,以V5代码为基础,新添加了临时版本的V8部分:https://github.com/positive666/yolo_research
yolo_research(待优化)
│ pose
│ └───── ## 关键点检测任务使用
│ ...
│ models ## 存储模型:算子定义和所有模型的yaml结构定义,包含yolov5\yolov7\yolov8的检测、分割、分类、关键点、 更新加入Rt-DETR
└───── common.py 模型算子定义
yolo.py 模型结构定义
│ └───── cls 分类模型结构
│ pose 关键点模型结构
│ segment 分割模型结构
│ detect v5u_cfg/v7——cfg/v8_cfg 检测模型结构..其余是V5版本以及一些改的参考示例
│ ....
│ segment
│ └───── ## 分割任务
| classify
│ └───── ## 分类任务
| tracker
│ └───── ## 跟踪任务 Fork V8
| rt-detr
│ └───── ## 来自百度的SOTA检测器
│
│
│ utils
│ └───── #通用部分代码
| .
| .
| segment ##分割的数据处理操作部分
| yolo ##yolov8的所有内容和工程代码
│ └───── v8 ## yolov8 core ,主要包含训练部分和推理使用部分的相关代码
│ └───── .
| cfg ## default.yaml 设置所有V8相关参数
| engine ## 定义基类结构
| utils
| data
| tools .
| .
| .
| . ##其余为检测核心代码和工程通用部分
如果耐心看完开篇的闲言碎语,大概能理解这个目前的结构,且也不是我最终的规划,简而言之:目前在该仓库yolov_high_level基础上,加入yolov8的部分,保持以前V5部分,目前逻辑:所有v5.v8所有的模型结构的定义和解析分还是全部集中在model.py中,但是V8还是在独立的文件下可以单独使用,V5也是;(官方的yolov8通过pip install 命令将源码安装在了你的conda环境下,因此可以使用官方命令)
使用说明简介
方式一、使用V8的官方命令解析
如果你使用了官方推荐的pip安装,源码就会在你的conda环境下,那么可以使用如下的官方命令
yolo task=detect mode=train data=<data.yaml path> model=yolov8n.pt args...
classify predict coco-128.yaml yolov8n-cls.yaml args...
segment val yolov8n-seg.yaml args...
export yolov8n.pt format=onnx args...
ps: if your model=*.yaml -->scratch else use pretrained models
官方也提供示例脚本可直接调包:
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n.yaml") # build a new model from scratch
model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Use the model
model.train(data="coco128.yaml", epochs=3) # train the model
metrics = model.val() # evaluate model performance on the validation set
#results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
#success = model.export(format="onnx") # export the model to ONNX format
方式二、在本项目目录下,针对V8检测器,可以这样使用
if use python ,you need set your data and model path in cfg/default.yaml,同样也可以直接通过代码脚本启动或者自己构建脚本启动。
需要你进入到cfg/default.yaml中去配置你的参数,比如模型、数据等路径以及超参数。 【在每一个detect/segmen/clss的目录下都会有脚本】
python train_v8.py
因为官方V8提供了全新的命令,设计一套yolo的命令格式,方式很简单就是现在最流行的低代码设计,降低使用者门槛。
通过yolo task… model=… arg=… 的格式启动所有任务
Feature ——概述
这种创新点其实老生常谈了,如果你是从21年看我偶尔随写的YOLO修改博客的话,对于算子、结构、LOSS样本匹配的思路应该比较熟悉了,可以看到V8版本在官方GIT上展示出了基于COCO性能的比对
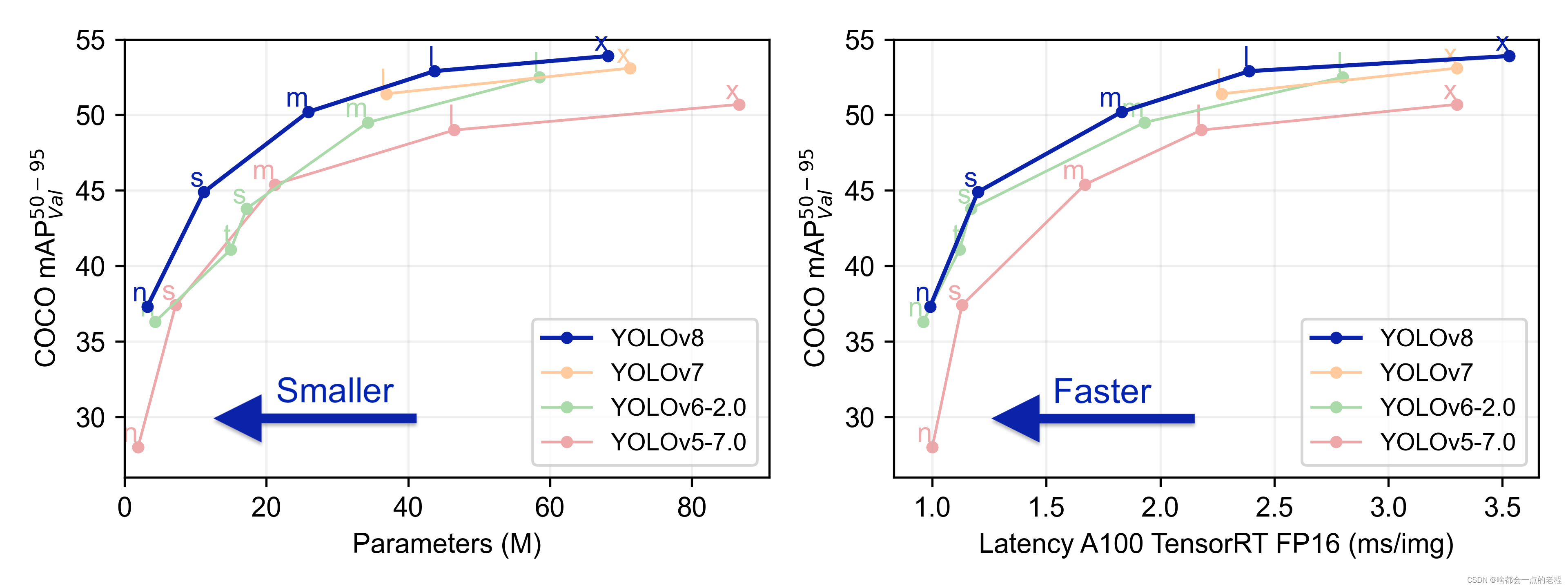
左图展示在COCO数据验证集上的性能指标,说明在精度提升的同时带来了参数量的提升,在常规尺度的n/s/M的模型上参数量增加;
右图展示在COCO数据验证集上Tensorrt的性能指标,A100 显卡上FP16精度推理下的速度展示,总之可以看出V8精度更高,但是相对V5来说牺牲了部分推理速度,但是在如今检测器部署泛滥的年代,这样的速度差异倒是可以忽略。
另外插一句,不知道大家有没有近两年的检测项目,包含V5-6.0版本开始已经不满足于检测,(去年我记得我把顺着V7官方推荐的V5_pose开源版本的关键点检测加进我GIt的那天,转到V5仓库习惯性看看V5作者的commit的时候,他就发出来分割代码了,当时就感觉不谋而合 )是经典的基础视觉任务“通杀”的工程化模型,还有开箱即用的Tensorrt等部署代码的工具都是清一色标配,这也能从侧面反应检测、分类、分割等High-level经典任务算法和技术上已经趋于瓶颈,又来说这个了,没办法,因为去年接触过不少跨领域的东西,感觉目前业界做CV除了纯科研产出论文等,只做检测或者只研究检测远远不够!话呢说回来,基础还是要打好,所以多兼顾就要多牺牲时间,做CV越来越累也正常,V8这次的出现褒贬不一,不管是质疑SOTA技巧的缝合还是泛化性的不足也好,终归也有我们学习的点。
下面,我会尽量详细对于V8版本的一些新变化,原理和代码等做出一些分析展示把,可能短期难以更完,因为最近很多工程要做,尽快完成更新,并且我也会额外写出一个如何把V8代码嵌进各位自己修改V5代码中(很多读者是自己在V5上做改进后适应了自己任务的特定数据集,那么直接引入V8核心部分的程序使用可能会更方便),简单规划总结下,我心中V8的一些核心改动特色。
1. 性能提升并在检测、分类、分割三线任务中加入了最新的跟踪bytetrack等方法。
2. 模型结构变化:核心算子块C3变成C2F,由于增加了不少次shortcut,在深层模型中梯度的问题得到缓解同时,可能有利用特征重用; head 部分沿用之前的解耦头,取消掉了objectnetss分支,使用了经典魔改利器之一的Distribution Focal
Loss,以卷积和softmax替代积分表示BOX,需要进行解码转换,Anchor-free取消了先验anchor部分,且提供了v5u的一系列anchorfree的V5、v8模型结构。
3. 训练部分 :核心样本匹配策略改为动态匹配Taskaligened分配机制区分正负样本
4. 额外的工程化代码改动和pip安装的YOLO命令格式
一、yolov8改动详解
1. 网络结构
相信关注的人已经大致知道了v8网络结构的变动,这里分别讲一下我的个人理解 ,先以下面v8yaml结构开始。
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2 ##卷积核尺寸从6变成了3 这个改动相比于个人认为只是降低了参数量
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3 #Neck部分删掉了2个卷积层
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
1.1 关于整体修改和C2F定义和理解:
class C2f(nn.Module):
# CSP Bottleneck with 2 convolutions
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m) # 压入了N个bottlenneck
return self.cv2(torch.cat(y, 1))
个人理解:
我们从上面C2F的代码定义看出,在C2F中首先以input_tensor(n,c,h,w)经过cv1层进行了split拆分,分成各自一半(n,0.5c,h,w),一半直接经过N个Bottlenck,其余经过每一操作层后都会以(n,0.5c,h,w)size的tensor进行Shortcut,最后通过CV2层卷积输出。也就是对应N+2的shorcut(第一次层cv1的分支tensor和split后的tensor为2+N个bottenlenneck).
这种做法是压缩之前的模型结构,从以上两处结合前面对V8总体性能综合评估,这个改动的核心思路个人认为,是保证在性能不变或者提升的情况下,对模型结构进行了极致的压缩,降低了网络的参数量和模型复杂度。也许推理速度并没有质变,但是但从GFLOPs上同比V5已经降低了很多(FLOPs低不代表推理就一定成正比快,但是这种通用模型一般还是优先考虑FLOPs的),感兴趣的朋友可以自己运行对比一下(比如V5n和V8N的,GFLOPs降低约2倍)。
如今的检测模块结构基本都是从resnet\densenet的思路演变至今的,因为shorcut能够保证模型的性能,不会因为深度问题造成退化,增多Shortcut能够带来更多的梯度传导,这也是CNN的基本设计范式,但是过多的shortcut确实会降低部署的推理速度,所以作者构建这样的模型,同时将模型结构的C2F Block数(V5的C3为3/6/9/3)改成了3-6-6-3以及neck的小精简,这些操作个人认为算是从设计上降低模型参数量和复杂度。试想如果你不做这些那么模型的shortcur和层数的增多,那么速度相比V5会有明显的下降,也违背了YOLO的核心宗旨,那就是“快和准的balance”。现在的检测器设计其实更多是实验和调试,相信作者下了不少功夫。
所以,回过头来再看大多数的操作都是在考虑Flops和深层性能优化的前提下进行了“压缩”,平衡了速度。
另外补充下,除了骨干和NECK的微调,新的V8对模型宽和高的比例进行了微调如下:
n: [0.33, 0.25, 1024]
s: [0.33, 0.50, 1024]
m: [0.67, 0.75, 768]
l: [1.00, 1.00, 512]
x: [1.00, 1.25, 512]
1.2 yolov8 head 变动以及anchor-free解析
V8的head是解耦头,这部分工作是随着近两年如YOLOX的检测器推出后,提升性能的一种设计策略,早期我使用了类似YOLOX的解耦头,确实消融比对训练Map提了一到两个点(visdrone数据集),但head复杂度提升随之参数量上去了。在去年V5仓库中同样发现作者自己改了一个相对轻量化的检测解耦头(关于为什么要解耦的这个问题老生常谈了,需要详细解释的看往期文章即可,是为了缓解检测和回归的"Missaligned"),去年在一次更新中也发现了V5作者也同样进行了相关的改进实验,他给的解耦头”较轻“,将默认的dcoupled head置为v5官方版本,前者我觉得并不是一个好的结果,但是后者我没并没有进行过实验。
既然提到了解耦头,顺便对比下,这里是我仓库的代码,因为兼容了V8,所以区分开需要重新命名和构建解析部分的代码。
class V8_Detect(nn.Module):
# YOLOv8 Detect head for detection models
dynamic = False # force grid reconstruction
export = False # export mode
shape = None
anchors = torch.empty(0) # init
strides = torch.empty(0) # init
def __init__(self, nc=80, ch=()): # detection layer
super().__init__()
self.nc = nc # number of classes
self.nl = len(ch) # number of detection layers
self.reg_max = 16 # DFL channels (ch[0] // 16 to scale 4/8/12/16/20 for n/s/m/l/x) #该参数支持最大20倍下采样
self.no = nc + self.reg_max * 4 # number of outputs per anchor
self.stride = torch.zeros(self.nl) # strides computed during build
c2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], self.nc) # channels 以16为最小值确定两个分支的划分通道数
self.cv2 = nn.ModuleList(
nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch) # 回归分支
self.cv3 = nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch) # 分类分支
self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()
def forward(self, x):
shape = x[0].shape # BCHW
for i in range(self.nl):
x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1) #合并两分支tensor
if self.training: #训练阶段直接返回tensor#
return x
elif self.dynamic or self.shape != shape:
self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5)) #传入【8.16.32】三个下采样步长取生成anchor,确定anchors和步长
self.shape = shape
box, cls = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2).split((self.reg_max * 4, self.nc), 1) ##按上述C2,C3定义切分出双分支的tensor
dbox = dist2bbox(self.dfl(box), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.strides #解码DFL的输出,转成XYWH形式的BOX输出
y = torch.cat((dbox, cls.sigmoid()), 1) #拼接一起结果返回
return y if self.export else (y, x)
yolov5的基础版本不是解耦头,所以这里用V5提供的解耦头作对比,这里V5的检测头不管是解耦与否本质区别还是基于是否存在anchor机制,首先总结一下:
| yolov5 head | yolov8 head |
|---|---|
| 解耦(支持) | 解耦(默认) |
| anchor-base,先验设计 | anchor-free,动态生成 |
| 输出:(xywh+Classnums)*3(尺度层数,anchors)+OBJ置信度 | 输出:(classnums+reg_max(16)*4(ltrb),reg_max为BOX回归超参数 |
另外anchor-free的BOX的表示一般是(l,t,r,b),算是距离信息,如图:

通过阅读上述代码注释和表格,相信有了大致了解,如果不够详细,那么再来遍文字叙述补充:
熟悉YOLO系列的朋友都知道,网络预测的一直都是偏移量,self.reg_max是一个超参数,它涉及到BOX回归计算以及anchor网格(一般最新下采样后卷积的featuremap不能超过16像素大小,因此self.reg_max设置为16,如果输入过大需要自己设计,后面也会提到和dfl的输出有关),在实际区别中,anchor-base在yaml中是有anchor的,反之则没有,而anchor-free的head部分首先需要生成anchor点,代码如下
def make_anchors(feats, strides, grid_cell_offset=0.5):#根据featuremap和strides
"""Generate anchors from features."""
anchor_points, stride_tensor = [], [] #初始化一个空列表用于存储anchor点和步长张量。
assert feats is not None
dtype, device = feats[0].dtype, feats[0].device
for i, stride in enumerate(strides): #随着每层下采样,V8模型默认21层
_, _, h, w = feats[i].shape
#创建一个偏移后的x和y坐标网格,并加上网格单元偏移量,网格单元偏移量为步长值一半grid_cell_offset=0.5
sx = torch.arange(end=w, device=device, dtype=dtype) + grid_cell_offset # shift x
sy = torch.arange(end=h, device=device, dtype=dtype) + grid_cell_offset # shift y
sy, sx = torch.meshgrid(sy, sx, indexing='ij') if TORCH_1_10 else torch.meshgrid(sy, sx)
anchor_points.append(torch.stack((sx, sy), -1).view(-1, 2))
stride_tensor.append(torch.full((h * w, 1), stride, dtype=dtype, device=device))
return torch.cat(anchor_points), torch.cat(stride_tensor)
def dist2bbox(distance, anchor_points, xywh=True, dim=-1): '''distance:为Dfl输出的结果,代表anchors中心点的距离值,根据距离值转换BOX坐标'''
"""Transform distance(ltrb) to box(xywh or xyxy)."""
lt, rb = torch.split(distance, 2, dim) '''分别取出lt,rb的距离对值'''
x1y1 = anchor_points - lt #计算坐标
x2y2 = anchor_points + rb
if xywh: ##bOX 格式转换
c_xy = (x1y1 + x2y2) / 2
wh = x2y2 - x1y1
return torch.cat((c_xy, wh), dim) # xywh bbox
return torch.cat((x1y1, x2y2), dim) # xyxy bbox
而这里比较特殊的就是在推理中最后一步是distribution Foal loss的一个卷积层,DFL是一个比较经典的LOSS设计,这里简单提一下吧,完全没了解过的自行网上查阅即可,比较成熟了我就简而言之。
1.2.1 理解DFL设计思路
首先你要知道为什么需要DFL?这里引用了GFL的思想。
答:为了优化BBOX回归的准确性问题——坐标回归一般被认为是极端离散分布,狄拉克分布只存在GT值,通常来说这种hard-one hot做法不利于模型的表现,即实际在真实场景下的表现具有很强的不确定性,可解释为你的bbox边界划的不够准确。因此DFL使用交叉熵函数去改变分布,使得单值更改成输出n+1个值,每个值表示对应回归距离的概率,然后利用积分获得最终的回归距离。其主要是将框的位置建模成一个general distribution,让网络快速的聚焦于和目标位置距离近的位置的分布。
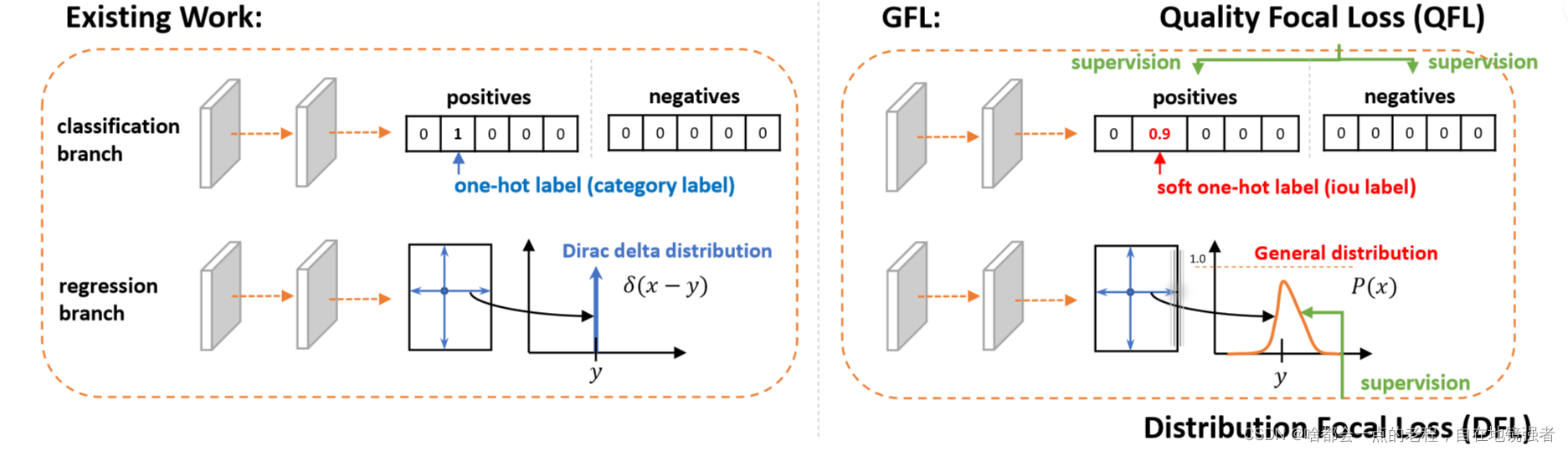
类比于heat-map的高斯滤波改进思想是一样的,我个人称之为"Hard to Soft"思路。
进一步的GFLV2版本额外提供了一个BOX的质量估计的统计分布,来表达定位质量,每个head提供TOPK的分布,最后作为分类分支的权重系数去判断。
那么继续回到YOLOV8的解析中来,DFL的公式和代码如下:
class DFL(nn.Module): ##将DFL一个求数学期望的表达,使用卷积conv去实现
# Integral module of Distribution Focal Loss (DFL) proposed in Generalized Focal Loss https://ieeexplore.ieee.org/document/9792391
def __init__(self, c1=16):
super().__init__()
self.conv = nn.Conv2d(c1, 1, 1, bias=False).requires_grad_(False)
x = torch.arange(c1, dtype=torch.float)
self.conv.weight.data[:] = nn.Parameter(x.view(1, c1, 1, 1))
self.c1 = c1
def forward(self, x):
b, c, a = x.shape # batch, channels, anchors
return self.conv(x.view(b, 4, self.c1, a).transpose(2, 1).softmax(1)).view(b, 4, a)
原版的DFL中:
论文对coco数据进行统计,发现回归距离分布在0-16之间,假设把0-16的regression target看作一个多分类问题,pred就是多分类的预测值,首先使用softmax将x归一化。
在v8的版本中,使用如下计算替代积:通过一个1x1卷积相当于全连接,停止了参数更新,初始化了16个距离分布范围,经过softmax归一化reshape输出[1,4,21],分别代表batchsize,ltrb四个举例子,anchors层,21应该是21个下采样层的数量,也就是大家认为的4Dbox格式。
再度说下C1=16,是因为在V8head的代码注释中“// 16 to scale 4/8/12/16/20 for n/s/m/l/x) “出现过解释,如果你的输入图像经过下采样后像素超过了设定的16,那么dfl的卷积操作就会出现计算问题,所以这个值算是一个超参数,需要根据需求去调节。在程序中最大下采样为20倍,所以不会越过该阈值,这和自己的需求和数据集相关。
做个总结,本节head解析部分就解释了,个人比较看重的是:"Hard to Soft 的思想 ",从数学角度,离散分布转化为连续分布,这种思路是在任何深度学习设计中都会出现的,bbox预测高斯分布化也符合中心极限定理的支持;从个人经验角度,head的预测结合了loss和样本匹配机制,在实际实验中很可能作soft的思路在实验表现中相对来说召回率会高,做研究的都能Get到,这种做法在数据集的MAP上一般会有所优势,常规表现为可能检测的置信度相对会低,最后再回来讨论DFL的作用,除缓解BBOX的定位问题,同时某种某种上起到和解耦一致的作用,缓解分类和回归的"MissAligned"问题。
先更到这里我会继续更新,感兴趣的可以先MARK!(最近在落地一些事情,更新较慢读者见谅)
2.LOSS以及样本匹配策略
通过阅读源码,我做在项目中添加了注释,具体细节可以看这个代码:loss函数匹配代码
这里分为”三步走“,总结下流程:
1. 第一步, 输入模型预测值(预测的anchors点,置信度,预测bbox,g t-label,gt-box边界框,mask_gt),得到正样本掩码、匹配度、IOU。
mask_gt
对mask_gt解释:
将 gt_bboxes 按照 axis=2 求和,得到一组值,如果这些值大于0,说明该边界框存在,应计算其损失值,因此将其标记为 True,否则标记为 False,不参与计算通过
mask_gt 来过滤掉那些不需要计算损失的边界框,提高计算效率。
那么如何计算这些输出值呢?让我们来看下面核心代码,主要完成两件事:
- 计算匹配度和IOU:简单来说,就是会遍历计算每个网格内的预测bbox和GT的CIOU,通过预测分数*CIOU的结果作为度量值。
- 计算正样本Mask:是通过bbox坐标和真实框的位置信息,在所有anchor中选择位于GTbox真实框内部或者与其IoU大于阈值的anchor点,mask_in_gts逻辑掩码(每个GT-bbox内的所有anchor点是否落在目标框内部,其中1表示在目标框内,0表示在目标框外。)
这里值得一提的是,所有遍历计算中中,作者用roll_out 策略时:
在计算匹配度中,只计算那些被标签所覆盖的边框与 GT 之间的 CIoU,减少了计算量
而对于那些不被 ground truth 标签所覆盖的边框,将被舍弃,避免计算冗余和过多内存消耗,这种方式主要是减少tensor计算显存消耗
在计算正样本anchor时候,按batch循环计算,就是时间和空间balance的策略。
2. 第二步,根据第一步中得到的所有计算值, 选择目标bbox中分值排名前k个的anchor点,具体为:
-
根据匹配度量值取TOP K的anchor点,表示前k个anchor点的分数和索引。
-
然后将索引对应于传入的掩码topk_mask矩阵,选出前k个anchor点所对应的掩码,将未被选中的掩码置为0,这样完成了一个正样本前K个的掩码masktopk.
-
将所有掩码合并到一个最终掩码中,形状为(b, max_num_obj, h*w)。最终掩码是通过将三个掩码mask_topk、mask_in_gts和mask_gt相乘得到的。
3. 第三步,通过上述获取到了正样本mask,然后select_highest_overlaps
- 解决一个anchor和多个GT框匹配问题,先找到一个anchor匹配多个GT的MASK矩阵,只选择与当前anchor的最大IOU的gt-box.
- 根据分配给每个anchor box的gt_box,得到其对应的目标类别、目标框和目标分数。最终,target_scores = target_scores * norm_align_metric ,归一化度量值,得到归一化的目标置信度。
以上是TaskAligned 的样本定义匹配过程,代码是作者从PPYOLOE参考的,其算法思路来源于ICCV 2021——TOOD: Task-aligned One-stage Object Detection的样本匹配机制。
















 1393
1393











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









