






LLM偏好对齐训练技术——ORPO【全网首发:15分钟代码和原理速通】
前言
(本来写好了的,延迟4月清明节后发)
从RLHF到DPO,偏好对齐一直是chat模型“智能化”的强化训练方式,RLHF本人使用次数很少,因为训练成本太高且在我接触这个方案的时候已经有了dpo的方法,DPO一般作为大模型chat的第三阶段训练(PT\SFT)后的强化训练,目的是为了对齐符合人类偏好的回答,使得模型更”人性智能化“,DPO要通过SFT的模型和偏好数据集进行直接偏好回归优化的训练,不需要像RLHF一样通过训练RM模型再进行PPO优化训练,所以DPO从2023年下半年到目前为止都是模型提升性能的一个关键重要训练方式(事实上还有IPO\KTO,但DPO的方式综合起来更稳定),不论模型架构,你可以看在HF的开源模型排行榜很多都是经过sft\dpo提升的能力,还有之前的Zephyr通过Mistral作的sft+偏好数据收集+DPO,(在年初动态中提过,随着mixtral 、deepseek MOE架构发布时候说过MOE架构会同样会席卷一波,目前的QWEN也出了小尺度的MOE架构)包含现在的QWEN1.5系列也是通过dpo的方式去完成优化训练。今天我们来讲一种较DPO更简洁的偏好对齐训练方法Odds Ratio Preference Optimization (ORPO),也就是在SFT过程中完成偏好对齐。
一 、 ORPO(Odds Ratio Preference Optimization)
具体论文实验验证的结论图表,这里不作分析,可以看论文
论文通过一些实验得出了这个理论的可行性
展示了 ORPO 在单轮和多轮指令遵循任务中的效果。
比较了 ORPO 与其他偏好对齐方法的胜率。
讨论了 ORPO 在词汇多样性方面的表现。
提供了 ORPO 梯度的推导、概率比和赔率比的消融研究、实验细节、IFEval 结果、不同权重值 λ 的影响、HH-RLHF
数据集上的奖励分布测试以及 Mistral-ORPO-α (7B) 和 Mistral-ORPO-β (7B) 在 MT-Bench
上的结果。
论文链接
论文中总结的ORPO优势:
在偏好对齐的背景下,SFT不仅用于领域适应性,还用于提高模型对人类偏好的理解。通过微调模型以生成与人类偏好相符的响应,SFT有助于减少有害或不期望的输出。
稳定更新:
在强化学习中,SFT常用于确保活动策略(active policy)相对于旧策略(old policy)的稳定更新。在RLHF中,在PPO迭代中,SFT模型作为旧策略,有助于在训练过程中保持稳定性。而DPO则是通过数据去直接优化的,ORPO也是如此。
避免不良生成风格:
SFT过程中,如果不加以控制,可能会增加生成不受欢迎风格文本的可能性。ORPO通过在SFT中引入赔率比损失来解决这个问题,从而在提高领域适应性的同时,避免学习到不良的生成风格。这点你如果做过SFT就会发现,因为SFT不同尺度的模型对数据集的质量和数量都存在比较高的要求,表现为你会发现有时候你的指令答案并不是按你所训练的预想去回答。
效率和性能:
论文强调了SFT在提高算法效率和性能方面的重要性。通过直接在SFT中整合偏好对齐,ORPO能够以更少的计算资源和训练步骤达到有效的偏好对齐。
单步对齐,无需额外参考模型:
ORPO方法的一个创新之处是它不需要额外的参考模型来进行偏好对齐。这与传统的偏好对齐方法不同,后者通常需要一个参考模型来生成被拒绝的响应。SFT在ORPO中起到了核心作用,使得模型可以直接在训练数据上进行偏好学习。
总之,SFT在ORPO算法中的作用是多方面的,它不仅提高了模型对特定任务的适应性,还通过结合赔率比损失来引导模型学习人类的偏好,同时避免了不良生成风格的学习,并提高了训练过程的效率和性能。
接下来让我们看下ORPO具体如何实现。
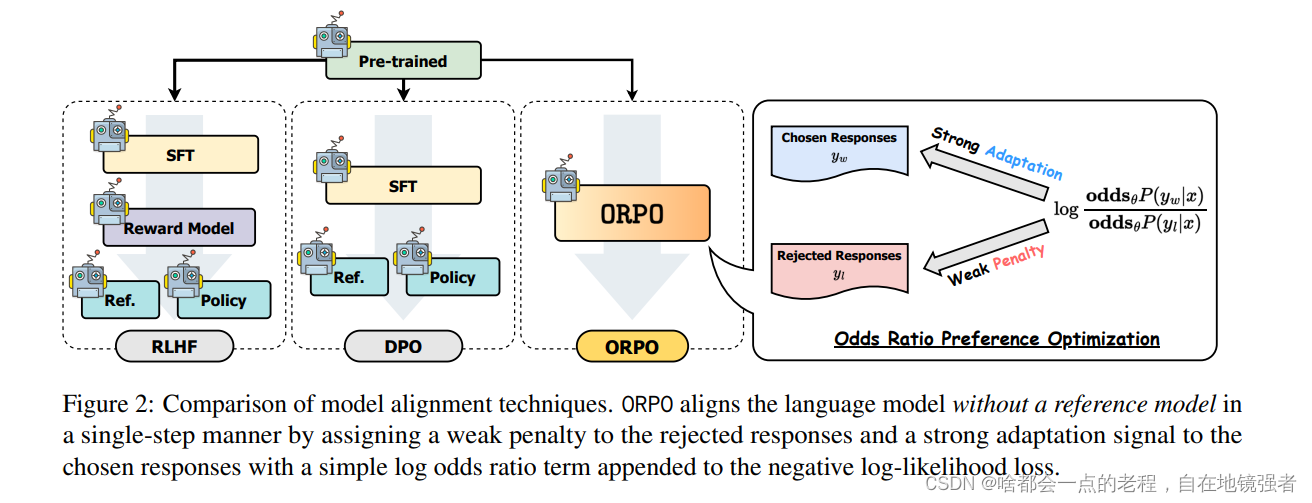
从上图中我们可以看出ORPO相较于RLHF\DPO的简洁步骤,那么我们接下来分析ORPO几个创新点具体的每一步如何实现
1.赔率比(Log Odds Ratio Term)以及LOSS函数
ORPO引进了赔率比,用来比较两个事件发生的概率比。在ORPO中,它用来比较生成更符合人类偏好响应和被拒绝响应的概率。
赔率比具有数学上的稳定性和敏感性(在常用的负对数似然损失(negative log-likelihood loss)中加入了一个简单的赔率比项。这个赔率比项是基于对数赔率的),使其成为在SFT(Supervised Fine-tuning)中结合偏好对齐的理想选择。
公式如下:
ORθ(yw,yl)= odds_theta(yw∣x) / odds_theta(yl∣x),给定x输出y的概率
Loss函数LOR:
LOR=−logσ( log(odds_theta(yw∣x)/1-odds_theta(yw∣x))−log(odds_theta(yl∣x)/1-odds_theta(yl∣x)/),σ 是sigmoid函数,最大化差异数值=最小化目标函数。
2.强适应和弱惩罚
从上结构图中,看出,
强适应:通常是通过最小化负对数似然损失(Negative Log-Likelihood Loss, NLL)来完成的,该损失函数鼓励模型提高对正确或期望输出的预测准确性。在训练过程中,模型会接收到一个强信号,表明它应该优先生成与训练数据中的正面示例相匹配的响应。
弱惩罚:在损失函数中加入基于赔率比的惩罚项。这样做的目的是让模型知道避免生成这些类型的响应,但同时不会过于强烈地抑制模型的探索能力
3.组合损失函数
借此,ORPO的损失函数也就清晰了,即:Loss(orpo)=L SFT+λ⋅L OR, 通用的SFT损失和相对比率损失LOR(λ比例因子)两部分组成。
这也是整个ORPO训练的核心部分。
二、ORPO代码
1.核心代码
按照上节步骤叙述有(ORPO官方实现已经添加到TRL库),trl-orpo
offical ORPO github
关键核心代码如下:
def odds_ratio_loss(self, chosen_logps: "torch.Tensor", rejected_logps: "torch.Tensor") -> "torch.Tensor":
r"""
Computes ORPO's odds ratio (OR) loss.
"""
# 1.计算两种对数概率差减去其赔率比的差
log_odds = (chosen_logps - rejected_logps) - (
torch.log1p(-torch.exp(chosen_logps)) - torch.log1p(-torch.exp(rejected_logps))
)
# 2. 用sigmoid函数并取负值来构造损失,最大化差异数值,就是最小化这个LOSS
odds_ratio_loss = -F.logsigmoid(log_odds)
return odds_ratio_loss
def forward(
self, model: "PreTrainedModel", batch: Dict[str, "torch.Tensor"]
) -> Tuple["torch.Tensor", "torch.Tensor", "torch.Tensor", "torch.Tensor"]:
r"""
Computes the average log probabilities of the labels under the given logits.
"""
#模型未标准化的分数输出
all_logits: "torch.Tensor" = model(
input_ids=batch["input_ids"], attention_mask=batch["attention_mask"], return_dict=True
).logits.to(torch.float32)
all_logps = self.get_batch_logps( # Concatenate the chosen and rejected inputs into a single tensor. 该函数源于trl, https://github.com/huggingface/trl/blob/main/trl/trainer/orpo_trainer.py
logits=all_logits,
labels=batch["labels"],
average_log_prob=True,
is_encoder_decoder=self.is_encoder_decoder,
label_pad_token_id=self.label_pad_token_id,
)
batch_size = batch["input_ids"].size(0) // 2 # 批次分成两部分:选中样本和被拒绝样本
chosen_logps, rejected_logps = all_logps.split(batch_size, dim=0)
chosen_logits, rejected_logits = all_logits.split(batch_size, dim=0)
# 分离得到选中样本和被拒绝样本的对数概率以及logits。
return chosen_logps, rejected_logps, chosen_logits, rejected_logits
def get_batch_loss_metrics(
self,
model: "PreTrainedModel",
batch: Dict[str, "torch.Tensor"],
train_eval: Literal["train", "eval"] = "train",
) -> Tuple["torch.Tensor", Dict[str, "torch.Tensor"]]:
r"""
Computes the ORPO loss and other metrics for the given batch of inputs for train or test.
"""
metrics = {}
# Compute the log probabilities of the given labels under the given logits.,此代码的函数来源于trl的源码,form https://github.com/huggingface/trl/blob/main/trl/trainer/orpo_trainer.py
chosen_logps, rejected_logps, chosen_logits, rejected_logits = self.forward(model, batch) #偏好、拒绝的对数概率和原始概率 ,
sft_loss = -chosen_logps #使用偏好的负数作sft loss
odds_ratio_loss = self.odds_ratio_loss(chosen_logps, rejected_logps) #计算赔率Loss
batch_loss = (sft_loss + self.beta * odds_ratio_loss).mean() ##加权sft和orpo的赔率Loss
chosen_rewards = self.beta * chosen_logps.detach() #计算偏好响应奖励,detach分离后主要保证:奖励或者拒绝的计算不会影响到训练的参数更新
rejected_rewards = self.beta * rejected_logps.detach() #计算拒绝响应奖励,同上
reward_accuracies = (chosen_rewards > rejected_rewards).float() #判断偏好奖励响应是否大于拒绝响应
prefix = "eval_" if train_eval == "eval" else ""
metrics["{}rewards/chosen".format(prefix)] = chosen_rewards.cpu().mean()
metrics["{}rewards/rejected".format(prefix)] = rejected_rewards.cpu().mean()
metrics["{}rewards/accuracies".format(prefix)] = reward_accuracies.cpu().mean()
metrics["{}rewards/margins".format(prefix)] = (chosen_rewards - rejected_rewards).cpu().mean()
metrics["{}logps/rejected".format(prefix)] = rejected_logps.detach().cpu().mean()
metrics["{}logps/chosen".format(prefix)] = chosen_logps.detach().cpu().mean()
metrics["{}logits/rejected".format(prefix)] = rejected_logits.detach().cpu().mean()
metrics["{}logits/chosen".format(prefix)] = chosen_logits.detach().cpu().mean()
metrics["{}sft_loss".format(prefix)] = sft_loss.detach().cpu().mean()
metrics["{}odds_ratio_loss".format(prefix)] = odds_ratio_loss.detach().cpu().mean()
return batch_loss, metrics
2.数据集
偏好数据集格式都一样,这里用alpaca和sharegpt格式举例:
alpaca
[{
“instruction”: “user instruction”, #用户指令
“input”: “user input”, #用户输入
“output”: [
“chosen answer”, #偏好回答,首选答案
“rejected answer” # 拒绝的回答
]
“system”: “system prompt (optional)”,
“history”: [ “histroy question and answer”
]
}]
sharegpt:
[
{
“conversations”: [
{
“from”: “human”,
“value”: “user instruction”
},
{
“from”: “gpt”,
“value”: “model response”
}
],
“system”: “system prompt (optional)”,
“tools”: “tool description (optional)”
}
]
总结
ORPO近几个月最新的一种强化偏好的训练方法,之前在TRL库中还有KTO.IPO等改进的人类偏好学习算法,但是DPO目前是工业界广泛使用的强化训练方式,ORPO能否取代还是要根据更多的实验证明,毕竟这种成本更低的实现会更有利于降低LLM的训练门槛。
















 54
54











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









